 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning an offline reinforcement learning objective from scratch
Jan 30, 2023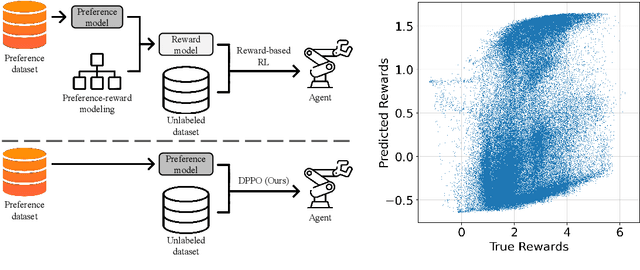
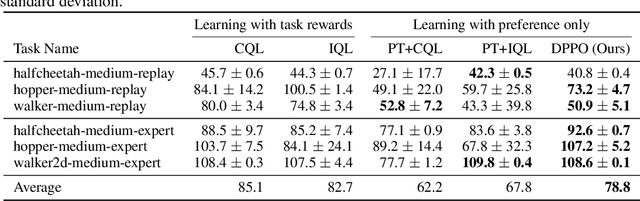
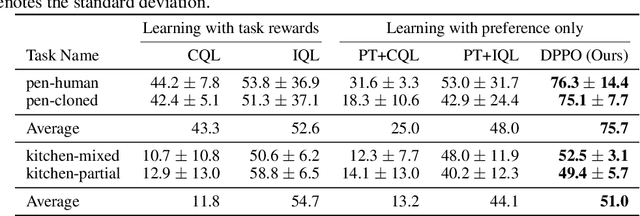
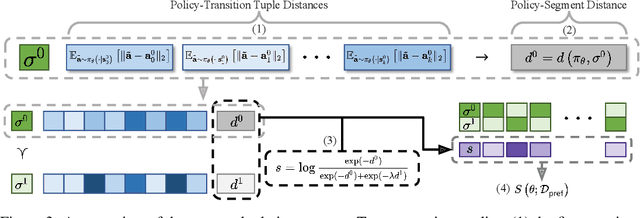
Offline reinforcement learning has developed rapidly over the recent years, but estimating the actual performance of offline policies still remains a challenge. We propose a scoring metric for offline policies that highly correlates with actual policy performance and can be directly used for offline policy optimization in a supervised manner. To achieve this, we leverage the contrastive learning framework to design a scoring metric that gives high scores to policies that imitate the actions yielding relatively high returns while avoiding those yielding relatively low returns. Our experiments show that 1) our scoring metric is able to more accurately rank offline policies and 2) the policies optimized using our metric show high performance on various offline reinforcement learning benchmarks. Notably, our algorithm has a much lower network capacity requirement for the policy network compared to other supervised learning-based methods and also does not need any additional networks such as a Q-network.
Optimal channel selection with discrete QCQP
Feb 24, 2022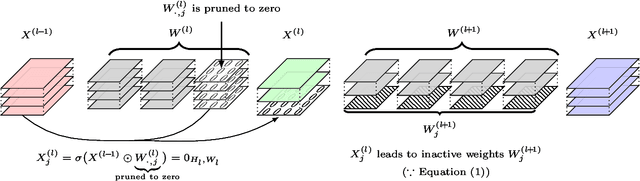

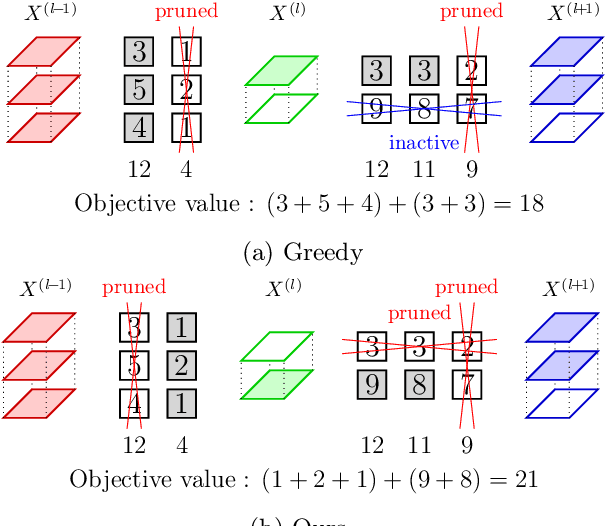
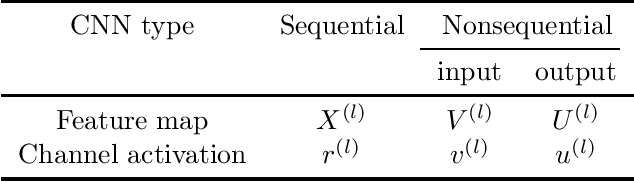
Reducing the high computational cost of large convolutional neural networks is crucial when deploying the networks to resource-constrained environments. We first show the greedy approach of recent channel pruning methods ignores the inherent quadratic coupling between channels in the neighboring layers and cannot safely remove inactive weights during the pruning procedure. Furthermore, due to these inactive weights, the greedy methods cannot guarantee to satisfy the given resource constraints and deviate with the true objective. In this regard, we propose a novel channel selection method that optimally selects channels via discrete QCQP, which provably prevents any inactive weights and guarantees to meet the resource constraints tightly in terms of FLOPs, memory usage, and network size. We also propose a quadratic model that accurately estimates the actual inference time of the pruned network, which allows us to adopt inference time as a resource constraint option. Furthermore, we generalize our method to extend the selection granularity beyond channels and handle non-sequential connections. Our experiments on CIFAR-10 and ImageNet show our proposed pruning method outperforms other fixed-importance channel pruning methods on various network architectures.
Preemptive Image Robustification for Protecting Users against Man-in-the-Middle Adversarial Attacks
Dec 10, 2021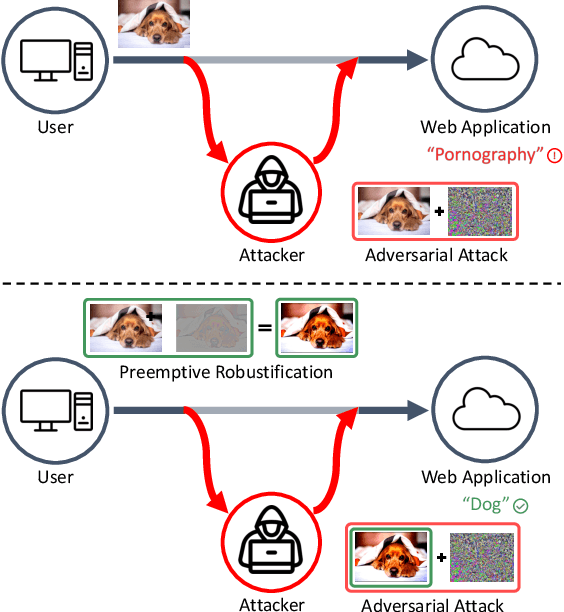
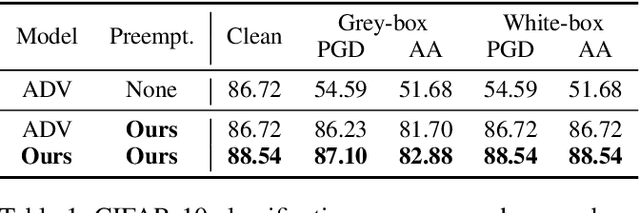
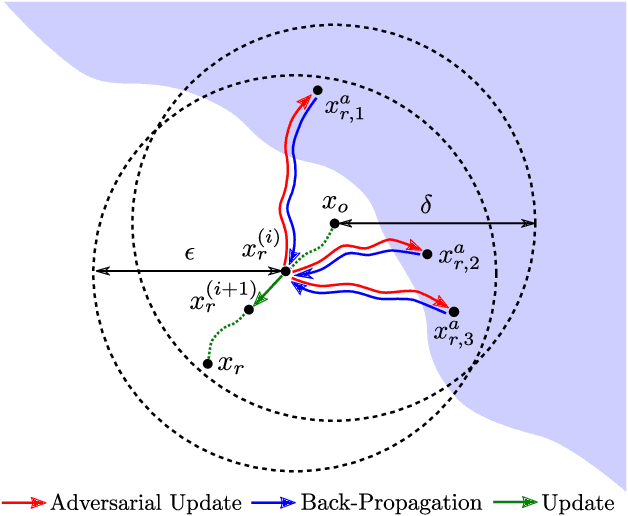
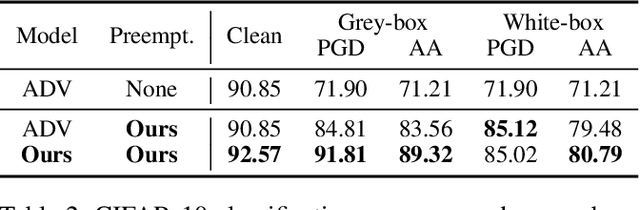
Deep neural networks have become the driving force of modern image recognition systems. However, the vulnerability of neural networks against adversarial attacks poses a serious threat to the people affected by these systems. In this paper, we focus on a real-world threat model where a Man-in-the-Middle adversary maliciously intercepts and perturbs images web users upload online. This type of attack can raise severe ethical concerns on top of simple performance degradation. To prevent this attack, we devise a novel bi-level optimization algorithm that finds points in the vicinity of natural images that are robust to adversarial perturbations. Experiments on CIFAR-10 and ImageNet show our method can effectively robustify natural images within the given modification budget. We also show the proposed method can improve robustness when jointly used with randomized smoothing.
Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble
Oct 05, 2021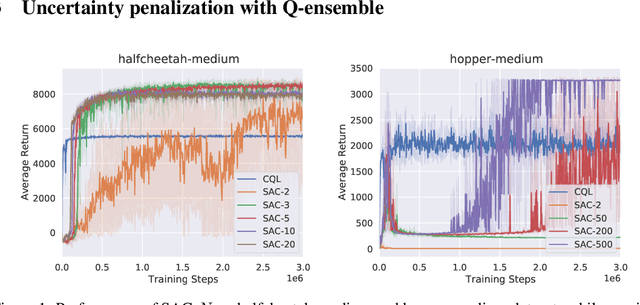
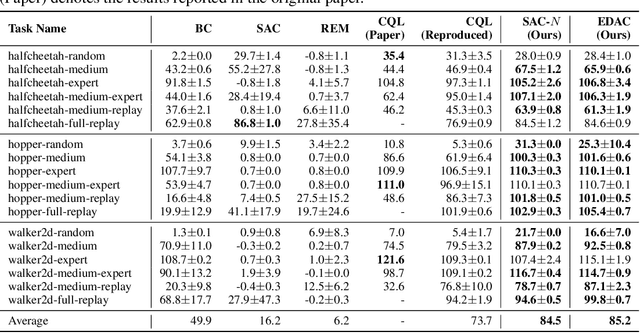
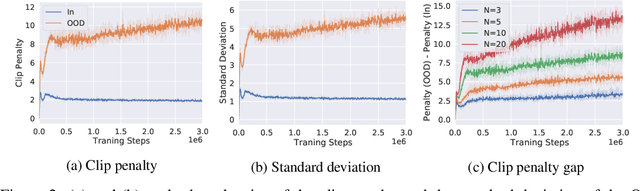
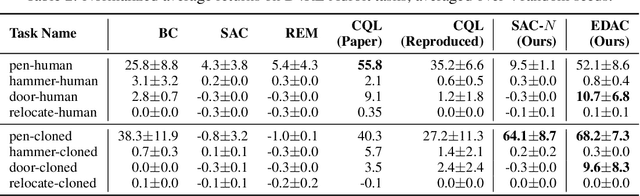
Offline reinforcement learning (offline RL), which aims to find an optimal policy from a previously collected static dataset, bears algorithmic difficulties due to function approximation errors from out-of-distribution (OOD) data points. To this end, offline RL algorithms adopt either a constraint or a penalty term that explicitly guides the policy to stay close to the given dataset. However, prior methods typically require accurate estimation of the behavior policy or sampling from OOD data points, which themselves can be a non-trivial problem. Moreover, these methods under-utilize the generalization ability of deep neural networks and often fall into suboptimal solutions too close to the given dataset. In this work, we propose an uncertainty-based offline RL method that takes into account the confidence of the Q-value prediction and does not require any estimation or sampling of the data distribution. We show that the clipped Q-learning, a technique widely used in online RL, can be leveraged to successfully penalize OOD data points with high prediction uncertainties. Surprisingly, we find that it is possible to substantially outperform existing offline RL methods on various tasks by simply increasing the number of Q-networks along with the clipped Q-learning. Based on this observation, we propose an ensemble-diversified actor-critic algorithm that reduces the number of required ensemble networks down to a tenth compared to the naive ensemble while achieving state-of-the-art performance on most of the D4RL benchmarks considered.
Parsimonious Black-Box Adversarial Attacks via Efficient Combinatorial Optimization
May 16, 2019
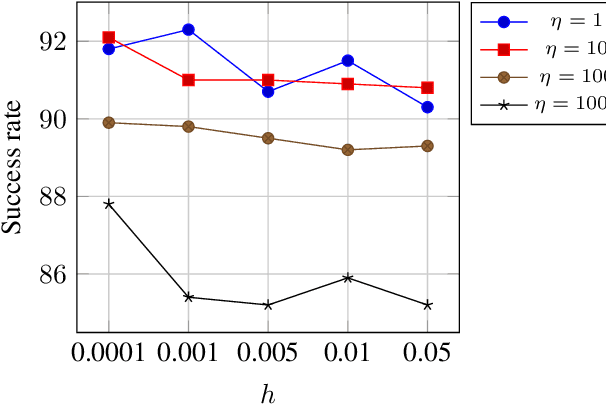

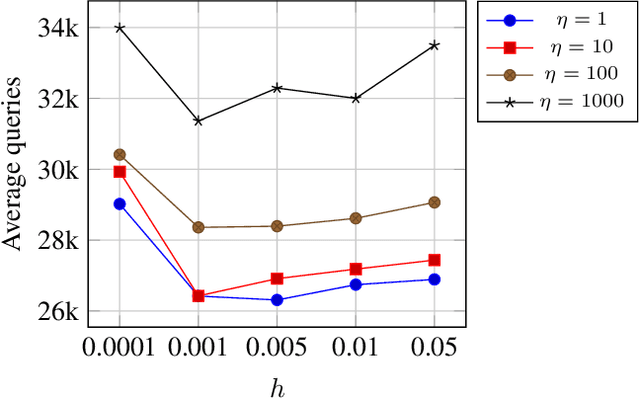
Solving for adversarial examples with projected gradient descent has been demonstrated to be highly effective in fooling the neural network based classifiers. However, in the black-box setting, the attacker is limited only to the query access to the network and solving for a successful adversarial example becomes much more difficult. To this end, recent methods aim at estimating the true gradient signal based on the input queries but at the cost of excessive queries. We propose an efficient discrete surrogate to the optimization problem which does not require estimating the gradient and consequently becomes free of the first order update hyperparameters to tune. Our experiments on Cifar-10 and ImageNet show the state of the art black-box attack performance with significant reduction in the required queries compared to a number of recently proposed methods. The source code is available at https://github.com/snu-mllab/parsimonious-blackbox-attack.