 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEXT-EVAL: Next Evaluation of Traditional and LLM Web Data Record Extraction
May 21, 2025

Effective evaluation of web data record extraction methods is crucial, yet hampered by static, domain-specific benchmarks and opaque scoring practices. This makes fair comparison between traditional algorithmic techniques, which rely on structural heuristics, and Large Language Model (LLM)-based approaches, offering zero-shot extraction across diverse layouts, particularly challenging. To overcome these limitations, we introduce a concrete evaluation framework. Our framework systematically generates evaluation datasets from arbitrary MHTML snapshots, annotates XPath-based supervision labels, and employs structure-aware metrics for consistent scoring, specifically preventing text hallucination and allowing only for the assessment of positional hallucination. It also incorporates preprocessing strategies to optimize input for LLMs while preserving DOM semantics: HTML slimming, Hierarchical JSON, and Flat JSON. Additionally, we created a publicly available synthetic dataset by transforming DOM structures and modifying content. We benchmark deterministic heuristic algorithms and off-the-shelf LLMs across these multiple input formats. Our benchmarking shows that Flat JSON input enables LLMs to achieve superior extraction accuracy (F1 score of 0.9567) and minimal hallucination compared to other input formats like Slimmed HTML and Hierarchical JSON. We establish a standardized foundation for rigorous benchmarking, paving the way for the next principled advancements in web data record extraction.
Efficient Latency-Aware CNN Depth Compression via Two-Stage Dynamic Programming
Jan 28, 2023



Recent works on neural network pruning advocate that reducing the depth of the network is more effective in reducing run-time memory usage and accelerating inference latency than reducing the width of the network through channel pruning. In this regard, some recent works propose depth compression algorithms that merge convolution layers. However, the existing algorithms have a constricted search space and rely on human-engineered heuristics. In this paper, we propose a novel depth compression algorithm which targets general convolution operations. We propose a subset selection problem that replaces inefficient activation layers with identity functions and optimally merges consecutive convolution operations into shallow equivalent convolution operations for efficient end-to-end inference latency. Since the proposed subset selection problem is NP-hard, we formulate a surrogate optimization problem that can be solved exactly via two-stage dynamic programming within a few seconds. We evaluate our methods and baselines by TensorRT for a fair inference latency comparison. Our method outperforms the baseline method with higher accuracy and faster inference speed in MobileNetV2 on the ImageNet dataset. Specifically, we achieve $1.61\times$speed-up with only $0.62$\%p accuracy drop in MobileNetV2-1.4 on the ImageNet.
Optimal channel selection with discrete QCQP
Feb 24, 2022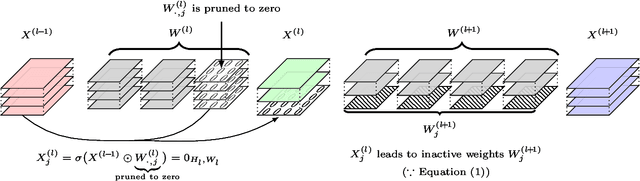

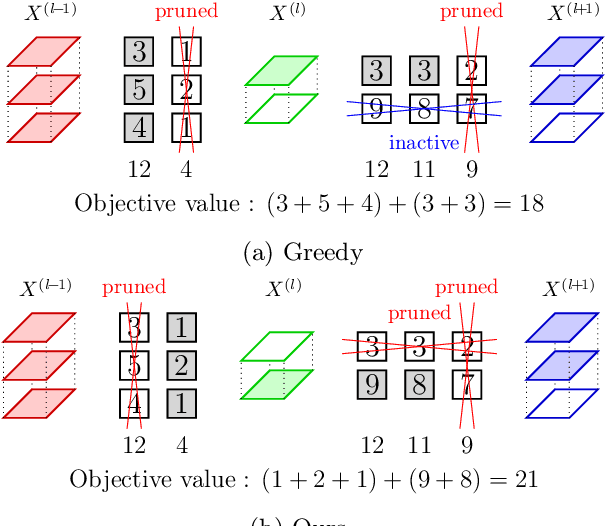
Reducing the high computational cost of large convolutional neural networks is crucial when deploying the networks to resource-constrained environments. We first show the greedy approach of recent channel pruning methods ignores the inherent quadratic coupling between channels in the neighboring layers and cannot safely remove inactive weights during the pruning procedure. Furthermore, due to these inactive weights, the greedy methods cannot guarantee to satisfy the given resource constraints and deviate with the true objective. In this regard, we propose a novel channel selection method that optimally selects channels via discrete QCQP, which provably prevents any inactive weights and guarantees to meet the resource constraints tightly in terms of FLOPs, memory usage, and network size. We also propose a quadratic model that accurately estimates the actual inference time of the pruned network, which allows us to adopt inference time as a resource constraint option. Furthermore, we generalize our method to extend the selection granularity beyond channels and handle non-sequential connections. Our experiments on CIFAR-10 and ImageNet show our proposed pruning method outperforms other fixed-importance channel pruning methods on various network architectures.
Learning Discrete and Continuous Factors of Data via Alternating Disentanglement
May 23, 2019

We address the problem of unsupervised disentanglement of discrete and continuous explanatory factors of data. We first show a simple procedure for minimizing the total correlation of the continuous latent variables without having to use a discriminator network or perform importance sampling, via cascading the information flow in the $\beta$-vae framework. Furthermore, we propose a method which avoids offloading the entire burden of jointly modeling the continuous and discrete factors to the variational encoder by employing a separate discrete inference procedure. This leads to an interesting alternating minimization problem which switches between finding the most likely discrete configuration given the continuous factors and updating the variational encoder based on the computed discrete factors. Experiments show that the proposed method clearly disentangles discrete factors and significantly outperforms current disentanglement methods based on the disentanglement score and inference network classification score. The source code is available at https://github.com/snu-mllab/DisentanglementICML19.
End-to-End Efficient Representation Learning via Cascading Combinatorial Optimization
Mar 07, 2019

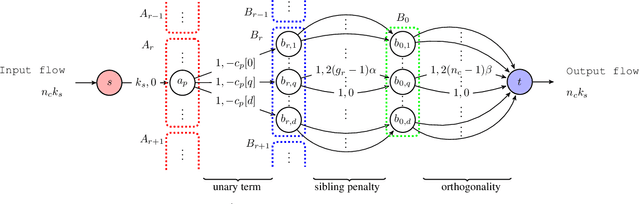

We develop hierarchically quantized efficient embedding representations for similarity-based search and show that this representation provides not only the state of the art performance on the search accuracy but also provides several orders of speed up during inference. The idea is to hierarchically quantize the representation so that the quantization granularity is greatly increased while maintaining the accuracy and keeping the computational complexity low. We also show that the problem of finding the optimal sparse compound hash code respecting the hierarchical structure can be optimized in polynomial time via minimum cost flow in an equivalent flow network. This allows us to train the method end-to-end in a mini-batch stochastic gradient descent setting. Our experiments on Cifar100 and ImageNet datasets show the state of the art search accuracy while providing several orders of magnitude search speedup respectively over exhaustive linear search over the dataset.
EMI: Exploration with Mutual Information Maximizing State and Action Embeddings
Oct 04, 2018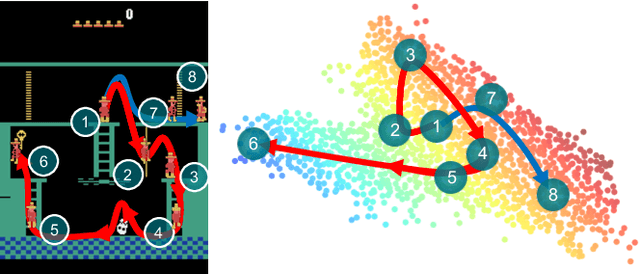
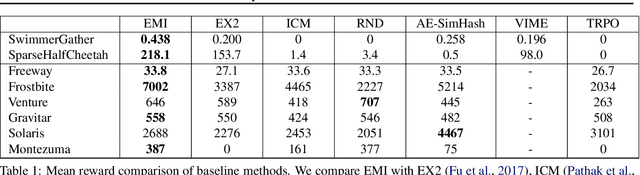
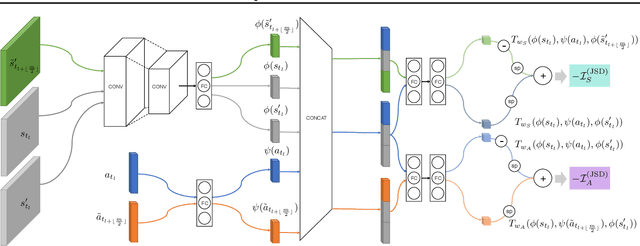
Policy optimization struggles when the reward feedback signal is very sparse and essentially becomes a random search algorithm until the agent accidentally stumbles upon a rewarding or the goal state. Recent works utilize intrinsic motivation to guide the exploration via generative models, predictive forward models, or more ad-hoc measures of surprise. We propose EMI, which is an exploration method that constructs embedding representation of states and actions that does not rely on generative decoding of the full observation but extracts predictive signals that can be used to guide exploration based on forward prediction in the representation space. Our experiments show the state of the art performance on challenging locomotion task with continuous control and on image-based exploration tasks with discrete actions on Atari.
Efficient end-to-end learning for quantizable representations
Jun 12, 2018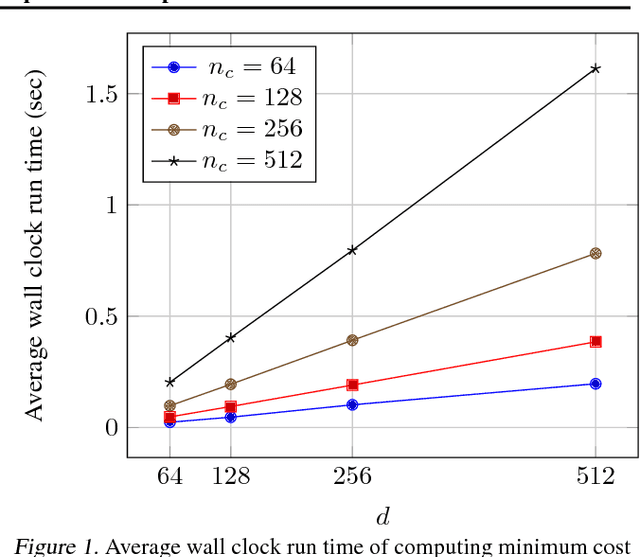

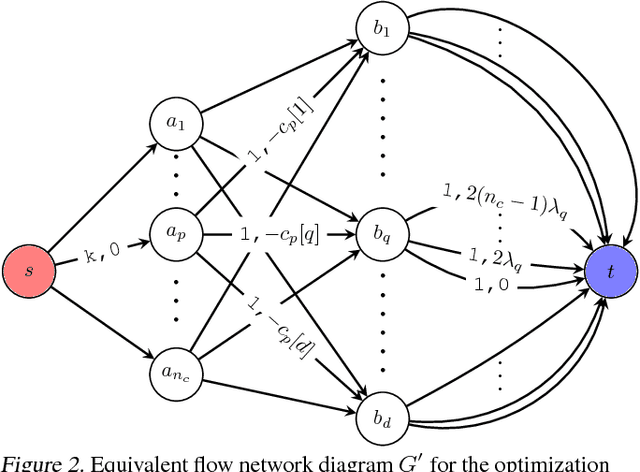

Embedding representation learning via neural networks is at the core foundation of modern similarity based search. While much effort has been put in developing algorithms for learning binary hamming code representations for search efficiency, this still requires a linear scan of the entire dataset per each query and trades off the search accuracy through binarization. To this end, we consider the problem of directly learning a quantizable embedding representation and the sparse binary hash code end-to-end which can be used to construct an efficient hash table not only providing significant search reduction in the number of data but also achieving the state of the art search accuracy outperforming previous state of the art deep metric learning methods. We also show that finding the optimal sparse binary hash code in a mini-batch can be computed exactly in polynomial time by solving a minimum cost flow problem. Our results on Cifar-100 and on ImageNet datasets show the state of the art search accuracy in precision@k and NMI metrics while providing up to 98X and 478X search speedup respectively over exhaustive linear search. The source code is available at https://github.com/maestrojeong/Deep-Hash-Table-ICML18