 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal channel selection with discrete QCQP
Feb 24, 2022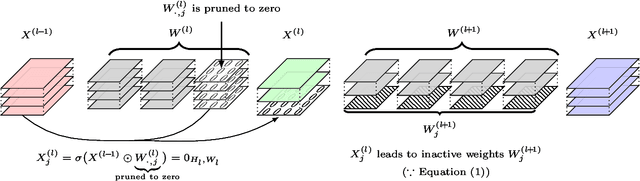

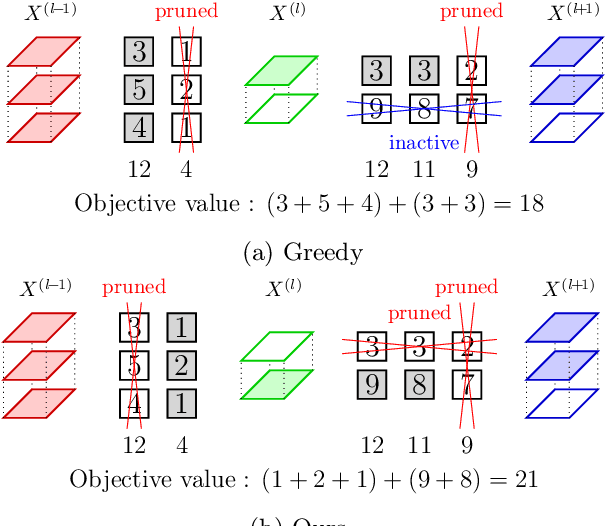
Reducing the high computational cost of large convolutional neural networks is crucial when deploying the networks to resource-constrained environments. We first show the greedy approach of recent channel pruning methods ignores the inherent quadratic coupling between channels in the neighboring layers and cannot safely remove inactive weights during the pruning procedure. Furthermore, due to these inactive weights, the greedy methods cannot guarantee to satisfy the given resource constraints and deviate with the true objective. In this regard, we propose a novel channel selection method that optimally selects channels via discrete QCQP, which provably prevents any inactive weights and guarantees to meet the resource constraints tightly in terms of FLOPs, memory usage, and network size. We also propose a quadratic model that accurately estimates the actual inference time of the pruned network, which allows us to adopt inference time as a resource constraint option. Furthermore, we generalize our method to extend the selection granularity beyond channels and handle non-sequential connections. Our experiments on CIFAR-10 and ImageNet show our proposed pruning method outperforms other fixed-importance channel pruning methods on various network architectures.
Joint Training of Low-Precision Neural Network with Quantization Interval Parameters
Aug 20, 2018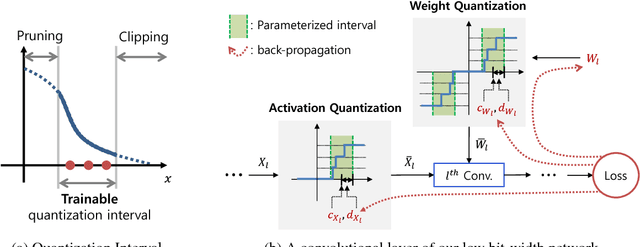
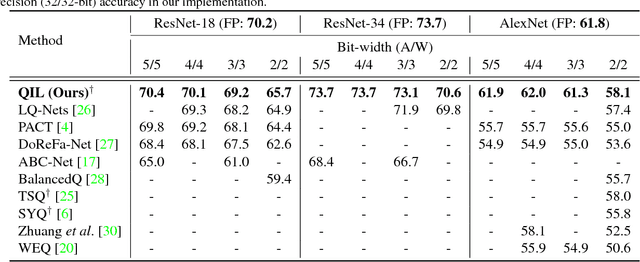
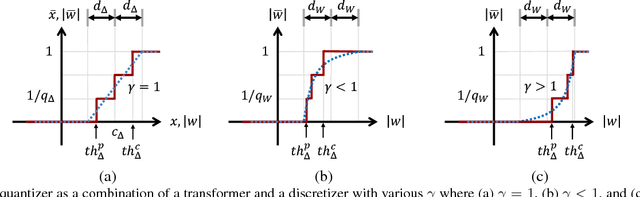
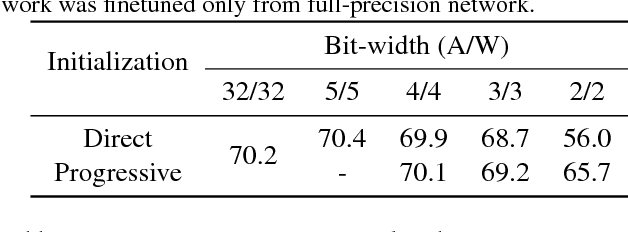
Optimization for low-precision neural network is an important technique for deep convolutional neural network models to be deployed to mobile devices. In order to realize convolutional layers with the simple bit-wise operations, both activation and weight parameters need to be quantized with a low bit-precision. In this paper, we propose a novel optimization method for low-precision neural network which trains both activation quantization parameters and the quantized model weights. We parameterize the quantization intervals of the weights and the activations and train the parameters with the full-precision weights by directly minimizing the training loss rather than minimizing the quantization error. Thanks to the joint optimization of quantization parameters and model weights, we obtain the highly accurate low-precision network given a target bitwidth. We demonstrated the effectiveness of our method on two benchmarks: CIFAR-10 and ImageNet.