 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Training of Low-Precision Neural Network with Quantization Interval Parameters
Paper and Code
Aug 20, 2018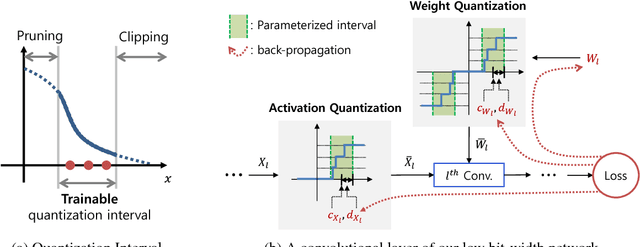
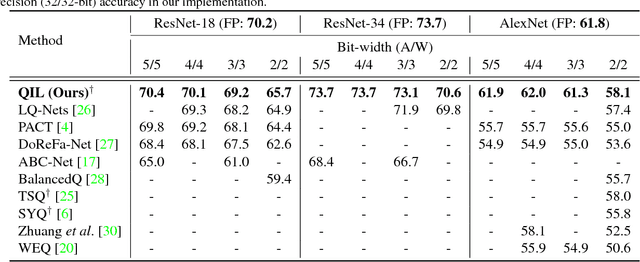
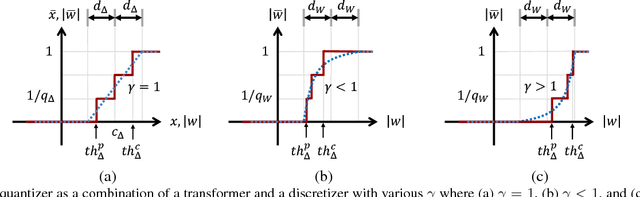
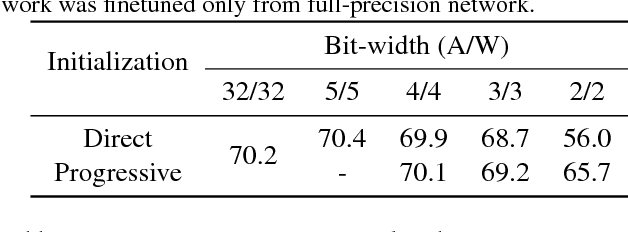
Optimization for low-precision neural network is an important technique for deep convolutional neural network models to be deployed to mobile devices. In order to realize convolutional layers with the simple bit-wise operations, both activation and weight parameters need to be quantized with a low bit-precision. In this paper, we propose a novel optimization method for low-precision neural network which trains both activation quantization parameters and the quantized model weights. We parameterize the quantization intervals of the weights and the activations and train the parameters with the full-precision weights by directly minimizing the training loss rather than minimizing the quantization error. Thanks to the joint optimization of quantization parameters and model weights, we obtain the highly accurate low-precision network given a target bitwidth. We demonstrated the effectiveness of our method on two benchmarks: CIFAR-10 and ImageNet.