 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Generation Pipeline with Enhanced Answerability Assessment for Financial Information Retrieval
Nov 07, 2025As financial applications of large language models (LLMs) gain attention, accurate Information Retrieval (IR) remains crucial for reliable AI services. However, existing benchmarks fail to capture the complex and domain-specific information needs of real-world banking scenarios. Building domain-specific IR benchmarks is costly and constrained by legal restrictions on using real customer data. To address these challenges, we propose a systematic methodology for constructing domain-specific IR benchmarks through LLM-based query generation. As a concrete implementation of this methodology, our pipeline combines single and multi-document query generation with an enhanced and reasoning-augmented answerability assessment method, achieving stronger alignment with human judgments than prior approaches. Using this methodology, we construct KoBankIR, comprising 815 queries derived from 204 official banking documents. Our experiments show that existing retrieval models struggle with the complex multi-document queries in KoBankIR, demonstrating the value of our systematic approach for domain-specific benchmark construction and underscoring the need for improved retrieval techniques in financial domains.
Federated Learning for Face Recognition via Intra-subject Self-supervised Learning
Jul 23, 2024Federated Learning (FL) for face recognition aggregates locally optimized models from individual clients to construct a generalized face recognition model. However, previous studies present two major challenges: insufficient incorporation of self-supervised learning and the necessity for clients to accommodate multiple subjects. To tackle these limitations, we propose FedFS (Federated Learning for personalized Face recognition via intra-subject Self-supervised learning framework), a novel federated learning architecture tailored to train personalized face recognition models without imposing subjects. Our proposed FedFS comprises two crucial components that leverage aggregated features of the local and global models to cooperate with representations of an off-the-shelf model. These components are (1) adaptive soft label construction, utilizing dot product operations to reformat labels within intra-instances, and (2) intra-subject self-supervised learning, employing cosine similarity operations to strengthen robust intra-subject representations. Additionally, we introduce a regularization loss to prevent overfitting and ensure the stability of the optimized model. To assess the effectiveness of FedFS, we conduct comprehensive experiments on the DigiFace-1M and VGGFace datasets, demonstrating superior performance compared to previous methods.
ProtoFL: Unsupervised Federated Learning via Prototypical Distillation
Aug 08, 2023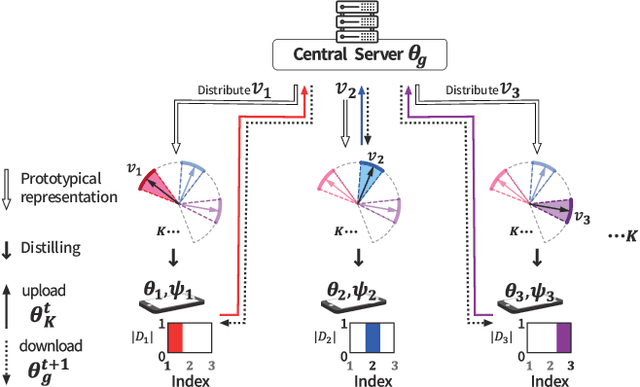
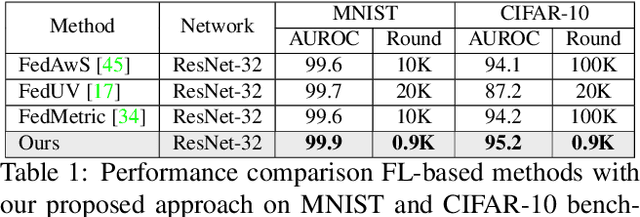
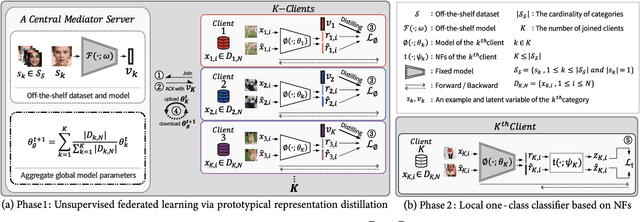

Federated learning (FL) is a promising approach for enhancing data privacy preservation, particularly for authentication systems. However, limited round communications, scarce representation, and scalability pose significant challenges to its deployment, hindering its full potential. In this paper, we propose 'ProtoFL', Prototypical Representation Distillation based unsupervised Federated Learning to enhance the representation power of a global model and reduce round communication costs. Additionally, we introduce a local one-class classifier based on normalizing flows to improve performance with limited data. Our study represents the first investigation of using FL to improve one-class classification performance. We conduct extensive experiments on five widely used benchmarks, namely MNIST, CIFAR-10, CIFAR-100, ImageNet-30, and Keystroke-Dynamics, to demonstrate the superior performance of our proposed framework over previous methods in the literature.
Robust face anti-spoofing framework with Convolutional Vision Transformer
Jul 24, 2023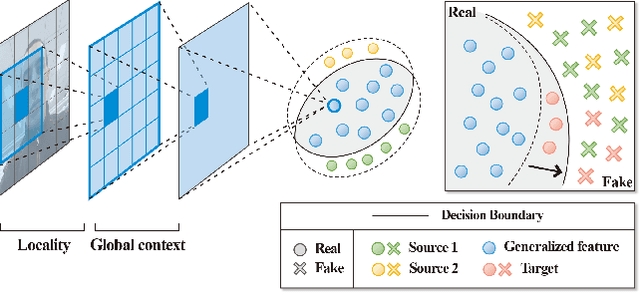



Owing to the advances in image processing technology and large-scale datasets, companies have implemented facial authentication processes, thereby stimulating increased focus on face anti-spoofing (FAS) against realistic presentation attacks. Recently, various attempts have been made to improve face recognition performance using both global and local learning on face images; however, to the best of our knowledge, this is the first study to investigate whether the robustness of FAS against domain shifts is improved by considering global information and local cues in face images captured using self-attention and convolutional layers. This study proposes a convolutional vision transformer-based framework that achieves robust performance for various unseen domain data. Our model resulted in 7.3%$p$ and 12.9%$p$ increases in FAS performance compared to models using only a convolutional neural network or vision transformer, respectively. It also shows the highest average rank in sub-protocols of cross-dataset setting over the other nine benchmark models for domain generalization.
Liveness score-based regression neural networks for face anti-spoofing
Feb 19, 2023Previous anti-spoofing methods have used either pseudo maps or user-defined labels, and the performance of each approach depends on the accuracy of the third party networks generating pseudo maps and the way in which the users define the labels. In this paper, we propose a liveness score-based regression network for overcoming the dependency on third party networks and users. First, we introduce a new labeling technique, called pseudo-discretized label encoding for generating discretized labels indicating the amount of information related to real images. Secondly, we suggest the expected liveness score based on a regression network for training the difference between the proposed supervision and the expected liveness score. Finally, extensive experiments were conducted on four face anti-spoofing benchmarks to verify our proposed method on both intra-and cross-dataset tests. The experimental results show our approach outperforms previous methods.
A Generalized and Robust Method Towards Practical Gaze Estimation on Smart Phone
Oct 16, 2019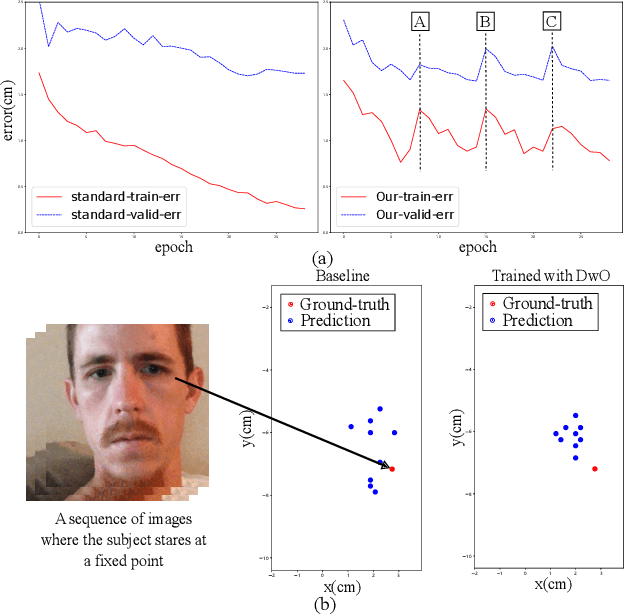
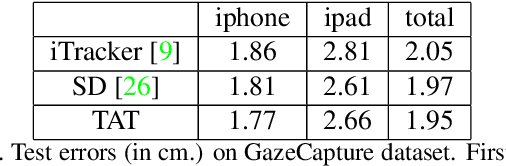
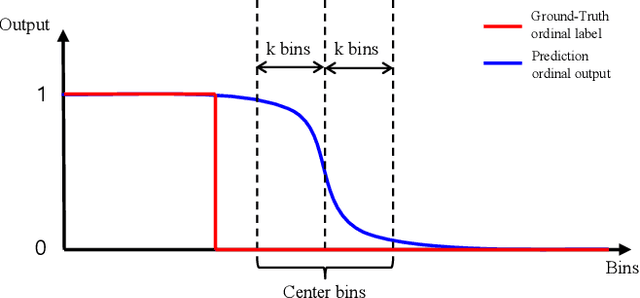
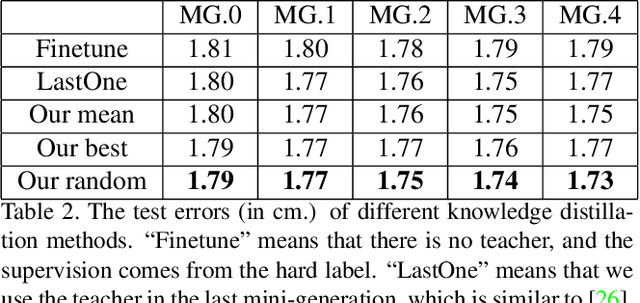
Gaze estimation for ordinary smart phone, e.g. estimating where the user is looking at on the phone screen, can be applied in various applications. However, the widely used appearance-based CNN methods still have two issues for practical adoption. First, due to the limited dataset, gaze estimation is very likely to suffer from over-fitting, leading to poor accuracy at run time. Second, the current methods are usually not robust, i.e. their prediction results having notable jitters even when the user is performing gaze fixation, which degrades user experience greatly. For the first issue, we propose a new tolerant and talented (TAT) training scheme, which is an iterative random knowledge distillation framework enhanced with cosine similarity pruning and aligned orthogonal initialization. The knowledge distillation is a tolerant teaching process providing diverse and informative supervision. The enhanced pruning and initialization is a talented learning process prompting the network to escape from the local minima and re-born from a better start. For the second issue, we define a new metric to measure the robustness of gaze estimator, and propose an adversarial training based Disturbance with Ordinal loss (DwO) method to improve it. The experimental results show that our TAT method achieves state-of-the-art performance on GazeCapture dataset, and that our DwO method improves the robustness while keeping comparable accuracy.
Deep generative-contrastive networks for facial expression recognition
Oct 25, 2018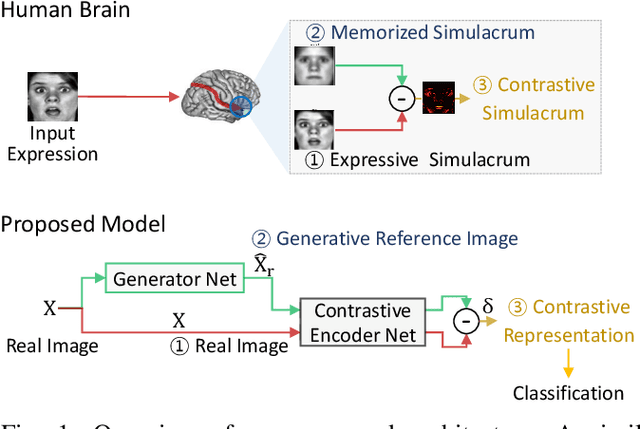
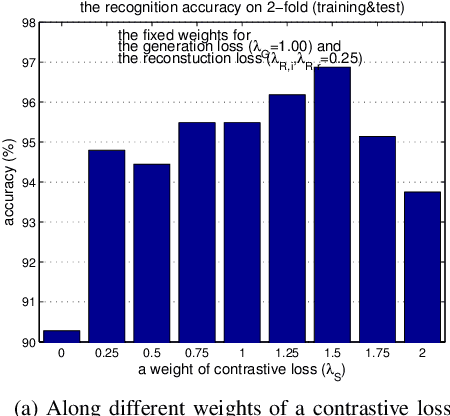
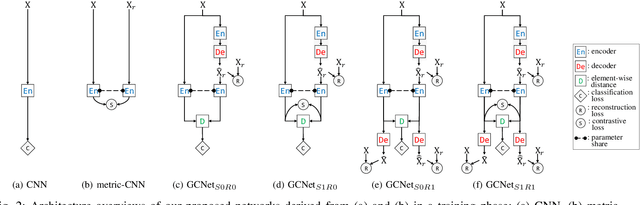
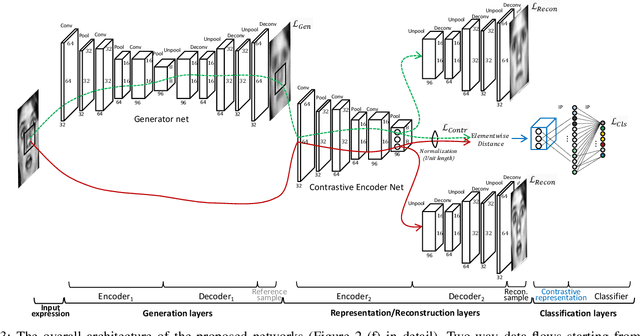
As the expressive depth of an emotional face differs with individuals or expressions, recognizing an expression using a single facial image at a moment is difficult. A relative expression of a query face compared to a reference face might alleviate this difficulty. In this paper, we propose to utilize contrastive representation that embeds a distinctive expressive factor for a discriminative purpose. The contrastive representation is calculated at the embedding layer of deep networks by comparing a given (query) image with the reference image. We attempt to utilize a generative reference image that is estimated based on the given image. Consequently, we deploy deep neural networks that embed a combination of a generative model, a contrastive model, and a discriminative model with an end-to-end training manner. In our proposed networks, we attempt to disentangle a facial expressive factor in two steps including learning of a generator network and a contrastive encoder network. We conducted extensive experiments on publicly available face expression databases (CK+, MMI, Oulu-CASIA, and in-the-wild databases) that have been widely adopted in the recent literatures. The proposed method outperforms the known state-of-the art methods in terms of the recognition accuracy.
Joint Training of Low-Precision Neural Network with Quantization Interval Parameters
Aug 20, 2018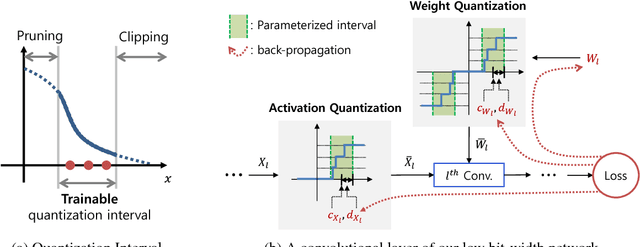
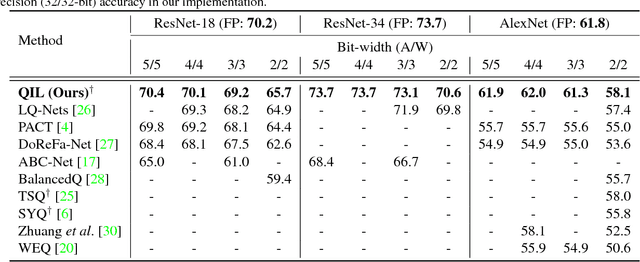
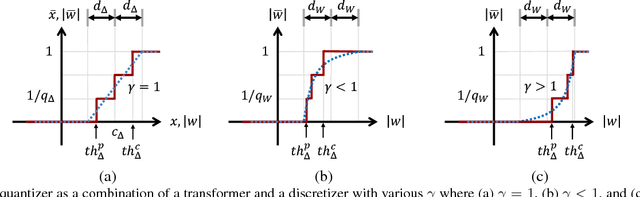
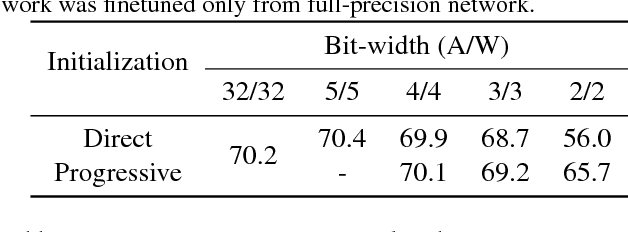
Optimization for low-precision neural network is an important technique for deep convolutional neural network models to be deployed to mobile devices. In order to realize convolutional layers with the simple bit-wise operations, both activation and weight parameters need to be quantized with a low bit-precision. In this paper, we propose a novel optimization method for low-precision neural network which trains both activation quantization parameters and the quantized model weights. We parameterize the quantization intervals of the weights and the activations and train the parameters with the full-precision weights by directly minimizing the training loss rather than minimizing the quantization error. Thanks to the joint optimization of quantization parameters and model weights, we obtain the highly accurate low-precision network given a target bitwidth. We demonstrated the effectiveness of our method on two benchmarks: CIFAR-10 and ImageNet.