 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios
Feb 19, 2026Large language models (LLMs)-based chatbots are increasingly being adopted in the financial domain, particularly in digital banking, to handle customer inquiries about products such as deposits, savings, and loans. However, these models still exhibit low accuracy in core banking computations-including total payout estimation, comparison of products with varying interest rates, and interest calculation under early repayment conditions. Such tasks require multi-step numerical reasoning and contextual understanding of banking products, yet existing LLMs often make systematic errors-misinterpreting product types, applying conditions incorrectly, or failing basic calculations involving exponents and geometric progressions. However, such errors have rarely been captured by existing benchmarks. Mathematical datasets focus on fundamental math problems, whereas financial benchmarks primarily target financial documents, leaving everyday banking scenarios underexplored. To address this limitation, we propose BankMathBench, a domain-specific dataset that reflects realistic banking tasks. BankMathBench is organized in three levels of difficulty-basic, intermediate, and advanced-corresponding to single-product reasoning, multi-product comparison, and multi-condition scenarios, respectively. When trained on BankMathBench, open-source LLMs exhibited notable improvements in both formula generation and numerical reasoning accuracy, demonstrating the dataset's effectiveness in enhancing domain-specific reasoning. With tool-augmented fine-tuning, the models achieved average accuracy increases of 57.6%p (basic), 75.1%p (intermediate), and 62.9%p (advanced), representing significant gains over zero-shot baselines. These findings highlight BankMathBench as a reliable benchmark for evaluating and advancing LLMs' numerical reasoning in real-world banking scenarios.
Robust face anti-spoofing framework with Convolutional Vision Transformer
Jul 24, 2023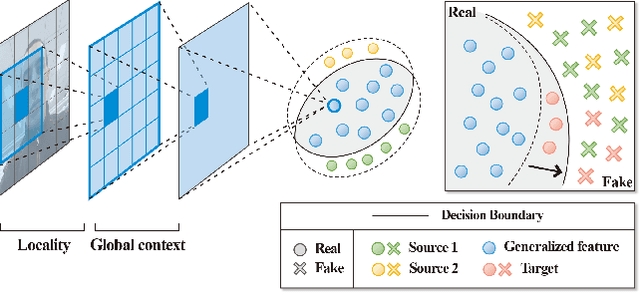



Owing to the advances in image processing technology and large-scale datasets, companies have implemented facial authentication processes, thereby stimulating increased focus on face anti-spoofing (FAS) against realistic presentation attacks. Recently, various attempts have been made to improve face recognition performance using both global and local learning on face images; however, to the best of our knowledge, this is the first study to investigate whether the robustness of FAS against domain shifts is improved by considering global information and local cues in face images captured using self-attention and convolutional layers. This study proposes a convolutional vision transformer-based framework that achieves robust performance for various unseen domain data. Our model resulted in 7.3%$p$ and 12.9%$p$ increases in FAS performance compared to models using only a convolutional neural network or vision transformer, respectively. It also shows the highest average rank in sub-protocols of cross-dataset setting over the other nine benchmark models for domain generalization.
AnoViT: Unsupervised Anomaly Detection and Localization with Vision Transformer-based Encoder-Decoder
Mar 21, 2022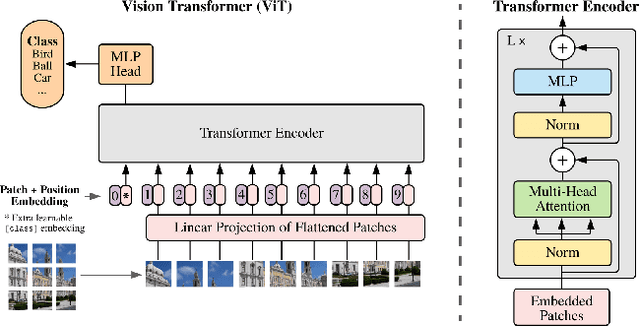
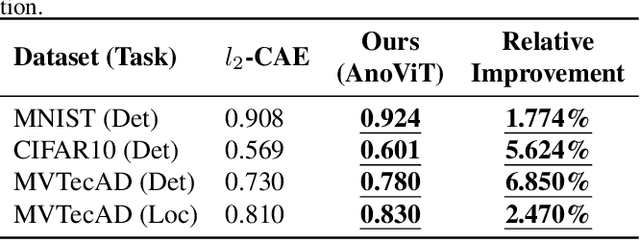


Image anomaly detection problems aim to determine whether an image is abnormal, and to detect anomalous areas. These methods are actively used in various fields such as manufacturing, medical care, and intelligent information. Encoder-decoder structures have been widely used in the field of anomaly detection because they can easily learn normal patterns in an unsupervised learning environment and calculate a score to identify abnormalities through a reconstruction error indicating the difference between input and reconstructed images. Therefore, current image anomaly detection methods have commonly used convolutional encoder-decoders to extract normal information through the local features of images. However, they are limited in that only local features of the image can be utilized when constructing a normal representation owing to the characteristics of convolution operations using a filter of fixed size. Therefore, we propose a vision transformer-based encoder-decoder model, named AnoViT, designed to reflect normal information by additionally learning the global relationship between image patches, which is capable of both image anomaly detection and localization. The proposed approach constructs a feature map that maintains the existing location information of individual patches by using the embeddings of all patches passed through multiple self-attention layers. The proposed AnoViT model performed better than the convolution-based model on three benchmark datasets. In MVTecAD, which is a representative benchmark dataset for anomaly localization, it showed improved results on 10 out of 15 classes compared with the baseline. Furthermore, the proposed method showed good performance regardless of the class and type of the anomalous area when localization results were evaluated qualitatively.