 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnoViT: Unsupervised Anomaly Detection and Localization with Vision Transformer-based Encoder-Decoder
Paper and Code
Mar 21, 2022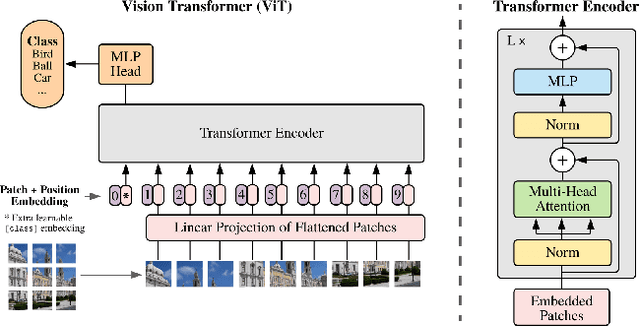
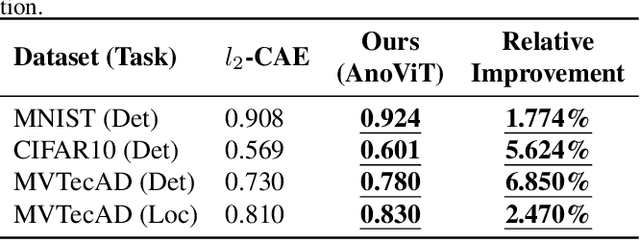


Image anomaly detection problems aim to determine whether an image is abnormal, and to detect anomalous areas. These methods are actively used in various fields such as manufacturing, medical care, and intelligent information. Encoder-decoder structures have been widely used in the field of anomaly detection because they can easily learn normal patterns in an unsupervised learning environment and calculate a score to identify abnormalities through a reconstruction error indicating the difference between input and reconstructed images. Therefore, current image anomaly detection methods have commonly used convolutional encoder-decoders to extract normal information through the local features of images. However, they are limited in that only local features of the image can be utilized when constructing a normal representation owing to the characteristics of convolution operations using a filter of fixed size. Therefore, we propose a vision transformer-based encoder-decoder model, named AnoViT, designed to reflect normal information by additionally learning the global relationship between image patches, which is capable of both image anomaly detection and localization. The proposed approach constructs a feature map that maintains the existing location information of individual patches by using the embeddings of all patches passed through multiple self-attention layers. The proposed AnoViT model performed better than the convolution-based model on three benchmark datasets. In MVTecAD, which is a representative benchmark dataset for anomaly localization, it showed improved results on 10 out of 15 classes compared with the baseline. Furthermore, the proposed method showed good performance regardless of the class and type of the anomalous area when localization results were evaluated qualitatively.