 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust face anti-spoofing framework with Convolutional Vision Transformer
Paper and Code
Jul 24, 2023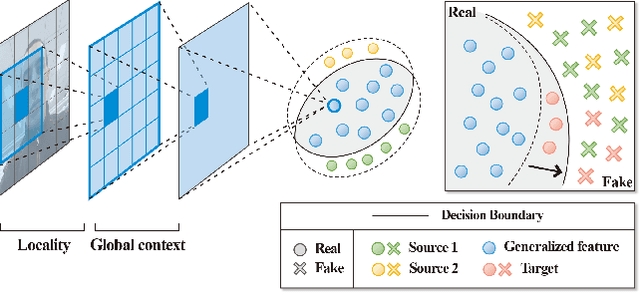



Owing to the advances in image processing technology and large-scale datasets, companies have implemented facial authentication processes, thereby stimulating increased focus on face anti-spoofing (FAS) against realistic presentation attacks. Recently, various attempts have been made to improve face recognition performance using both global and local learning on face images; however, to the best of our knowledge, this is the first study to investigate whether the robustness of FAS against domain shifts is improved by considering global information and local cues in face images captured using self-attention and convolutional layers. This study proposes a convolutional vision transformer-based framework that achieves robust performance for various unseen domain data. Our model resulted in 7.3%$p$ and 12.9%$p$ increases in FAS performance compared to models using only a convolutional neural network or vision transformer, respectively. It also shows the highest average rank in sub-protocols of cross-dataset setting over the other nine benchmark models for domain generalization.