 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember Your Trace: Memory-Guided Long-Horizon Agentic Framework for Consistent and Hierarchical Repository-Level Code Documentation
May 14, 2026Automated code documentation is essential for modern software development, providing the contextual grounding that both human developers and coding agents rely on to navigate large codebases. Existing repository-level approaches process components independently, causing redundant retrieval and conflicting descriptions across documents while producing outputs that lack hierarchical structure. Therefore, we propose MemDocAgent, a long-horizon agentic framework that generates documentation within a single, integrated context spanning the entire repository. It combines two components: (i) Dependency-Aware Traversal Guiding that predetermines a traversal order respecting dependency and granularity hierarchies; (ii) Memory-Guided Agentic Interaction, in which the agent interacts with RepoMemory, a shared memory accumulating prior work traces through read, write, and verify operations. Through an in-depth multi-criteria evaluation, MemDocAgent achieves the best performance over both open and closed-source baselines and demonstrates practical applicability in real software development workflows.
Towards Self-Explainable Document Visual Question Answering with Chain-of-Explanation Predictions
May 07, 2026Document Visual Question Answering (DocVQA) requires vision-language models to reason not only about what information in a document is relevant to a question, but also where the answer is grounded on the page. Existing DocVQA models entangle question-relevant evidence and answer localization and operate largely as black boxes, offering limited means to verify how predictions depend on visual evidence. We propose CoExVQA, a self-explainable DocVQA framework with a grounded reasoning process through a chain-of-explanation design. CoExVQA first identifies question-relevant evidence, then explicitly localizes the answer region, and finally decodes the answer exclusively from the grounded region. Prediction via CoExVQA's chain-of-explanation enables direct inspection and verification of the reasoning process across modalities. Empirical results show that restricting decoding to grounded evidence achieves SotA explainable DocVQA performance on PFL-DocVQA, improving ANLS by 12% over the current explainable baselines while providing transparent and verifiable predictions.
Suppressing Non-Semantic Noise in Masked Image Modeling Representations
Mar 31, 2026Masked Image Modeling (MIM) has become a ubiquitous self-supervised vision paradigm. In this work, we show that MIM objectives cause the learned representations to retain non-semantic information, which ultimately hurts performance during inference. We introduce a model-agnostic score for semantic invariance using Principal Component Analysis (PCA) on real and synthetic non-semantic images. Based on this score, we propose a simple method, Semantically Orthogonal Artifact Projection (SOAP), to directly suppress non-semantic information in patch representations, leading to consistent improvements in zero-shot performance across various MIM-based models. SOAP is a post-hoc suppression method, requires zero training, and can be attached to any model as a single linear head.
DocVXQA: Context-Aware Visual Explanations for Document Question Answering
May 12, 2025We propose DocVXQA, a novel framework for visually self-explainable document question answering. The framework is designed not only to produce accurate answers to questions but also to learn visual heatmaps that highlight contextually critical regions, thereby offering interpretable justifications for the model's decisions. To integrate explanations into the learning process, we quantitatively formulate explainability principles as explicit learning objectives. Unlike conventional methods that emphasize only the regions pertinent to the answer, our framework delivers explanations that are \textit{contextually sufficient} while remaining \textit{representation-efficient}. This fosters user trust while achieving a balance between predictive performance and interpretability in DocVQA applications. Extensive experiments, including human evaluation, provide strong evidence supporting the effectiveness of our method. The code is available at https://github.com/dali92002/DocVXQA.
Addressing Label Shift in Distributed Learning via Entropy Regularization
Feb 04, 2025We address the challenge of minimizing true risk in multi-node distributed learning. These systems are frequently exposed to both inter-node and intra-node label shifts, which present a critical obstacle to effectively optimizing model performance while ensuring that data remains confined to each node. To tackle this, we propose the Versatile Robust Label Shift (VRLS) method, which enhances the maximum likelihood estimation of the test-to-train label density ratio. VRLS incorporates Shannon entropy-based regularization and adjusts the density ratio during training to better handle label shifts at the test time. In multi-node learning environments, VRLS further extends its capabilities by learning and adapting density ratios across nodes, effectively mitigating label shifts and improving overall model performance. Experiments conducted on MNIST, Fashion MNIST, and CIFAR-10 demonstrate the effectiveness of VRLS, outperforming baselines by up to 20% in imbalanced settings. These results highlight the significant improvements VRLS offers in addressing label shifts. Our theoretical analysis further supports this by establishing high-probability bounds on estimation errors.
Data-free mixed-precision quantization using novel sensitivity metric
Mar 18, 2021
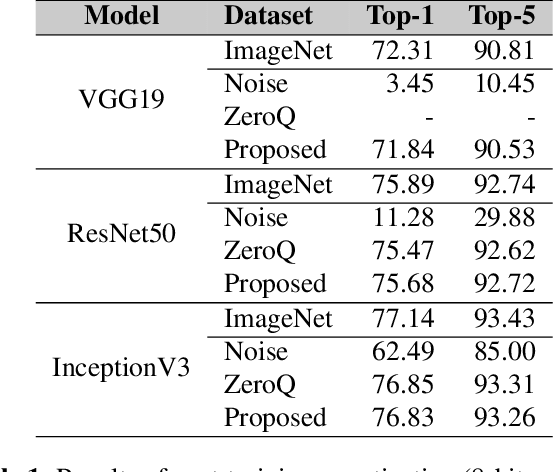
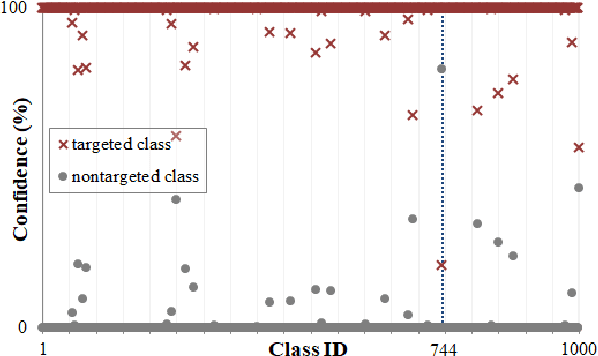
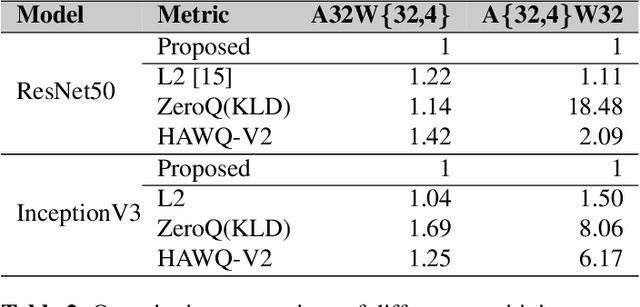
Post-training quantization is a representative technique for compressing neural networks, making them smaller and more efficient for deployment on edge devices. However, an inaccessible user dataset often makes it difficult to ensure the quality of the quantized neural network in practice. In addition, existing approaches may use a single uniform bit-width across the network, resulting in significant accuracy degradation at extremely low bit-widths. To utilize multiple bit-width, sensitivity metric plays a key role in balancing accuracy and compression. In this paper, we propose a novel sensitivity metric that considers the effect of quantization error on task loss and interaction with other layers. Moreover, we develop labeled data generation methods that are not dependent on a specific operation of the neural network. Our experiments show that the proposed metric better represents quantization sensitivity, and generated data are more feasible to be applied to mixed-precision quantization.
A Generalized and Robust Method Towards Practical Gaze Estimation on Smart Phone
Oct 16, 2019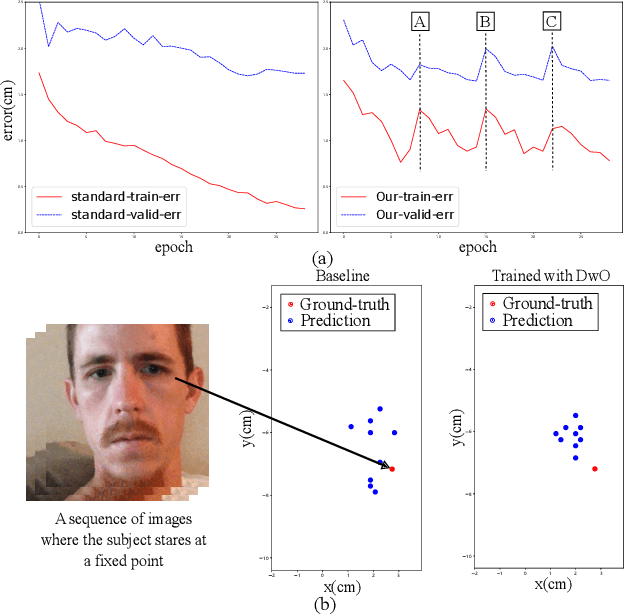
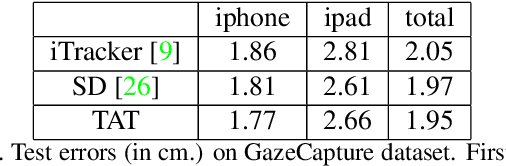
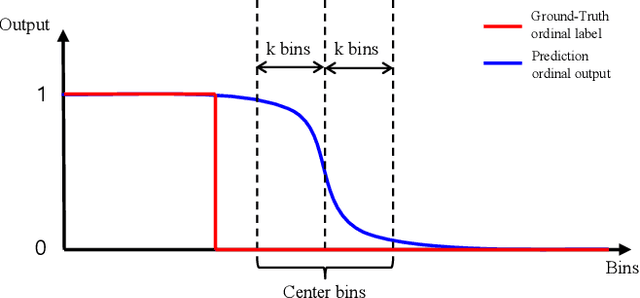
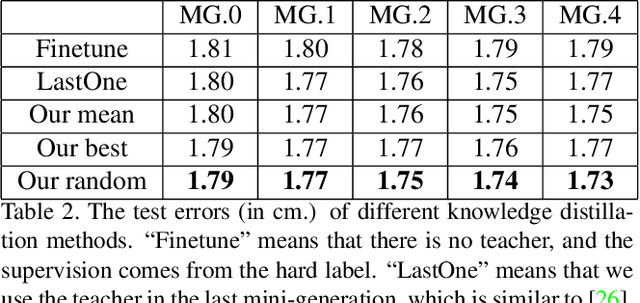
Gaze estimation for ordinary smart phone, e.g. estimating where the user is looking at on the phone screen, can be applied in various applications. However, the widely used appearance-based CNN methods still have two issues for practical adoption. First, due to the limited dataset, gaze estimation is very likely to suffer from over-fitting, leading to poor accuracy at run time. Second, the current methods are usually not robust, i.e. their prediction results having notable jitters even when the user is performing gaze fixation, which degrades user experience greatly. For the first issue, we propose a new tolerant and talented (TAT) training scheme, which is an iterative random knowledge distillation framework enhanced with cosine similarity pruning and aligned orthogonal initialization. The knowledge distillation is a tolerant teaching process providing diverse and informative supervision. The enhanced pruning and initialization is a talented learning process prompting the network to escape from the local minima and re-born from a better start. For the second issue, we define a new metric to measure the robustness of gaze estimator, and propose an adversarial training based Disturbance with Ordinal loss (DwO) method to improve it. The experimental results show that our TAT method achieves state-of-the-art performance on GazeCapture dataset, and that our DwO method improves the robustness while keeping comparable accuracy.
Deep generative-contrastive networks for facial expression recognition
Oct 25, 2018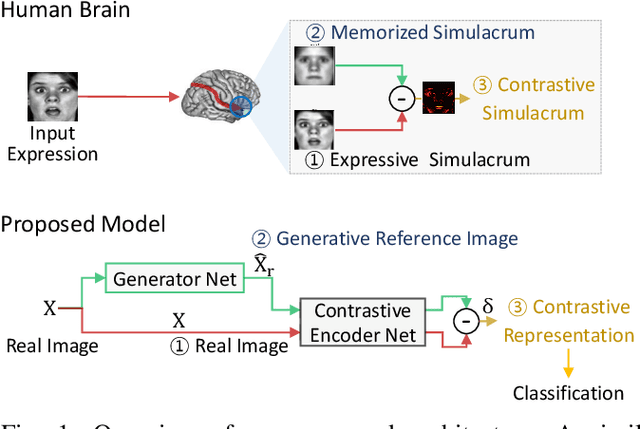
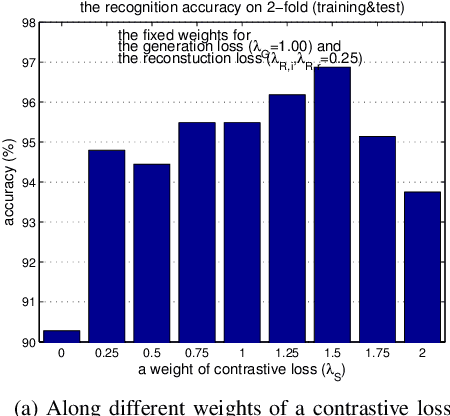
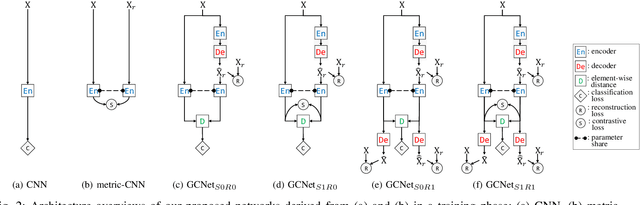
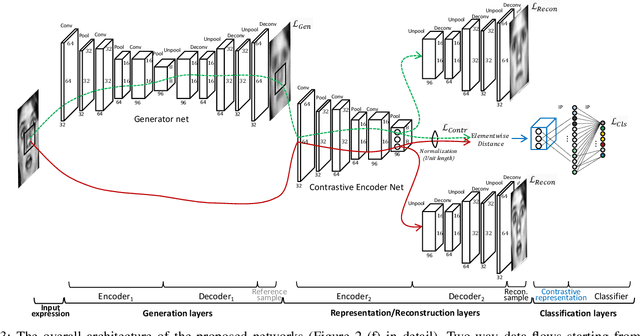
As the expressive depth of an emotional face differs with individuals or expressions, recognizing an expression using a single facial image at a moment is difficult. A relative expression of a query face compared to a reference face might alleviate this difficulty. In this paper, we propose to utilize contrastive representation that embeds a distinctive expressive factor for a discriminative purpose. The contrastive representation is calculated at the embedding layer of deep networks by comparing a given (query) image with the reference image. We attempt to utilize a generative reference image that is estimated based on the given image. Consequently, we deploy deep neural networks that embed a combination of a generative model, a contrastive model, and a discriminative model with an end-to-end training manner. In our proposed networks, we attempt to disentangle a facial expressive factor in two steps including learning of a generator network and a contrastive encoder network. We conducted extensive experiments on publicly available face expression databases (CK+, MMI, Oulu-CASIA, and in-the-wild databases) that have been widely adopted in the recent literatures. The proposed method outperforms the known state-of-the art methods in terms of the recognition accuracy.
Joint Training of Low-Precision Neural Network with Quantization Interval Parameters
Aug 20, 2018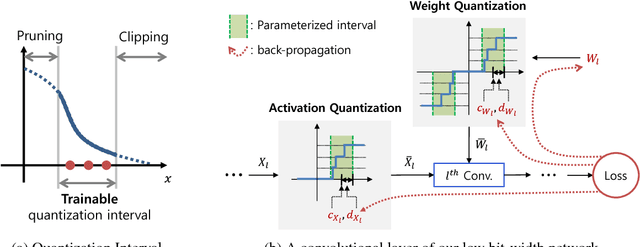
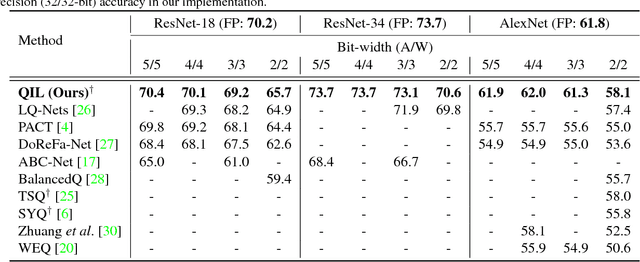
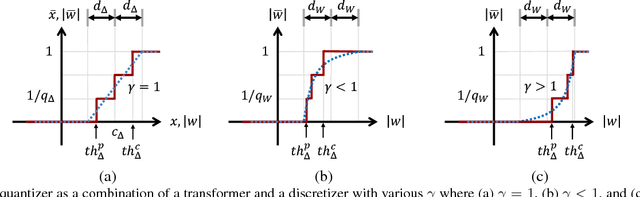
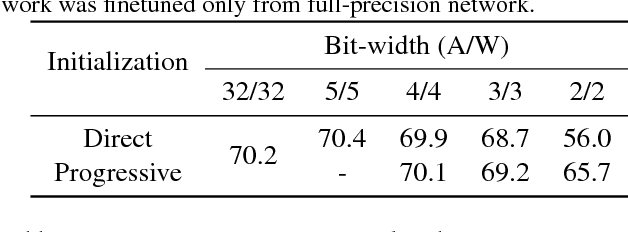
Optimization for low-precision neural network is an important technique for deep convolutional neural network models to be deployed to mobile devices. In order to realize convolutional layers with the simple bit-wise operations, both activation and weight parameters need to be quantized with a low bit-precision. In this paper, we propose a novel optimization method for low-precision neural network which trains both activation quantization parameters and the quantized model weights. We parameterize the quantization intervals of the weights and the activations and train the parameters with the full-precision weights by directly minimizing the training loss rather than minimizing the quantization error. Thanks to the joint optimization of quantization parameters and model weights, we obtain the highly accurate low-precision network given a target bitwidth. We demonstrated the effectiveness of our method on two benchmarks: CIFAR-10 and ImageNet.