 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Scale: Unlocking Large-Scale 3D Gaussian Splatting Training via Host Offloading
Sep 19, 2025The advent of 3D Gaussian Splatting has revolutionized graphics rendering by delivering high visual quality and fast rendering speeds. However, training large-scale scenes at high quality remains challenging due to the substantial memory demands required to store parameters, gradients, and optimizer states, which can quickly overwhelm GPU memory. To address these limitations, we propose GS-Scale, a fast and memory-efficient training system for 3D Gaussian Splatting. GS-Scale stores all Gaussians in host memory, transferring only a subset to the GPU on demand for each forward and backward pass. While this dramatically reduces GPU memory usage, it requires frustum culling and optimizer updates to be executed on the CPU, introducing slowdowns due to CPU's limited compute and memory bandwidth. To mitigate this, GS-Scale employs three system-level optimizations: (1) selective offloading of geometric parameters for fast frustum culling, (2) parameter forwarding to pipeline CPU optimizer updates with GPU computation, and (3) deferred optimizer update to minimize unnecessary memory accesses for Gaussians with zero gradients. Our extensive evaluations on large-scale datasets demonstrate that GS-Scale significantly lowers GPU memory demands by 3.3-5.6x, while achieving training speeds comparable to GPU without host offloading. This enables large-scale 3D Gaussian Splatting training on consumer-grade GPUs; for instance, GS-Scale can scale the number of Gaussians from 4 million to 18 million on an RTX 4070 Mobile GPU, leading to 23-35% LPIPS (learned perceptual image patch similarity) improvement.
GPTQv2: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Apr 03, 2025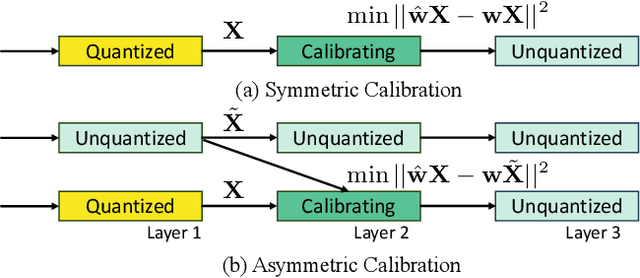
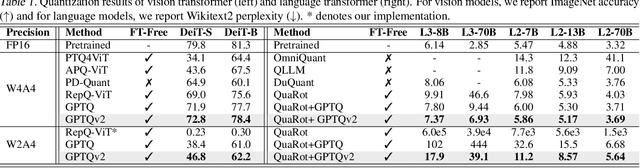
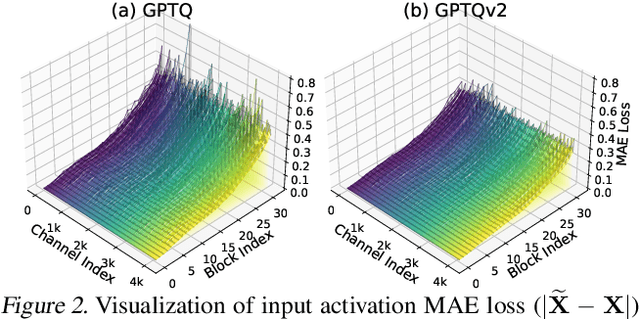
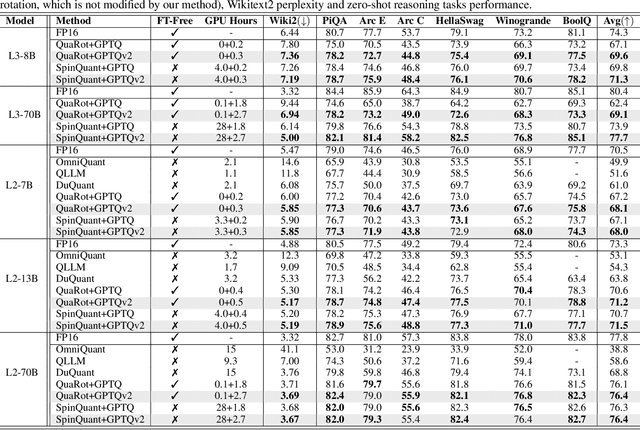
We introduce GPTQv2, a novel finetuning-free quantization method for compressing large-scale transformer architectures. Unlike the previous GPTQ method, which independently calibrates each layer, we always match the quantized layer's output to the exact output in the full-precision model, resulting in a scheme that we call asymmetric calibration. Such a scheme can effectively reduce the quantization error accumulated in previous layers. We analyze this problem using optimal brain compression to derive a close-formed solution. The new solution explicitly minimizes the quantization error as well as the accumulated asymmetry error. Furthermore, we utilize various techniques to parallelize the solution calculation, including channel parallelization, neuron decomposition, and Cholesky reformulation for matrix fusion. As a result, GPTQv2 is easy to implement, simply using 20 more lines of code than GPTQ but improving its performance under low-bit quantization. Remarkably, on a single GPU, we quantize a 405B language transformer as well as EVA-02 the rank first vision transformer that achieves 90% pretraining Imagenet accuracy. Code is available at github.com/Intelligent-Computing-Lab-Yale/GPTQv2.
Do Vision Models Develop Human-Like Progressive Difficulty Understanding?
Mar 17, 2025When a human undertakes a test, their responses likely follow a pattern: if they answered an easy question $(2 \times 3)$ incorrectly, they would likely answer a more difficult one $(2 \times 3 \times 4)$ incorrectly; and if they answered a difficult question correctly, they would likely answer the easy one correctly. Anything else hints at memorization. Do current visual recognition models exhibit a similarly structured learning capacity? In this work, we consider the task of image classification and study if those models' responses follow that pattern. Since real images aren't labeled with difficulty, we first create a dataset of 100 categories, 10 attributes, and 3 difficulty levels using recent generative models: for each category (e.g., dog) and attribute (e.g., occlusion), we generate images of increasing difficulty (e.g., a dog without occlusion, a dog only partly visible). We find that most of the models do in fact behave similarly to the aforementioned pattern around 80-90% of the time. Using this property, we then explore a new way to evaluate those models. Instead of testing the model on every possible test image, we create an adaptive test akin to GRE, in which the model's performance on the current round of images determines the test images in the next round. This allows the model to skip over questions too easy/hard for itself, and helps us get its overall performance in fewer steps.
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Jan 08, 2025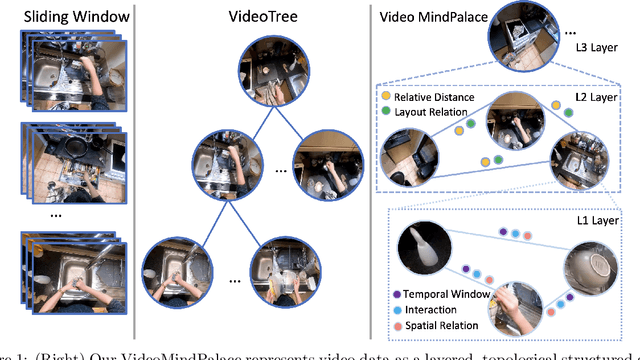
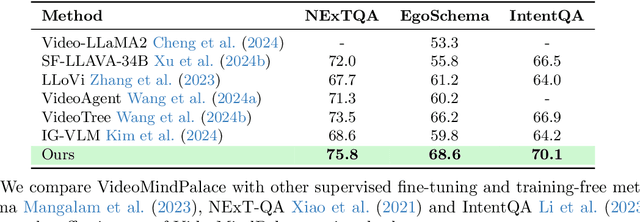
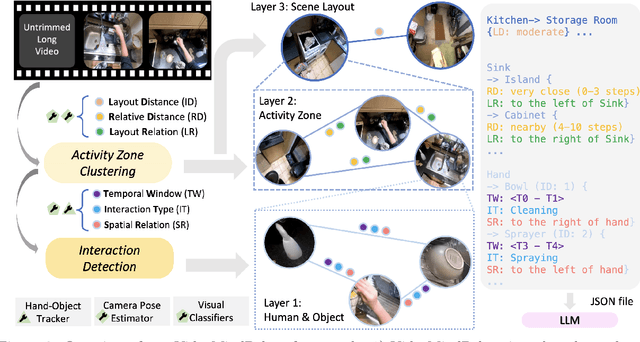
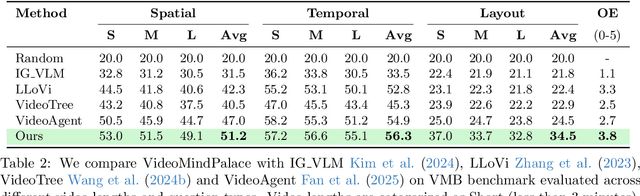
Long-form video understanding with Large Vision Language Models is challenged by the need to analyze temporally dispersed yet spatially concentrated key moments within limited context windows. In this work, we introduce VideoMindPalace, a new framework inspired by the "Mind Palace", which organizes critical video moments into a topologically structured semantic graph. VideoMindPalace organizes key information through (i) hand-object tracking and interaction, (ii) clustered activity zones representing specific areas of recurring activities, and (iii) environment layout mapping, allowing natural language parsing by LLMs to provide grounded insights on spatio-temporal and 3D context. In addition, we propose the Video MindPalace Benchmark (VMB), to assess human-like reasoning, including spatial localization, temporal reasoning, and layout-aware sequential understanding. Evaluated on VMB and established video QA datasets, including EgoSchema, NExT-QA, IntentQA, and the Active Memories Benchmark, VideoMindPalace demonstrates notable gains in spatio-temporal coherence and human-aligned reasoning, advancing long-form video analysis capabilities in VLMs.
Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems
Oct 09, 2024As Large Language Models (LLMs) grow increasingly powerful, multi-agent systems are becoming more prevalent in modern AI applications. Most safety research, however, has focused on vulnerabilities in single-agent LLMs. These include prompt injection attacks, where malicious prompts embedded in external content trick the LLM into executing unintended or harmful actions, compromising the victim's application. In this paper, we reveal a more dangerous vector: LLM-to-LLM prompt injection within multi-agent systems. We introduce Prompt Infection, a novel attack where malicious prompts self-replicate across interconnected agents, behaving much like a computer virus. This attack poses severe threats, including data theft, scams, misinformation, and system-wide disruption, all while propagating silently through the system. Our extensive experiments demonstrate that multi-agent systems are highly susceptible, even when agents do not publicly share all communications. To address this, we propose LLM Tagging, a defense mechanism that, when combined with existing safeguards, significantly mitigates infection spread. This work underscores the urgent need for advanced security measures as multi-agent LLM systems become more widely adopted.
Spiking Transformer with Spatial-Temporal Attention
Sep 29, 2024



Spiking Neural Networks (SNNs) present a compelling and energy-efficient alternative to traditional Artificial Neural Networks (ANNs) due to their sparse binary activation. Leveraging the success of the transformer architecture, the spiking transformer architecture is explored to scale up dataset size and performance. However, existing works only consider the spatial self-attention in spiking transformer, neglecting the inherent temporal context across the timesteps. In this work, we introduce Spiking Transformer with Spatial-Temporal Attention (STAtten), a simple and straightforward architecture designed to integrate spatial and temporal information in self-attention with negligible additional computational load. The STAtten divides the temporal or token index and calculates the self-attention in a cross-manner to effectively incorporate spatial-temporal information. We first verify our spatial-temporal attention mechanism's ability to capture long-term temporal dependencies using sequential datasets. Moreover, we validate our approach through extensive experiments on varied datasets, including CIFAR10/100, ImageNet, CIFAR10-DVS, and N-Caltech101. Notably, our cross-attention mechanism achieves an accuracy of 78.39 % on the ImageNet dataset.
ReSpike: Residual Frames-based Hybrid Spiking Neural Networks for Efficient Action Recognition
Sep 03, 2024Spiking Neural Networks (SNNs) have emerged as a compelling, energy-efficient alternative to traditional Artificial Neural Networks (ANNs) for static image tasks such as image classification and segmentation. However, in the more complex video classification domain, SNN-based methods fall considerably short of ANN-based benchmarks due to the challenges in processing dense frame sequences. To bridge this gap, we propose ReSpike, a hybrid framework that synergizes the strengths of ANNs and SNNs to tackle action recognition tasks with high accuracy and low energy cost. By decomposing film clips into spatial and temporal components, i.e., RGB image Key Frames and event-like Residual Frames, ReSpike leverages ANN for learning spatial information and SNN for learning temporal information. In addition, we propose a multi-scale cross-attention mechanism for effective feature fusion. Compared to state-of-the-art SNN baselines, our ReSpike hybrid architecture demonstrates significant performance improvements (e.g., >30% absolute accuracy improvement on HMDB-51, UCF-101, and Kinetics-400). Furthermore, ReSpike achieves comparable performance with prior ANN approaches while bringing better accuracy-energy tradeoff.
Decoupled Marked Temporal Point Process using Neural Ordinary Differential Equations
Jun 10, 2024A Marked Temporal Point Process (MTPP) is a stochastic process whose realization is a set of event-time data. MTPP is often used to understand complex dynamics of asynchronous temporal events such as money transaction, social media, healthcare, etc. Recent studies have utilized deep neural networks to capture complex temporal dependencies of events and generate embedding that aptly represent the observed events. While most previous studies focus on the inter-event dependencies and their representations, how individual events influence the overall dynamics over time has been under-explored. In this regime, we propose a Decoupled MTPP framework that disentangles characterization of a stochastic process into a set of evolving influences from different events. Our approach employs Neural Ordinary Differential Equations (Neural ODEs) to learn flexible continuous dynamics of these influences while simultaneously addressing multiple inference problems, such as density estimation and survival rate computation. We emphasize the significance of disentangling the influences by comparing our framework with state-of-the-art methods on real-life datasets, and provide analysis on the model behavior for potential applications.
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
Apr 12, 2024Large Language Models (LLMs) have dramatically advanced AI applications, yet their deployment remains challenging due to their immense inference costs. Recent studies ameliorate the computational costs of LLMs by increasing their activation sparsity but suffer from significant performance degradation on downstream tasks. In this work, we introduce a new framework for sparsifying the activations of base LLMs and reducing inference costs, dubbed Contextually Aware Thresholding for Sparsity (CATS). CATS is relatively simple, easy to implement, and highly effective. At the heart of our framework is a new non-linear activation function. We demonstrate that CATS can be applied to various base models, including Mistral-7B and Llama2-7B, and outperforms existing sparsification techniques in downstream task performance. More precisely, CATS-based models often achieve downstream task performance within 1-2% of their base models without any fine-tuning and even at activation sparsity levels of 50%. Furthermore, CATS-based models converge faster and display better task performance than competing techniques when fine-tuning is applied. Finally, we develop a custom GPU kernel for efficient implementation of CATS that translates the activation of sparsity of CATS to real wall-clock time speedups. Our custom kernel implementation of CATS results in a ~15% improvement in wall-clock inference latency of token generation on both Llama-7B and Mistral-7B.
TT-SNN: Tensor Train Decomposition for Efficient Spiking Neural Network Training
Jan 15, 2024Spiking Neural Networks (SNNs) have gained significant attention as a potentially energy-efficient alternative for standard neural networks with their sparse binary activation. However, SNNs suffer from memory and computation overhead due to spatio-temporal dynamics and multiple backpropagation computations across timesteps during training. To address this issue, we introduce Tensor Train Decomposition for Spiking Neural Networks (TT-SNN), a method that reduces model size through trainable weight decomposition, resulting in reduced storage, FLOPs, and latency. In addition, we propose a parallel computation pipeline as an alternative to the typical sequential tensor computation, which can be flexibly integrated into various existing SNN architectures. To the best of our knowledge, this is the first of its kind application of tensor decomposition in SNNs. We validate our method using both static and dynamic datasets, CIFAR10/100 and N-Caltech101, respectively. We also propose a TT-SNN-tailored training accelerator to fully harness the parallelism in TT-SNN. Our results demonstrate substantial reductions in parameter size (7.98X), FLOPs (9.25X), training time (17.7%), and training energy (28.3%) during training for the N-Caltech101 dataset, with negligible accuracy degradation.