 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTQv2: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Apr 03, 2025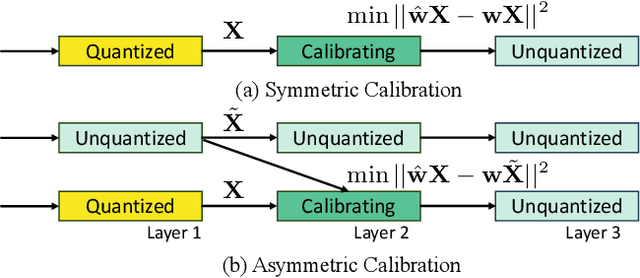
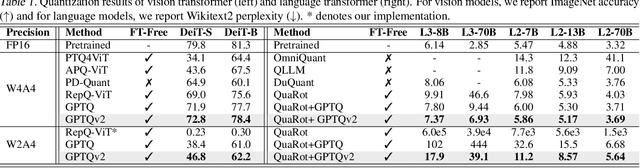
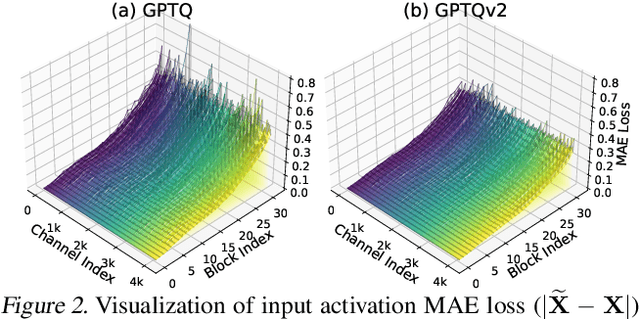
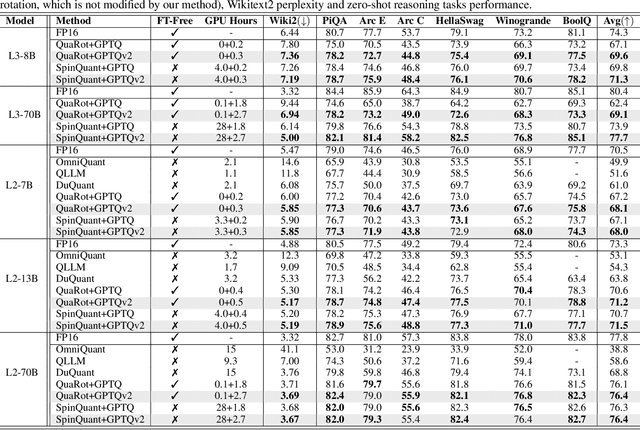
We introduce GPTQv2, a novel finetuning-free quantization method for compressing large-scale transformer architectures. Unlike the previous GPTQ method, which independently calibrates each layer, we always match the quantized layer's output to the exact output in the full-precision model, resulting in a scheme that we call asymmetric calibration. Such a scheme can effectively reduce the quantization error accumulated in previous layers. We analyze this problem using optimal brain compression to derive a close-formed solution. The new solution explicitly minimizes the quantization error as well as the accumulated asymmetry error. Furthermore, we utilize various techniques to parallelize the solution calculation, including channel parallelization, neuron decomposition, and Cholesky reformulation for matrix fusion. As a result, GPTQv2 is easy to implement, simply using 20 more lines of code than GPTQ but improving its performance under low-bit quantization. Remarkably, on a single GPU, we quantize a 405B language transformer as well as EVA-02 the rank first vision transformer that achieves 90% pretraining Imagenet accuracy. Code is available at github.com/Intelligent-Computing-Lab-Yale/GPTQv2.
LoAS: Fully Temporal-Parallel Datatflow for Dual-Sparse Spiking Neural Networks
Jul 19, 2024Spiking Neural Networks (SNNs) have gained significant research attention in the last decade due to their potential to drive resource-constrained edge devices. Though existing SNN accelerators offer high efficiency in processing sparse spikes with dense weights, opportunities are less explored in SNNs with sparse weights, i.e., dual-sparsity. In this work, we study the acceleration of dual-sparse SNNs, focusing on their core operation, sparse-matrix-sparse-matrix multiplication (spMspM). We observe that naively running a dual-sparse SNN on existing spMspM accelerators designed for dual-sparse Artificial Neural Networks (ANNs) exhibits sub-optimal efficiency. The main challenge is that processing timesteps, a natural property of SNNs, introduces an extra loop to ANN spMspM, leading to longer latency and more memory traffic. To address the problem, we propose a fully temporal-parallel (FTP) dataflow, which minimizes both data movement across timesteps and the end-to-end latency of dual-sparse SNNs. To maximize the efficiency of FTP dataflow, we propose an FTP-friendly spike compression mechanism that efficiently compresses single-bit spikes and ensures contiguous memory access. We further propose an FTP-friendly inner-join circuit that can lower the cost of the expensive prefix-sum circuits with almost no throughput penalty. All the above techniques for FTP dataflow are encapsulated in LoAS, a Low-latency inference Accelerator for dual-sparse SNNs. With FTP dataflow, compression, and inner-join, running dual-sparse SNN workloads on LoAS demonstrates significant speedup (up to $8.51\times$) and energy reduction (up to $3.68\times$) compared to running it on prior dual-sparse accelerators.
TT-SNN: Tensor Train Decomposition for Efficient Spiking Neural Network Training
Jan 15, 2024Spiking Neural Networks (SNNs) have gained significant attention as a potentially energy-efficient alternative for standard neural networks with their sparse binary activation. However, SNNs suffer from memory and computation overhead due to spatio-temporal dynamics and multiple backpropagation computations across timesteps during training. To address this issue, we introduce Tensor Train Decomposition for Spiking Neural Networks (TT-SNN), a method that reduces model size through trainable weight decomposition, resulting in reduced storage, FLOPs, and latency. In addition, we propose a parallel computation pipeline as an alternative to the typical sequential tensor computation, which can be flexibly integrated into various existing SNN architectures. To the best of our knowledge, this is the first of its kind application of tensor decomposition in SNNs. We validate our method using both static and dynamic datasets, CIFAR10/100 and N-Caltech101, respectively. We also propose a TT-SNN-tailored training accelerator to fully harness the parallelism in TT-SNN. Our results demonstrate substantial reductions in parameter size (7.98X), FLOPs (9.25X), training time (17.7%), and training energy (28.3%) during training for the N-Caltech101 dataset, with negligible accuracy degradation.
Rethinking Skip Connections in Spiking Neural Networks with Time-To-First-Spike Coding
Dec 01, 2023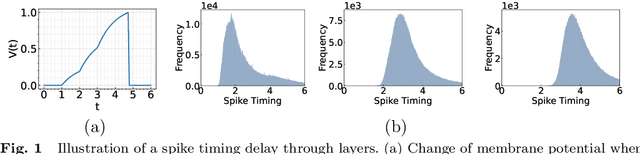

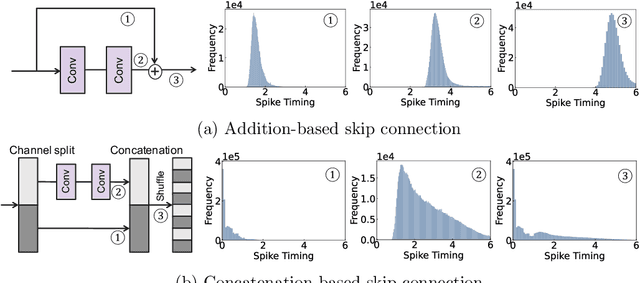

Time-To-First-Spike (TTFS) coding in Spiking Neural Networks (SNNs) offers significant advantages in terms of energy efficiency, closely mimicking the behavior of biological neurons. In this work, we delve into the role of skip connections, a widely used concept in Artificial Neural Networks (ANNs), within the domain of SNNs with TTFS coding. Our focus is on two distinct types of skip connection architectures: (1) addition-based skip connections, and (2) concatenation-based skip connections. We find that addition-based skip connections introduce an additional delay in terms of spike timing. On the other hand, concatenation-based skip connections circumvent this delay but produce time gaps between after-convolution and skip connection paths, thereby restricting the effective mixing of information from these two paths. To mitigate these issues, we propose a novel approach involving a learnable delay for skip connections in the concatenation-based skip connection architecture. This approach successfully bridges the time gap between the convolutional and skip branches, facilitating improved information mixing. We conduct experiments on public datasets including MNIST and Fashion-MNIST, illustrating the advantage of the skip connection in TTFS coding architectures. Additionally, we demonstrate the applicability of TTFS coding on beyond image recognition tasks and extend it to scientific machine-learning tasks, broadening the potential uses of SNNs.
Are SNNs Truly Energy-efficient? $-$ A Hardware Perspective
Sep 06, 2023



Spiking Neural Networks (SNNs) have gained attention for their energy-efficient machine learning capabilities, utilizing bio-inspired activation functions and sparse binary spike-data representations. While recent SNN algorithmic advances achieve high accuracy on large-scale computer vision tasks, their energy-efficiency claims rely on certain impractical estimation metrics. This work studies two hardware benchmarking platforms for large-scale SNN inference, namely SATA and SpikeSim. SATA is a sparsity-aware systolic-array accelerator, while SpikeSim evaluates SNNs implemented on In-Memory Computing (IMC) based analog crossbars. Using these tools, we find that the actual energy-efficiency improvements of recent SNN algorithmic works differ significantly from their estimated values due to various hardware bottlenecks. We identify and address key roadblocks to efficient SNN deployment on hardware, including repeated computations & data movements over timesteps, neuronal module overhead, and vulnerability of SNNs towards crossbar non-idealities.
Sharing Leaky-Integrate-and-Fire Neurons for Memory-Efficient Spiking Neural Networks
May 26, 2023Spiking Neural Networks (SNNs) have gained increasing attention as energy-efficient neural networks owing to their binary and asynchronous computation. However, their non-linear activation, that is Leaky-Integrate-and-Fire (LIF) neuron, requires additional memory to store a membrane voltage to capture the temporal dynamics of spikes. Although the required memory cost for LIF neurons significantly increases as the input dimension goes larger, a technique to reduce memory for LIF neurons has not been explored so far. To address this, we propose a simple and effective solution, EfficientLIF-Net, which shares the LIF neurons across different layers and channels. Our EfficientLIF-Net achieves comparable accuracy with the standard SNNs while bringing up to ~4.3X forward memory efficiency and ~21.9X backward memory efficiency for LIF neurons. We conduct experiments on various datasets including CIFAR10, CIFAR100, TinyImageNet, ImageNet-100, and N-Caltech101. Furthermore, we show that our approach also offers advantages on Human Activity Recognition (HAR) datasets, which heavily rely on temporal information.
MINT: Multiplier-less Integer Quantization for Spiking Neural Networks
May 20, 2023We propose Multiplier-less INTeger (MINT) quantization, an efficient uniform quantization scheme for the weights and membrane potentials in spiking neural networks (SNNs). Unlike prior SNN quantization works, MINT quantizes the memory-hungry membrane potentials to extremely low bit-width (2-bit) to significantly reduce the total memory footprint. Additionally, MINT quantization shares the quantization scale between the weights and membrane potentials, eliminating the need for multipliers and floating arithmetic units, which are required by the standard uniform quantization. Experimental results demonstrate that our proposed method achieves accuracy that matches other state-of-the-art SNN quantization works while outperforming them on total memory footprint and hardware cost at deployment time. For instance, 2-bit MINT VGG-16 achieves 48.6% accuracy on TinyImageNet (0.28% better than the full-precision baseline) with approximately 93.8% reduction in total memory footprint from the full-precision model; meanwhile, our model reduces area by 93% and dynamic power by 98% compared to other SNN quantization counterparts.
Workload-Balanced Pruning for Sparse Spiking Neural Networks
Feb 13, 2023Pruning for Spiking Neural Networks (SNNs) has emerged as a fundamental methodology for deploying deep SNNs on resource-constrained edge devices. Though the existing pruning methods can provide extremely high weight sparsity for deep SNNs, the high weight sparsity brings a workload imbalance problem. Specifically, the workload imbalance happens when a different number of non-zero weights are assigned to hardware units running in parallel, which results in low hardware utilization and thus imposes longer latency and higher energy costs. In preliminary experiments, we show that sparse SNNs ($\sim$98% weight sparsity) can suffer as low as $\sim$59% utilization. To alleviate the workload imbalance problem, we propose u-Ticket, where we monitor and adjust the weight connections of the SNN during Lottery Ticket Hypothesis (LTH) based pruning, thus guaranteeing the final ticket gets optimal utilization when deployed onto the hardware. Experiments indicate that our u-Ticket can guarantee up to 100% hardware utilization, thus reducing up to 76.9% latency and 63.8% energy cost compared to the non-utilization-aware LTH method.
Wearable-based Human Activity Recognition with Spatio-Temporal Spiking Neural Networks
Nov 14, 2022
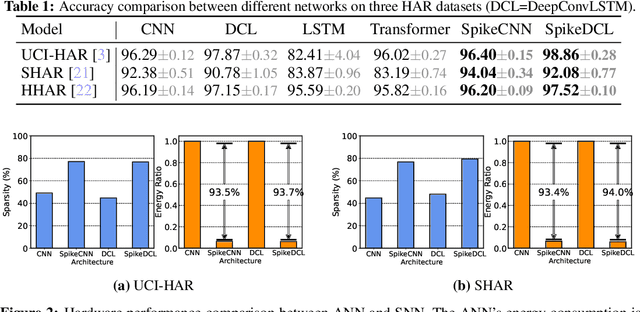
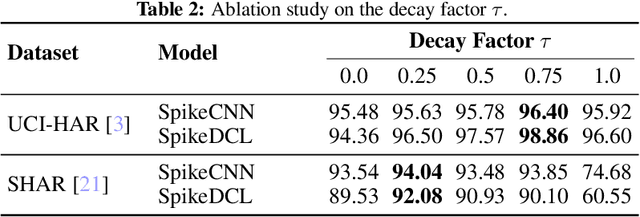
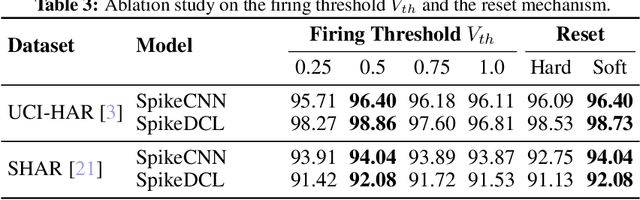
We study the Human Activity Recognition (HAR) task, which predicts user daily activity based on time series data from wearable sensors. Recently, researchers use end-to-end Artificial Neural Networks (ANNs) to extract the features and perform classification in HAR. However, ANNs pose a huge computation burden on wearable devices and lack temporal feature extraction. In this work, we leverage Spiking Neural Networks (SNNs)--an architecture inspired by biological neurons--to HAR tasks. SNNs allow spatio-temporal extraction of features and enjoy low-power computation with binary spikes. We conduct extensive experiments on three HAR datasets with SNNs, demonstrating that SNNs are on par with ANNs in terms of accuracy while reducing up to 94% energy consumption. The code is publicly available in https://github.com/Intelligent-Computing-Lab-Yale/SNN_HAR
Lottery Ticket Hypothesis for Spiking Neural Networks
Jul 04, 2022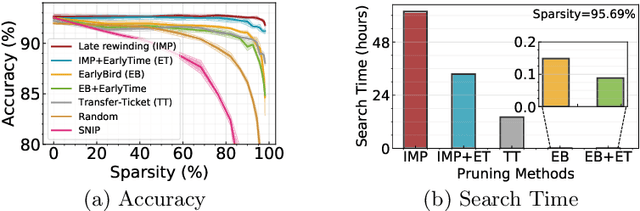
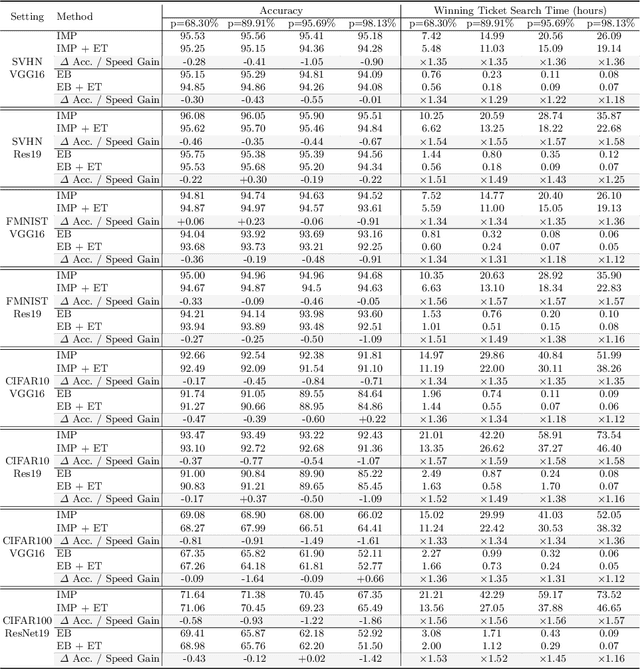
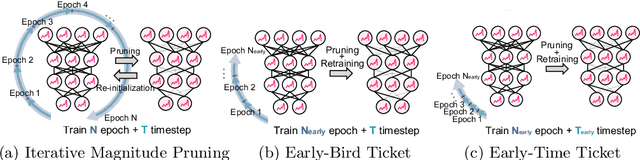
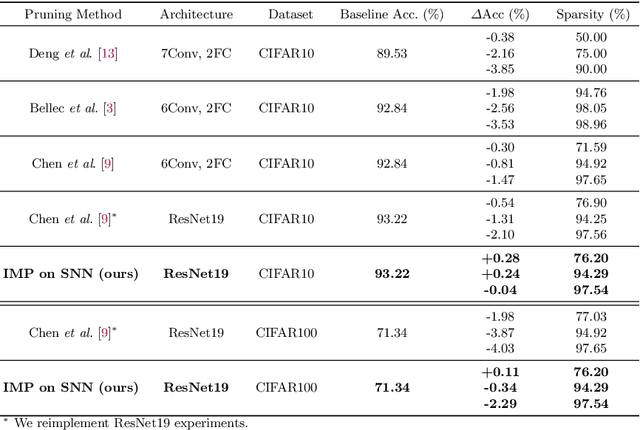
Spiking Neural Networks (SNNs) have recently emerged as a new generation of low-power deep neural networks where binary spikes convey information across multiple timesteps. Pruning for SNNs is highly important as they become deployed on a resource-constraint mobile/edge device. The previous SNN pruning works focus on shallow SNNs (2~6 layers), however, deeper SNNs (>16 layers) are proposed by state-of-the-art SNN works, which is difficult to be compatible with the current pruning work. To scale up a pruning technique toward deep SNNs, we investigate Lottery Ticket Hypothesis (LTH) which states that dense networks contain smaller subnetworks (i.e., winning tickets) that achieve comparable performance to the dense networks. Our studies on LTH reveal that the winning tickets consistently exist in deep SNNs across various datasets and architectures, providing up to 97% sparsity without huge performance degradation. However, the iterative searching process of LTH brings a huge training computational cost when combined with the multiple timesteps of SNNs. To alleviate such heavy searching cost, we propose Early-Time (ET) ticket where we find the important weight connectivity from a smaller number of timesteps. The proposed ET ticket can be seamlessly combined with common pruning techniques for finding winning tickets, such as Iterative Magnitude Pruning (IMP) and Early-Bird (EB) tickets. Our experiment results show that the proposed ET ticket reduces search time by up to 38% compared to IMP or EB methods.