 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTQv2: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Apr 03, 2025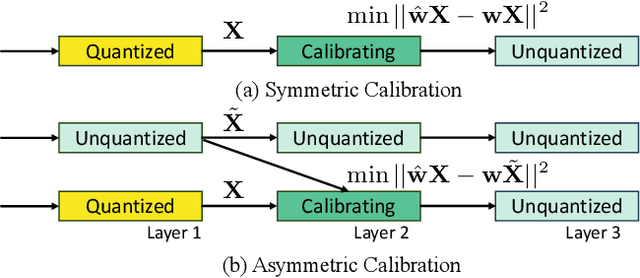
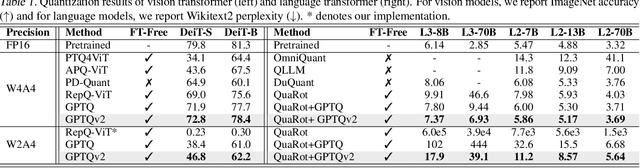
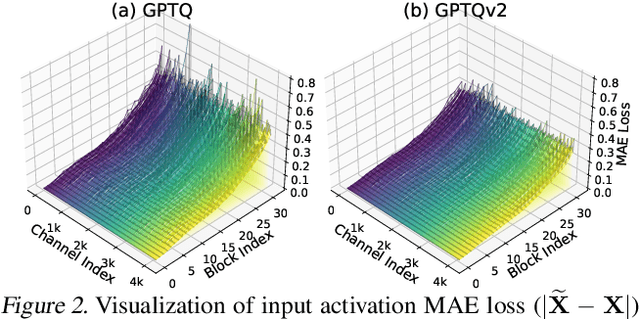
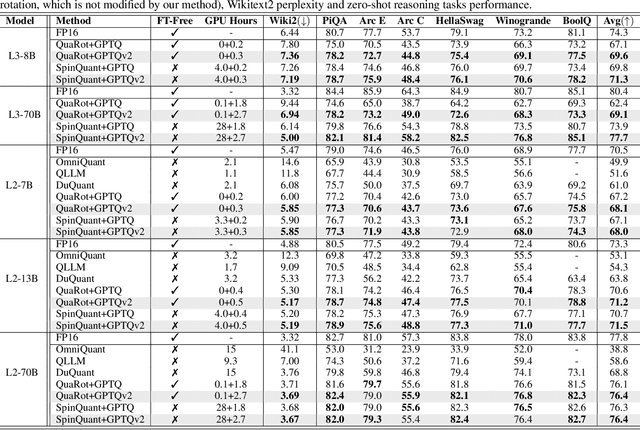
We introduce GPTQv2, a novel finetuning-free quantization method for compressing large-scale transformer architectures. Unlike the previous GPTQ method, which independently calibrates each layer, we always match the quantized layer's output to the exact output in the full-precision model, resulting in a scheme that we call asymmetric calibration. Such a scheme can effectively reduce the quantization error accumulated in previous layers. We analyze this problem using optimal brain compression to derive a close-formed solution. The new solution explicitly minimizes the quantization error as well as the accumulated asymmetry error. Furthermore, we utilize various techniques to parallelize the solution calculation, including channel parallelization, neuron decomposition, and Cholesky reformulation for matrix fusion. As a result, GPTQv2 is easy to implement, simply using 20 more lines of code than GPTQ but improving its performance under low-bit quantization. Remarkably, on a single GPU, we quantize a 405B language transformer as well as EVA-02 the rank first vision transformer that achieves 90% pretraining Imagenet accuracy. Code is available at github.com/Intelligent-Computing-Lab-Yale/GPTQv2.
Spiking Transformer with Spatial-Temporal Attention
Sep 29, 2024



Spiking Neural Networks (SNNs) present a compelling and energy-efficient alternative to traditional Artificial Neural Networks (ANNs) due to their sparse binary activation. Leveraging the success of the transformer architecture, the spiking transformer architecture is explored to scale up dataset size and performance. However, existing works only consider the spatial self-attention in spiking transformer, neglecting the inherent temporal context across the timesteps. In this work, we introduce Spiking Transformer with Spatial-Temporal Attention (STAtten), a simple and straightforward architecture designed to integrate spatial and temporal information in self-attention with negligible additional computational load. The STAtten divides the temporal or token index and calculates the self-attention in a cross-manner to effectively incorporate spatial-temporal information. We first verify our spatial-temporal attention mechanism's ability to capture long-term temporal dependencies using sequential datasets. Moreover, we validate our approach through extensive experiments on varied datasets, including CIFAR10/100, ImageNet, CIFAR10-DVS, and N-Caltech101. Notably, our cross-attention mechanism achieves an accuracy of 78.39 % on the ImageNet dataset.
ReSpike: Residual Frames-based Hybrid Spiking Neural Networks for Efficient Action Recognition
Sep 03, 2024Spiking Neural Networks (SNNs) have emerged as a compelling, energy-efficient alternative to traditional Artificial Neural Networks (ANNs) for static image tasks such as image classification and segmentation. However, in the more complex video classification domain, SNN-based methods fall considerably short of ANN-based benchmarks due to the challenges in processing dense frame sequences. To bridge this gap, we propose ReSpike, a hybrid framework that synergizes the strengths of ANNs and SNNs to tackle action recognition tasks with high accuracy and low energy cost. By decomposing film clips into spatial and temporal components, i.e., RGB image Key Frames and event-like Residual Frames, ReSpike leverages ANN for learning spatial information and SNN for learning temporal information. In addition, we propose a multi-scale cross-attention mechanism for effective feature fusion. Compared to state-of-the-art SNN baselines, our ReSpike hybrid architecture demonstrates significant performance improvements (e.g., >30% absolute accuracy improvement on HMDB-51, UCF-101, and Kinetics-400). Furthermore, ReSpike achieves comparable performance with prior ANN approaches while bringing better accuracy-energy tradeoff.
An objective comparison of methods for augmented reality in laparoscopic liver resection by preoperative-to-intraoperative image fusion
Feb 07, 2024



Augmented reality for laparoscopic liver resection is a visualisation mode that allows a surgeon to localise tumours and vessels embedded within the liver by projecting them on top of a laparoscopic image. Preoperative 3D models extracted from CT or MRI data are registered to the intraoperative laparoscopic images during this process. In terms of 3D-2D fusion, most of the algorithms make use of anatomical landmarks to guide registration. These landmarks include the liver's inferior ridge, the falciform ligament, and the occluding contours. They are usually marked by hand in both the laparoscopic image and the 3D model, which is time-consuming and may contain errors if done by a non-experienced user. Therefore, there is a need to automate this process so that augmented reality can be used effectively in the operating room. We present the Preoperative-to-Intraoperative Laparoscopic Fusion Challenge (P2ILF), held during the Medical Imaging and Computer Assisted Interventions (MICCAI 2022) conference, which investigates the possibilities of detecting these landmarks automatically and using them in registration. The challenge was divided into two tasks: 1) A 2D and 3D landmark detection task and 2) a 3D-2D registration task. The teams were provided with training data consisting of 167 laparoscopic images and 9 preoperative 3D models from 9 patients, with the corresponding 2D and 3D landmark annotations. A total of 6 teams from 4 countries participated, whose proposed methods were evaluated on 16 images and two preoperative 3D models from two patients. All the teams proposed deep learning-based methods for the 2D and 3D landmark segmentation tasks and differentiable rendering-based methods for the registration task. Based on the experimental outcomes, we propose three key hypotheses that determine current limitations and future directions for research in this domain.
Multi-view Tracking, Re-ID, and Social Network Analysis of a Flock of Visually Similar Birds in an Outdoor Aviary
Dec 01, 2022The ability to capture detailed interactions among individuals in a social group is foundational to our study of animal behavior and neuroscience. Recent advances in deep learning and computer vision are driving rapid progress in methods that can record the actions and interactions of multiple individuals simultaneously. Many social species, such as birds, however, live deeply embedded in a three-dimensional world. This world introduces additional perceptual challenges such as occlusions, orientation-dependent appearance, large variation in apparent size, and poor sensor coverage for 3D reconstruction, that are not encountered by applications studying animals that move and interact only on 2D planes. Here we introduce a system for studying the behavioral dynamics of a group of songbirds as they move throughout a 3D aviary. We study the complexities that arise when tracking a group of closely interacting animals in three dimensions and introduce a novel dataset for evaluating multi-view trackers. Finally, we analyze captured ethogram data and demonstrate that social context affects the distribution of sequential interactions between birds in the aviary.