 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Emulator Design and Training for Modal Aerosol Microphysics Parameterizations in E3SMv2
Apr 23, 2026Toward the goal of using Scientific Machine Learning (SciML) emulators to improve the numerical representation of aerosol processes in global atmospheric models, we explore the emulation of aerosol microphysics processes under cloud-free conditions in the 4-mode Modal Aerosol Module (MAM4) within the Energy Exascale Earth System Model version 2 (E3SMv2). To develop an in-depth understanding of the challenges and opportunities in applying SciML to aerosol processes, we begin with a simple feedforward neural network architecture that has been used in earlier studies, but we systematically examine key emulator design choices, including architecture complexity and variable normalization, while closely monitoring training convergence behavior. Our results show that optimization convergence, scaling strategy, and network complexity strongly influence emulation accuracy. When effective scaling is applied and convergence is achieved, the relatively simple architecture, used together with a moderate network size, can reproduce key features of the microphysics-induced aerosol concentration changes with promising accuracy. These findings provide practical clues for the next stages of emulator development; they also provide general insights that are likely applicable to the emulation of other aerosol processes, as well as other atmospheric physics involving multi-scale variability.
SINDy-KANs: Sparse identification of non-linear dynamics through Kolmogorov-Arnold networks
Mar 19, 2026Kolmogorov-Arnold networks (KANs) have arisen as a potential way to enhance the interpretability of machine learning. However, solutions learned by KANs are not necessarily interpretable, in the sense of being sparse or parsimonious. Sparse identification of nonlinear dynamics (SINDy) is a complementary approach that allows for learning sparse equations for dynamical systems from data; however, learned equations are limited by the library. In this work, we present SINDy-KANs, which simultaneously train a KAN and a SINDy-like representation to increase interpretability of KAN representations with SINDy applied at the level of each activation function, while maintaining the function compositions possible through deep KANs. We apply our method to a number of symbolic regression tasks, including dynamical systems, to show accurate equation discovery across a range of systems.
Enhancing classification accuracy through chaos
Mar 16, 2026We propose a novel approach which exploits chaos to enhance classification accuracy. Specifically, the available data that need to be classified are treated as vectors that are first lifted into a higher-dimensional space and then used as initial conditions for the evolution of a chaotic dynamical system for a prescribed temporal interval. The evolved state of the dynamical system is then fed to a trainable softmax classifier which outputs the probabilities of the various classes. As proof-of-concept, we use samples of randomly perturbed orthogonal vectors of moderate dimension (2 to 20), with a corresponding number of classes equal to the vector dimension, and show how our approach can both significantly accelerate the training process and improve the classification accuracy compared to a standard softmax classifier which operates on the original vectors, as well as a softmax classifier which only lifts the vectors to a higher-dimensional space without evolving them. We also provide an explanation for the improved performance of the chaos-enhanced classifier.
Improving the accuracy of physics-informed neural networks via last-layer retraining
Mar 04, 2026Physics-informed neural networks (PINNs) are a versatile tool in the burgeoning field of scientific machine learning for solving partial differential equations (PDEs). However, determining suitable training strategies for them is not obvious, with the result that they typically yield moderately accurate solutions. In this article, we propose a method for improving the accuracy of PINNs by coupling them with a post-processing step that seeks the best approximation in a function space associated with the network. We find that our method yields errors four to five orders of magnitude lower than those of the parent PINNs across architectures and dimensions. Moreover, we can reuse the basis functions for the linear space in more complex settings, such as time-dependent and nonlinear problems, allowing for transfer learning. Out approach also provides a residual-based metric that allows us to optimally choose the number of basis functions employed.
ArGEnT: Arbitrary Geometry-encoded Transformer for Operator Learning
Feb 12, 2026Learning solution operators for systems with complex, varying geometries and parametric physical settings is a central challenge in scientific machine learning. In many-query regimes such as design optimization, control and inverse problems, surrogate modeling must generalize across geometries while allowing flexible evaluation at arbitrary spatial locations. In this work, we propose Arbitrary Geometry-encoded Transformer (ArGEnT), a geometry-aware attention-based architecture for operator learning on arbitrary domains. ArGEnT employs Transformer attention mechanisms to encode geometric information directly from point-cloud representations with three variants-self-attention, cross-attention, and hybrid-attention-that incorporates different strategies for incorporating geometric features. By integrating ArGEnT into DeepONet as the trunk network, we develop a surrogate modeling framework capable of learning operator mappings that depend on both geometric and non-geometric inputs without the need to explicitly parametrize geometry as a branch network input. Evaluation on benchmark problems spanning fluid dynamics, solid mechanics and electrochemical systems, we demonstrate significantly improved prediction accuracy and generalization performance compared with the standard DeepONet and other existing geometry-aware saurrogates. In particular, the cross-attention transformer variant enables accurate geometry-conditioned predictions with reduced reliance on signed distance functions. By combining flexible geometry encoding with operator-learning capabilities, ArGEnT provides a scalable surrogate modeling framework for optimization, uncertainty quantification, and data-driven modeling of complex physical systems.
From LIF to QIF: Toward Differentiable Spiking Neurons for Scientific Machine Learning
Nov 10, 2025Spiking neural networks (SNNs) offer biologically inspired computation but remain underexplored for continuous regression tasks in scientific machine learning. In this work, we introduce and systematically evaluate Quadratic Integrate-and-Fire (QIF) neurons as an alternative to the conventional Leaky Integrate-and-Fire (LIF) model in both directly trained SNNs and ANN-to-SNN conversion frameworks. The QIF neuron exhibits smooth and differentiable spiking dynamics, enabling gradient-based training and stable optimization within architectures such as multilayer perceptrons (MLPs), Deep Operator Networks (DeepONets), and Physics-Informed Neural Networks (PINNs). Across benchmarks on function approximation, operator learning, and partial differential equation (PDE) solving, QIF-based networks yield smoother, more accurate, and more stable predictions than their LIF counterparts, which suffer from discontinuous time-step responses and jagged activation surfaces. These results position the QIF neuron as a computational bridge between spiking and continuous-valued deep learning, advancing the integration of neuroscience-inspired dynamics into physics-informed and operator-learning frameworks.
Self-adaptive weighting and sampling for physics-informed neural networks
Nov 07, 2025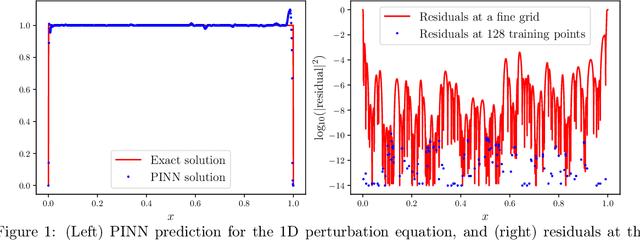
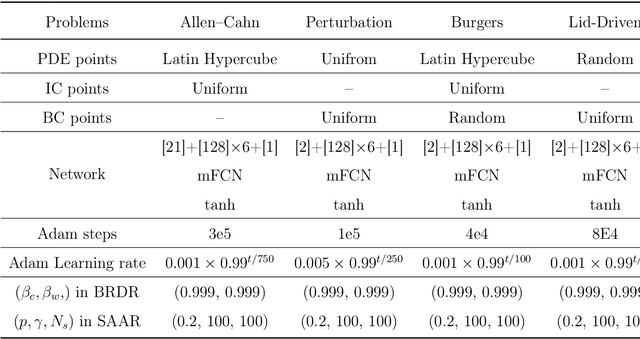
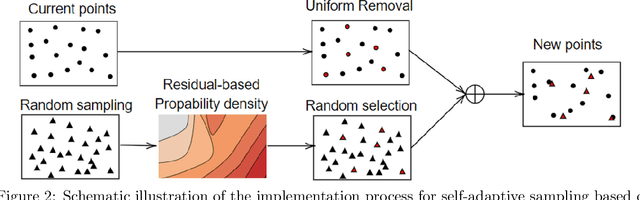
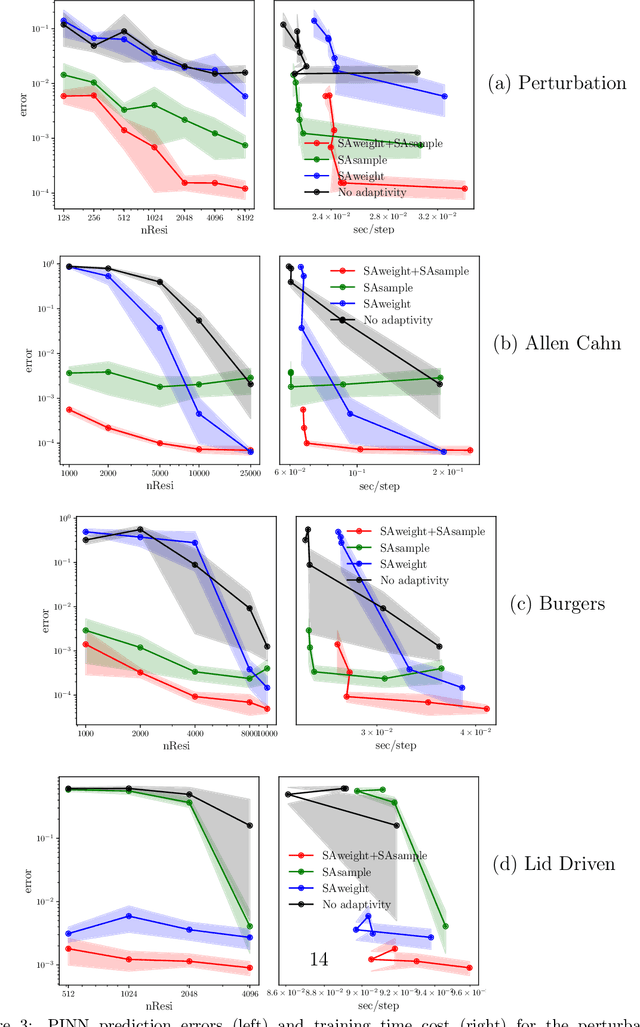
Physics-informed deep learning has emerged as a promising framework for solving partial differential equations (PDEs). Nevertheless, training these models on complex problems remains challenging, often leading to limited accuracy and efficiency. In this work, we introduce a hybrid adaptive sampling and weighting method to enhance the performance of physics-informed neural networks (PINNs). The adaptive sampling component identifies training points in regions where the solution exhibits rapid variation, while the adaptive weighting component balances the convergence rate across training points. Numerical experiments show that applying only adaptive sampling or only adaptive weighting is insufficient to consistently achieve accurate predictions, particularly when training points are scarce. Since each method emphasizes different aspects of the solution, their effectiveness is problem dependent. By combining both strategies, the proposed framework consistently improves prediction accuracy and training efficiency, offering a more robust approach for solving PDEs with PINNs.
Physics-Informed DeepONet Coupled with FEM for Convective Transport in Porous Media with Sharp Gaussian Sources
Aug 27, 2025We present a hybrid framework that couples finite element methods (FEM) with physics-informed DeepONet to model fluid transport in porous media from sharp, localized Gaussian sources. The governing system consists of a steady-state Darcy flow equation and a time-dependent convection-diffusion equation. Our approach solves the Darcy system using FEM and transfers the resulting velocity field to a physics-informed DeepONet, which learns the mapping from source functions to solute concentration profiles. This modular strategy preserves FEM-level accuracy in the flow field while enabling fast inference for transport dynamics. To handle steep gradients induced by sharp sources, we introduce an adaptive sampling strategy for trunk collocation points. Numerical experiments demonstrate that our method is in good agreement with the reference solutions while offering orders of magnitude speedups over traditional solvers, making it suitable for practical applications in relevant scenarios. Implementation of our proposed method is available at https://github.com/erkara/fem-pi-deeponet.
Stabilizing PDE--ML Coupled System
Jun 24, 2025A long-standing obstacle in the use of machine-learnt surrogates with larger PDE systems is the onset of instabilities when solved numerically. Efforts towards ameliorating these have mostly concentrated on improving the accuracy of the surrogates or imbuing them with additional structure, and have garnered limited success. In this article, we study a prototype problem and draw insights that can help with more complex systems. In particular, we focus on a viscous Burgers'-ML system and, after identifying the cause of the instabilities, prescribe strategies to stabilize the coupled system. To improve the accuracy of the stabilized system, we next explore methods based on the Mori--Zwanzig formalism.
Conformalized-KANs: Uncertainty Quantification with Coverage Guarantees for Kolmogorov-Arnold Networks (KANs) in Scientific Machine Learning
Apr 21, 2025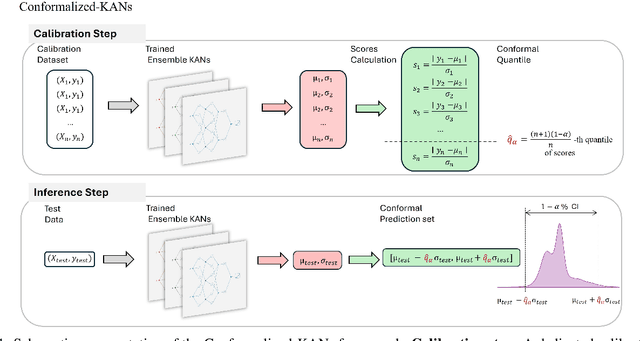

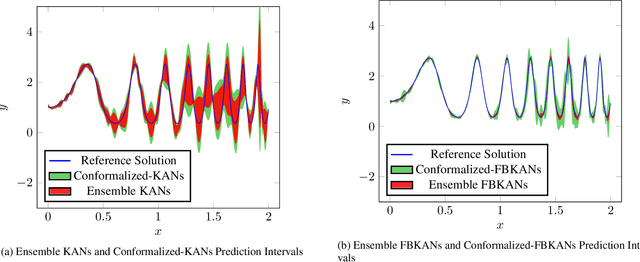

This paper explores uncertainty quantification (UQ) methods in the context of Kolmogorov-Arnold Networks (KANs). We apply an ensemble approach to KANs to obtain a heuristic measure of UQ, enhancing interpretability and robustness in modeling complex functions. Building on this, we introduce Conformalized-KANs, which integrate conformal prediction, a distribution-free UQ technique, with KAN ensembles to generate calibrated prediction intervals with guaranteed coverage. Extensive numerical experiments are conducted to evaluate the effectiveness of these methods, focusing particularly on the robustness and accuracy of the prediction intervals under various hyperparameter settings. We show that the conformal KAN predictions can be applied to recent extensions of KANs, including Finite Basis KANs (FBKANs) and multifideilty KANs (MFKANs). The results demonstrate the potential of our approaches to improve the reliability and applicability of KANs in scientific machine learning.