 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the accuracy of physics-informed neural networks via last-layer retraining
Mar 04, 2026Physics-informed neural networks (PINNs) are a versatile tool in the burgeoning field of scientific machine learning for solving partial differential equations (PDEs). However, determining suitable training strategies for them is not obvious, with the result that they typically yield moderately accurate solutions. In this article, we propose a method for improving the accuracy of PINNs by coupling them with a post-processing step that seeks the best approximation in a function space associated with the network. We find that our method yields errors four to five orders of magnitude lower than those of the parent PINNs across architectures and dimensions. Moreover, we can reuse the basis functions for the linear space in more complex settings, such as time-dependent and nonlinear problems, allowing for transfer learning. Out approach also provides a residual-based metric that allows us to optimally choose the number of basis functions employed.
Stabilizing PDE--ML Coupled System
Jun 24, 2025A long-standing obstacle in the use of machine-learnt surrogates with larger PDE systems is the onset of instabilities when solved numerically. Efforts towards ameliorating these have mostly concentrated on improving the accuracy of the surrogates or imbuing them with additional structure, and have garnered limited success. In this article, we study a prototype problem and draw insights that can help with more complex systems. In particular, we focus on a viscous Burgers'-ML system and, after identifying the cause of the instabilities, prescribe strategies to stabilize the coupled system. To improve the accuracy of the stabilized system, we next explore methods based on the Mori--Zwanzig formalism.
Efficient kernel surrogates for neural network-based regression
Oct 28, 2023



Despite their immense promise in performing a variety of learning tasks, a theoretical understanding of the effectiveness and limitations of Deep Neural Networks (DNNs) has so far eluded practitioners. This is partly due to the inability to determine the closed forms of the learned functions, making it harder to assess their precise dependence on the training data and to study their generalization properties on unseen datasets. Recent work has shown that randomly initialized DNNs in the infinite width limit converge to kernel machines relying on a Neural Tangent Kernel (NTK) with known closed form. These results suggest, and experimental evidence corroborates, that empirical kernel machines can also act as surrogates for finite width DNNs. The high computational cost of assembling the full NTK, however, makes this approach infeasible in practice, motivating the need for low-cost approximations. In the current work, we study the performance of the Conjugate Kernel (CK), an efficient approximation to the NTK that has been observed to yield fairly similar results. For the regression problem of smooth functions and classification using logistic regression, we show that the CK performance is only marginally worse than that of the NTK and, in certain cases, is shown to be superior. In particular, we establish bounds for the relative test losses, verify them with numerical tests, and identify the regularity of the kernel as the key determinant of performance. In addition to providing a theoretical grounding for using CKs instead of NTKs, our framework provides insights into understanding the robustness of the various approximants and suggests a recipe for improving DNN accuracy inexpensively. We present a demonstration of this on the foundation model GPT-2 by comparing its performance on a classification task using a conventional approach and our prescription.
Machine-learning custom-made basis functions for partial differential equations
Nov 09, 2021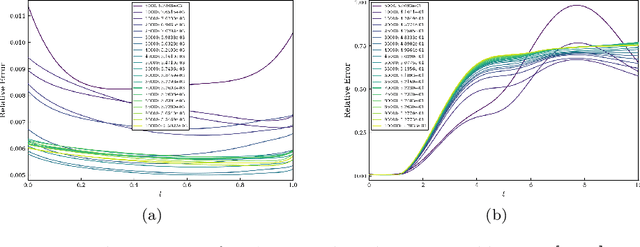
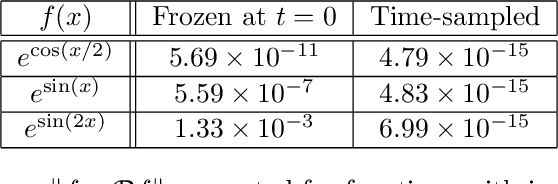
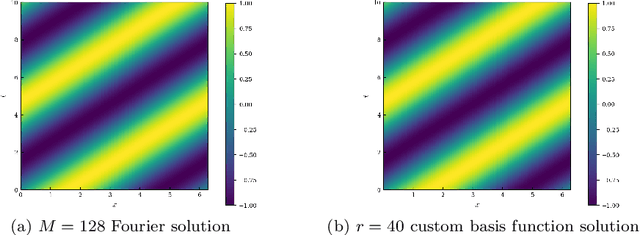
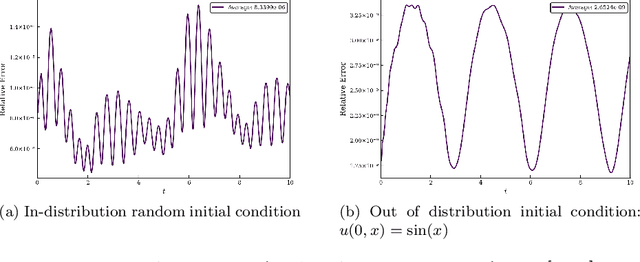
Spectral methods are an important part of scientific computing's arsenal for solving partial differential equations (PDEs). However, their applicability and effectiveness depend crucially on the choice of basis functions used to expand the solution of a PDE. The last decade has seen the emergence of deep learning as a strong contender in providing efficient representations of complex functions. In the current work, we present an approach for combining deep neural networks with spectral methods to solve PDEs. In particular, we use a deep learning technique known as the Deep Operator Network (DeepONet), to identify candidate functions on which to expand the solution of PDEs. We have devised an approach which uses the candidate functions provided by the DeepONet as a starting point to construct a set of functions which have the following properties: i) they constitute a basis, 2) they are orthonormal, and 3) they are hierarchical i.e., akin to Fourier series or orthogonal polynomials. We have exploited the favorable properties of our custom-made basis functions to both study their approximation capability and use them to expand the solution of linear and nonlinear time-dependent PDEs.