 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken embeddings violate the manifold hypothesis
Apr 01, 2025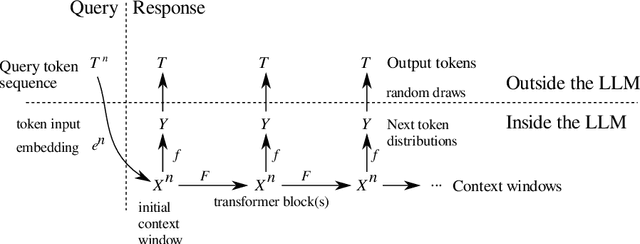
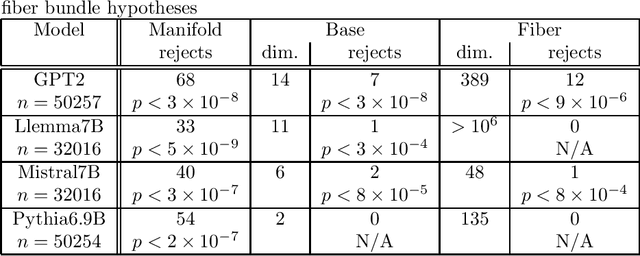
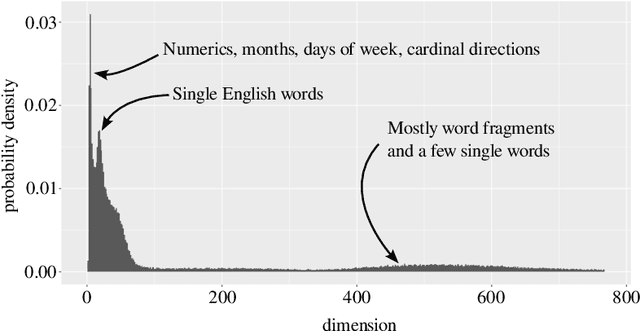
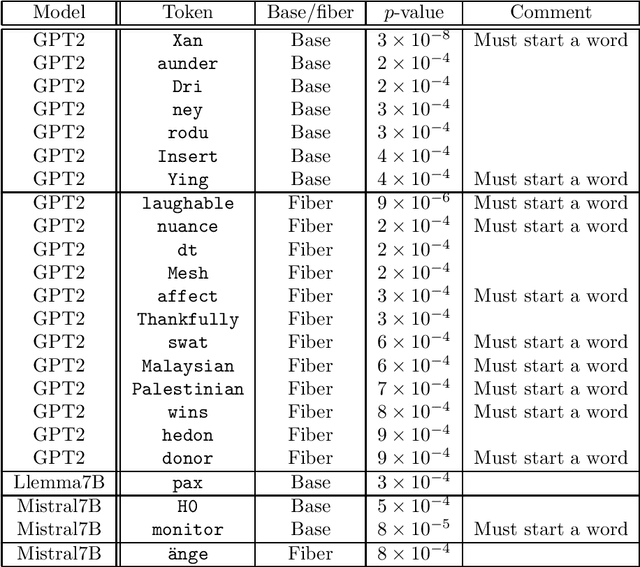
To fully understand the behavior of a large language model (LLM) requires our understanding of its input space. If this input space differs from our assumption, our understanding of and conclusions about the LLM is likely flawed, regardless of its architecture. Here, we elucidate the structure of the token embeddings, the input domain for LLMs, both empirically and theoretically. We present a generalized and statistically testable model where the neighborhood of each token splits into well-defined signal and noise dimensions. This model is based on a generalization of a manifold called a fiber bundle, so we denote our hypothesis test as the ``fiber bundle null.'' Failing to reject the null is uninformative, but rejecting it at a specific token indicates that token has a statistically significant local structure, and so is of interest to us. By running our test over several open-source LLMs, each with unique token embeddings, we find that the null is frequently rejected, and so the token subspace is provably not a fiber bundle and hence also not a manifold. As a consequence of our findings, when an LLM is presented with two semantically equivalent prompts, and if one prompt contains a token implicated by our test, that prompt will likely exhibit more output variability proportional to the local signal dimension of the token.
Assessing Generative Models for Structured Data
Mar 26, 2025



Synthetic tabular data generation has emerged as a promising method to address limited data availability and privacy concerns. With the sharp increase in the performance of large language models in recent years, researchers have been interested in applying these models to the generation of tabular data. However, little is known about the quality of the generated tabular data from large language models. The predominant method for assessing the quality of synthetic tabular data is the train-synthetic-test-real approach, where the artificial examples are compared to the original by how well machine learning models, trained separately on the real and synthetic sets, perform in some downstream tasks. This method does not directly measure how closely the distribution of generated data approximates that of the original. This paper introduces rigorous methods for directly assessing synthetic tabular data against real data by looking at inter-column dependencies within the data. We find that large language models (GPT-2), both when queried via few-shot prompting and when fine-tuned, and GAN (CTGAN) models do not produce data with dependencies that mirror the original real data. Results from this study can inform future practice in synthetic data generation to improve data quality.
Understanding Generative AI Content with Embedding Models
Aug 19, 2024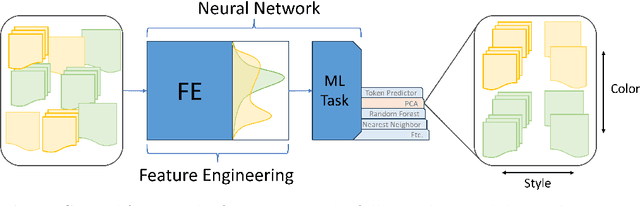

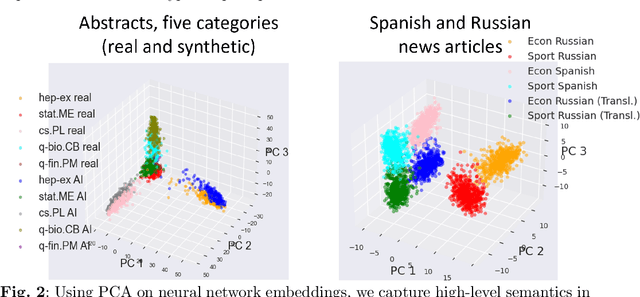
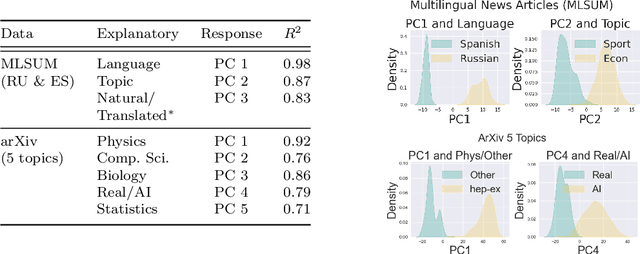
The construction of high-quality numerical features is critical to any quantitative data analysis. Feature engineering has been historically addressed by carefully hand-crafting data representations based on domain expertise. This work views the internal representations of modern deep neural networks (DNNs), called embeddings, as an automated form of traditional feature engineering. For trained DNNs, we show that these embeddings can reveal interpretable, high-level concepts in unstructured sample data. We use these embeddings in natural language and computer vision tasks to uncover both inherent heterogeneity in the underlying data and human-understandable explanations for it. In particular, we find empirical evidence that there is inherent separability between real data and that generated from AI models.
Measuring model variability using robust non-parametric testing
Jun 12, 2024



Training a deep neural network often involves stochastic optimization, meaning each run will produce a different model. The seed used to initialize random elements of the optimization procedure heavily influences the quality of a trained model, which may be obscure from many commonly reported summary statistics, like accuracy. However, random seed is often not included in hyper-parameter optimization, perhaps because the relationship between seed and model quality is hard to describe. This work attempts to describe the relationship between deep net models trained with different random seeds and the behavior of the expected model. We adopt robust hypothesis testing to propose a novel summary statistic for network similarity, referred to as the $\alpha$-trimming level. We use the $\alpha$-trimming level to show that the empirical cumulative distribution function of an ensemble model created from a collection of trained models with different random seeds approximates the average of these functions as the number of models in the collection grows large. This insight provides guidance for how many random seeds should be sampled to ensure that an ensemble of these trained models is a reliable representative. We also show that the $\alpha$-trimming level is more expressive than different performance metrics like validation accuracy, churn, or expected calibration error when taken alone and may help with random seed selection in a more principled fashion. We demonstrate the value of the proposed statistic in real experiments and illustrate the advantage of fine-tuning over random seed with an experiment in transfer learning.
Efficient kernel surrogates for neural network-based regression
Oct 28, 2023



Despite their immense promise in performing a variety of learning tasks, a theoretical understanding of the effectiveness and limitations of Deep Neural Networks (DNNs) has so far eluded practitioners. This is partly due to the inability to determine the closed forms of the learned functions, making it harder to assess their precise dependence on the training data and to study their generalization properties on unseen datasets. Recent work has shown that randomly initialized DNNs in the infinite width limit converge to kernel machines relying on a Neural Tangent Kernel (NTK) with known closed form. These results suggest, and experimental evidence corroborates, that empirical kernel machines can also act as surrogates for finite width DNNs. The high computational cost of assembling the full NTK, however, makes this approach infeasible in practice, motivating the need for low-cost approximations. In the current work, we study the performance of the Conjugate Kernel (CK), an efficient approximation to the NTK that has been observed to yield fairly similar results. For the regression problem of smooth functions and classification using logistic regression, we show that the CK performance is only marginally worse than that of the NTK and, in certain cases, is shown to be superior. In particular, we establish bounds for the relative test losses, verify them with numerical tests, and identify the regularity of the kernel as the key determinant of performance. In addition to providing a theoretical grounding for using CKs instead of NTKs, our framework provides insights into understanding the robustness of the various approximants and suggests a recipe for improving DNN accuracy inexpensively. We present a demonstration of this on the foundation model GPT-2 by comparing its performance on a classification task using a conventional approach and our prescription.
Foundation Model's Embedded Representations May Detect Distribution Shift
Oct 20, 2023



Distribution shifts between train and test datasets obscure our ability to understand the generalization capacity of neural network models. This topic is especially relevant given the success of pre-trained foundation models as starting points for transfer learning (TL) models across tasks and contexts. We present a case study for TL on a pre-trained GPT-2 model onto the Sentiment140 dataset for sentiment classification. We show that Sentiment140's test dataset $M$ is not sampled from the same distribution as the training dataset $P$, and hence training on $P$ and measuring performance on $M$ does not actually account for the model's generalization on sentiment classification.
Robust Nonparametric Hypothesis Testing to Understand Variability in Training Neural Networks
Oct 01, 2023



Training a deep neural network (DNN) often involves stochastic optimization, which means each run will produce a different model. Several works suggest this variability is negligible when models have the same performance, which in the case of classification is test accuracy. However, models with similar test accuracy may not be computing the same function. We propose a new measure of closeness between classification models based on the output of the network before thresholding. Our measure is based on a robust hypothesis-testing framework and can be adapted to other quantities derived from trained models.
Exploring Learned Representations of Neural Networks with Principal Component Analysis
Sep 27, 2023


Understanding feature representation for deep neural networks (DNNs) remains an open question within the general field of explainable AI. We use principal component analysis (PCA) to study the performance of a k-nearest neighbors classifier (k-NN), nearest class-centers classifier (NCC), and support vector machines on the learned layer-wise representations of a ResNet-18 trained on CIFAR-10. We show that in certain layers, as little as 20% of the intermediate feature-space variance is necessary for high-accuracy classification and that across all layers, the first ~100 PCs completely determine the performance of the k-NN and NCC classifiers. We relate our findings to neural collapse and provide partial evidence for the related phenomenon of intermediate neural collapse. Our preliminary work provides three distinct yet interpretable surrogate models for feature representation with an affine linear model the best performing. We also show that leveraging several surrogate models affords us a clever method to estimate where neural collapse may initially occur within the DNN.
Robust Explanations for Deep Neural Networks via Pseudo Neural Tangent Kernel Surrogate Models
May 23, 2023
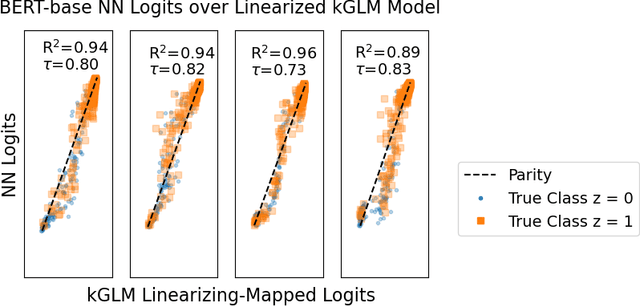
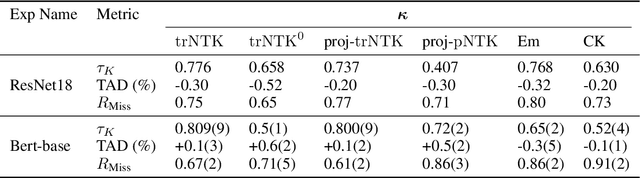
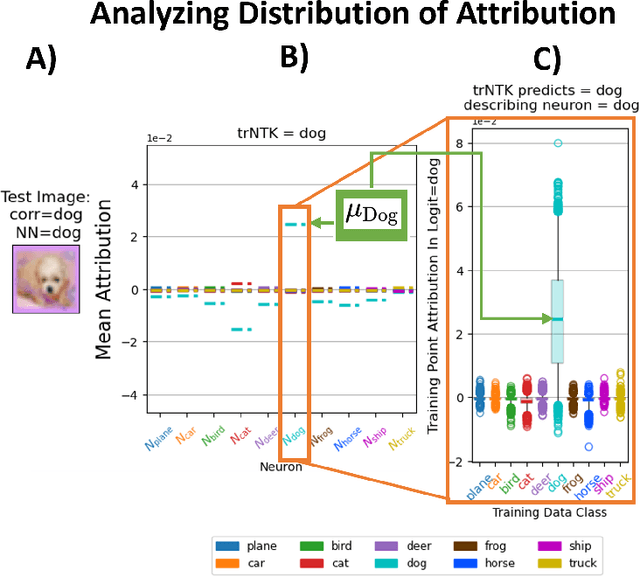
One of the ways recent progress has been made on explainable AI has been via explain-by-example strategies, specifically, through data attribution tasks. The feature spaces used to attribute decisions to training data, however, have not been compared against one another as to whether they form a truly representative surrogate model of the neural network (NN). Here, we demonstrate the efficacy of surrogate linear feature spaces to neural networks through two means: (1) we establish that a normalized psuedo neural tangent kernel (pNTK) is more correlated to the neural network decision functions than embedding based and influence based alternatives in both computer vision and large language model architectures; (2) we show that the attributions created from the normalized pNTK more accurately select perturbed training data in a data poisoning attribution task than these alternatives. Based on these observations, we conclude that kernel linear models are effective surrogate models across multiple classification architectures and that pNTK-based kernels are the most appropriate surrogate feature space of all kernels studied.
Spectral evolution and invariance in linear-width neural networks
Nov 11, 2022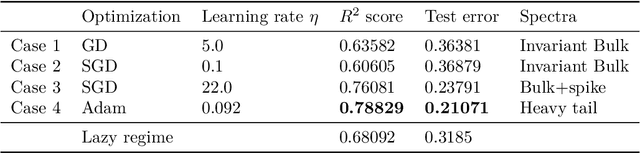



We investigate the spectral properties of linear-width feed-forward neural networks, where the sample size is asymptotically proportional to network width. Empirically, we show that the weight spectra in this high dimensional regime are invariant when trained by gradient descent for small constant learning rates and the changes in both operator and Frobenius norm are $\Theta(1)$ in the limit. This implies the bulk spectra for both the conjugate and neural tangent kernels are also invariant. We demonstrate similar characteristics for models trained with mini-batch (stochastic) gradient descent with small learning rates and provide a theoretical justification for this special scenario. When the learning rate is large, we show empirically that an outlier emerges with its corresponding eigenvector aligned to the training data structure. We also show that after adaptive gradient training, where we have a lower test error and feature learning emerges, both the weight and kernel matrices exhibit heavy tail behavior. Different spectral properties such as invariant bulk, spike, and heavy-tailed distribution correlate to how far the kernels deviate from initialization. To understand this phenomenon better, we focus on a toy model, a two-layer network on synthetic data, which exhibits different spectral properties for different training strategies. Analogous phenomena also appear when we train conventional neural networks with real-world data. Our results show that monitoring the evolution of the spectra during training is an important step toward understanding the training dynamics and feature learning.