 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken embeddings violate the manifold hypothesis
Apr 01, 2025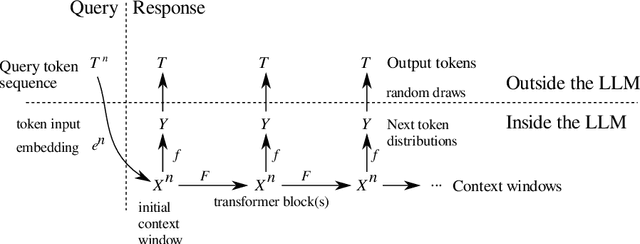
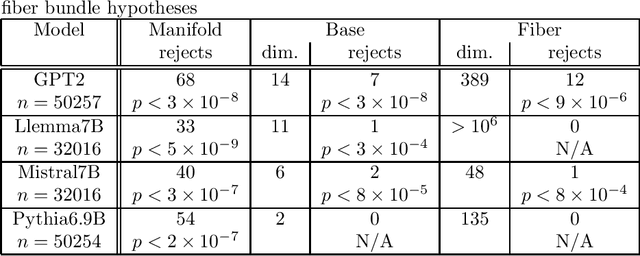
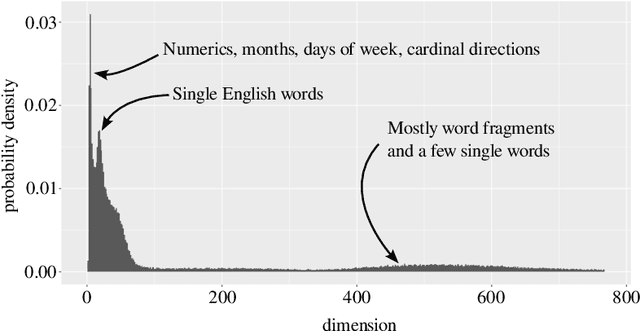
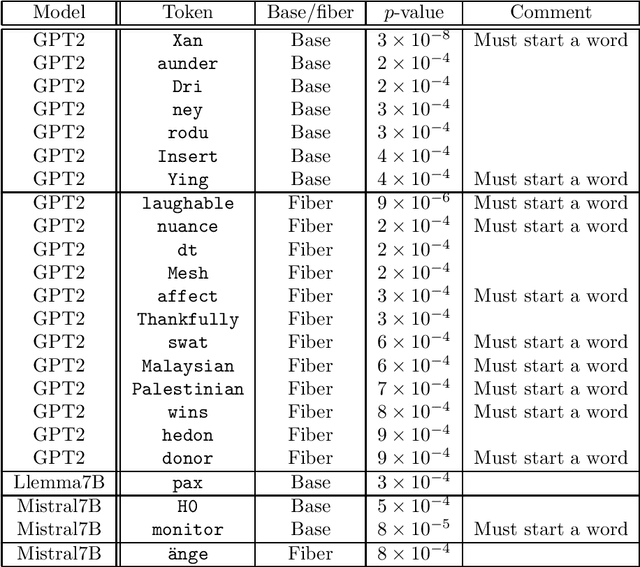
To fully understand the behavior of a large language model (LLM) requires our understanding of its input space. If this input space differs from our assumption, our understanding of and conclusions about the LLM is likely flawed, regardless of its architecture. Here, we elucidate the structure of the token embeddings, the input domain for LLMs, both empirically and theoretically. We present a generalized and statistically testable model where the neighborhood of each token splits into well-defined signal and noise dimensions. This model is based on a generalization of a manifold called a fiber bundle, so we denote our hypothesis test as the ``fiber bundle null.'' Failing to reject the null is uninformative, but rejecting it at a specific token indicates that token has a statistically significant local structure, and so is of interest to us. By running our test over several open-source LLMs, each with unique token embeddings, we find that the null is frequently rejected, and so the token subspace is provably not a fiber bundle and hence also not a manifold. As a consequence of our findings, when an LLM is presented with two semantically equivalent prompts, and if one prompt contains a token implicated by our test, that prompt will likely exhibit more output variability proportional to the local signal dimension of the token.
Probing the topology of the space of tokens with structured prompts
Mar 19, 2025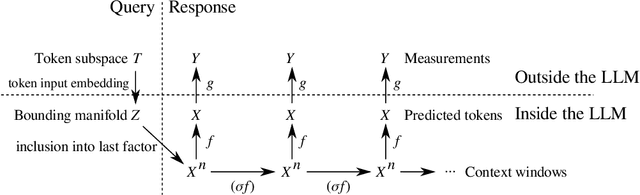

This article presents a general and flexible method for prompting a large language model (LLM) to reveal its (hidden) token input embedding up to homeomorphism. Moreover, this article provides strong theoretical justification -- a mathematical proof for generic LLMs -- for why this method should be expected to work. With this method in hand, we demonstrate its effectiveness by recovering the token subspace of Llemma-7B. The results of this paper apply not only to LLMs but also to general nonlinear autoregressive processes.
The structure of the token space for large language models
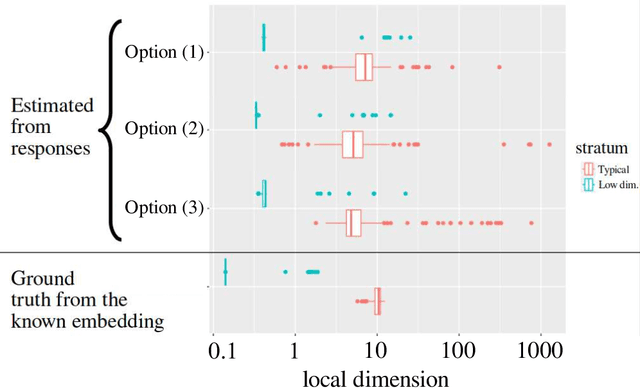
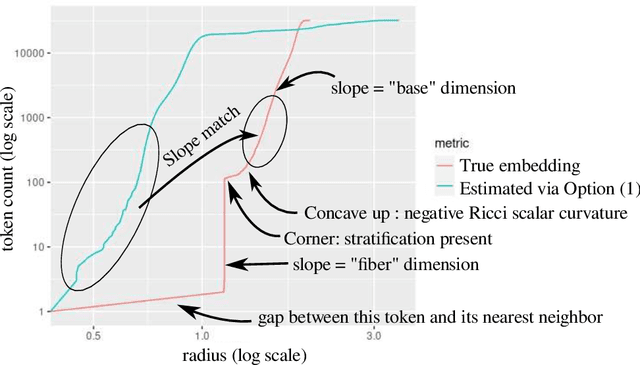
Oct 11, 2024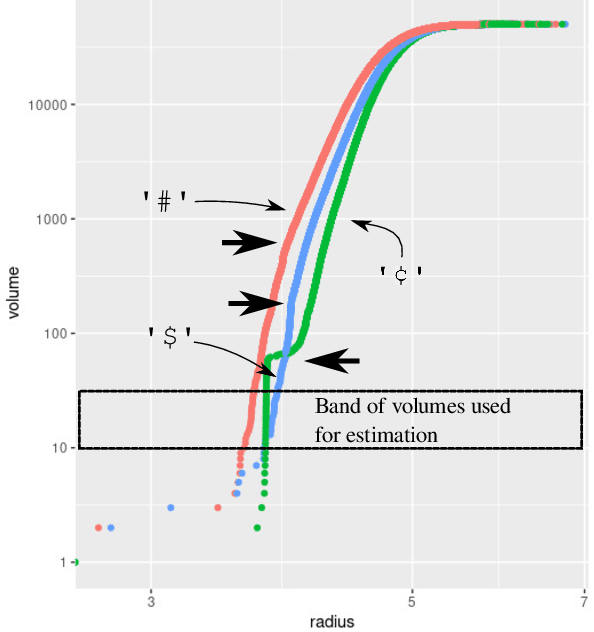
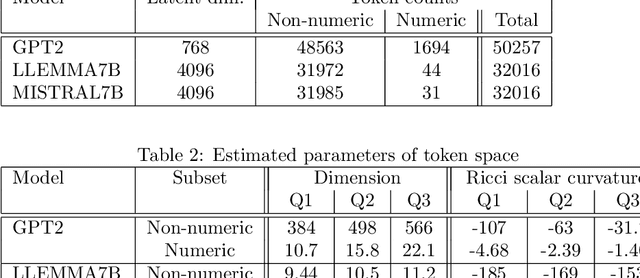
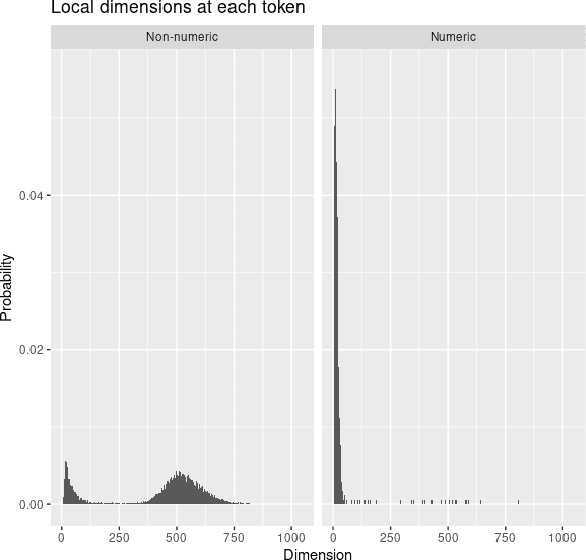
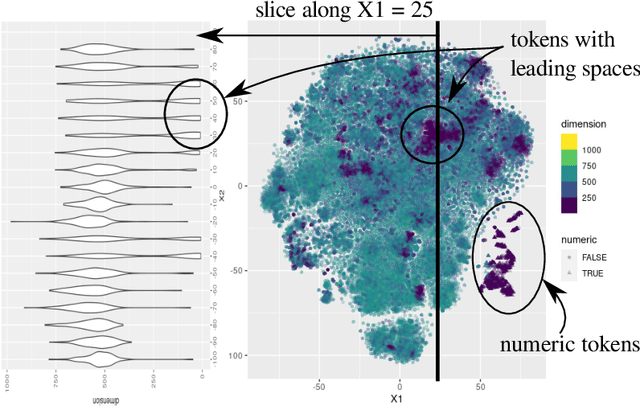
Large language models encode the correlational structure present in natural language by fitting segments of utterances (tokens) into a high dimensional ambient latent space upon which the models then operate. We assert that in order to develop a foundational, first-principles understanding of the behavior and limitations of large language models, it is crucial to understand the topological and geometric structure of this token subspace. In this article, we present estimators for the dimension and Ricci scalar curvature of the token subspace, and apply it to three open source large language models of moderate size: GPT2, LLEMMA7B, and MISTRAL7B. In all three models, using these measurements, we find that the token subspace is not a manifold, but is instead a stratified manifold, where on each of the individual strata, the Ricci curvature is significantly negative. We additionally find that the dimension and curvature correlate with generative fluency of the models, which suggest that these findings have implications for model behavior.
DLKoopman: A deep learning software package for Koopman theory
Nov 15, 2022


We present DLKoopman -- a software package for Koopman theory that uses deep learning to learn an encoding of a nonlinear dynamical system into a linear space, while simultaneously learning the linear dynamics. While several previous efforts have either restricted the ability to learn encodings, or been bespoke efforts designed for specific systems, DLKoopman is a generalized tool that can be applied to data-driven learning and optimization of any dynamical system. It can either be trained on data from individual states (snapshots) of a system and used to predict its unknown states, or trained on data from trajectories of a system and used to predict unknown trajectories for new initial states. DLKoopman is available on the Python Package Index (PyPI) as 'dlkoopman', and includes extensive documentation and tutorials. Additional contributions of the package include a novel metric called Average Normalized Absolute Error for evaluating performance, and a ready-to-use hyperparameter search module for improving performance.
LAGOON: An Analysis Tool for Open Source Communities
Jan 26, 2022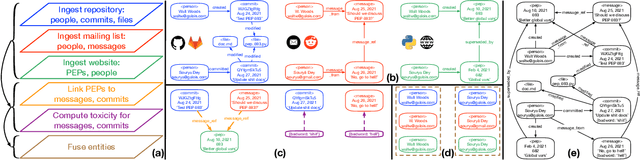
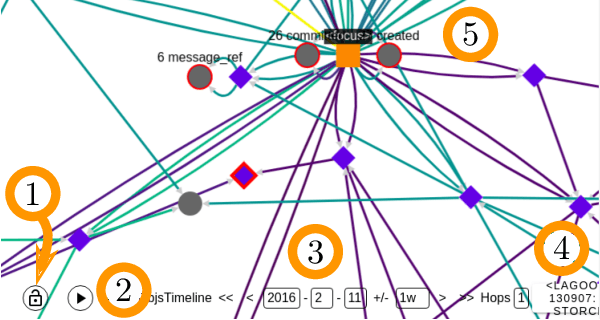

This paper presents LAGOON -- an open source platform for understanding the complex ecosystems of Open Source Software (OSS) communities. The platform currently utilizes spatiotemporal graphs to store and investigate the artifacts produced by these communities, and help analysts identify bad actors who might compromise an OSS project's security. LAGOON provides ingest of artifacts from several common sources, including source code repositories, issue trackers, mailing lists and scraping content from project websites. Ingestion utilizes a modular architecture, which supports incremental updates from data sources and provides a generic identity fusion process that can recognize the same community members across disparate accounts. A user interface is provided for visualization and exploration of an OSS project's complete sociotechnical graph. Scripts are provided for applying machine learning to identify patterns within the data. While current focus is on the identification of bad actors in the Python community, the platform's reusability makes it easily extensible with new data and analyses, paving the way for LAGOON to become a comprehensive means of assessing various OSS-based projects and their communities.
Deep-n-Cheap: An Automated Search Framework for Low Complexity Deep Learning
Apr 03, 2020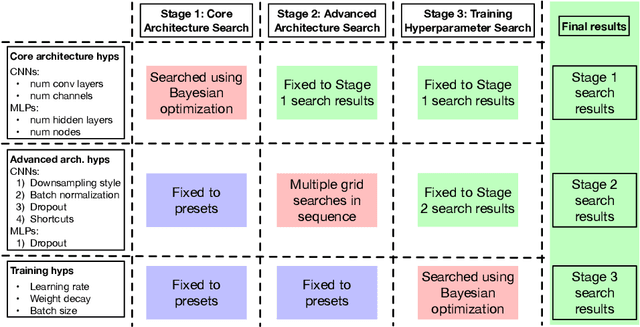

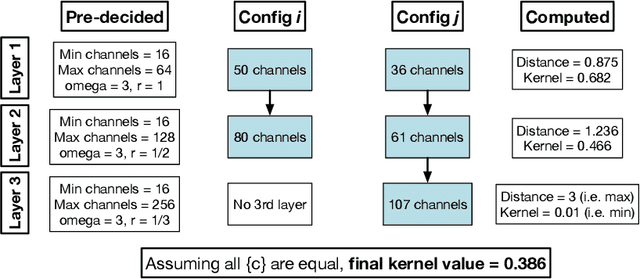
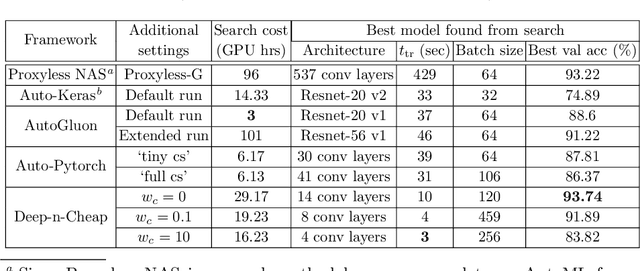
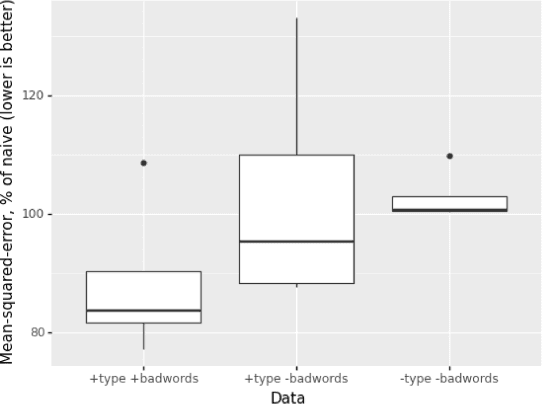
We present Deep-n-Cheap -- an open-source AutoML framework to search for deep learning models. This search includes both architecture and training hyperparameters, and supports convolutional neural networks and multi-layer perceptrons. Our framework is targeted for deployment on both benchmark and custom datasets, and as a result, offers a greater degree of search space customizability as compared to a more limited search over only pre-existing models from literature. We also introduce the technique of 'search transfer', which demonstrates the generalization capabilities of the models found by our framework to multiple datasets. Deep-n-Cheap includes a user-customizable complexity penalty which trades off performance with training time or number of parameters. Specifically, our framework results in models offering performance comparable to state-of-the-art while taking 1-2 orders of magnitude less time to train than models from other AutoML and model search frameworks. Additionally, this work investigates and develops various insights regarding the search process. In particular, we show the superiority of a greedy strategy and justify our choice of Bayesian optimization as the primary search methodology over random / grid search.
Pre-Defined Sparse Neural Networks with Hardware Acceleration
Dec 04, 2018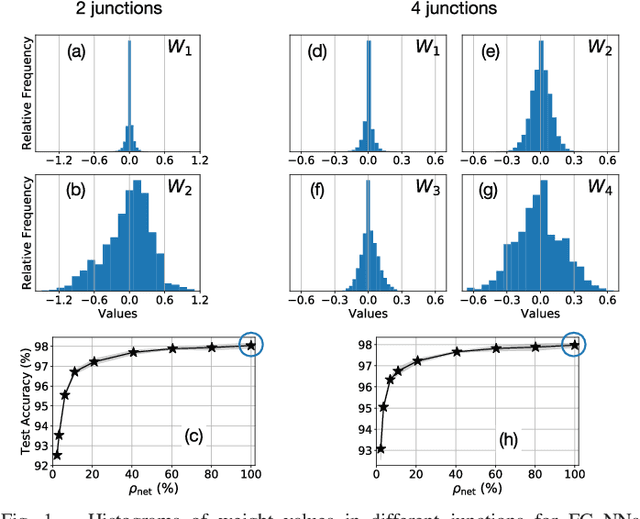
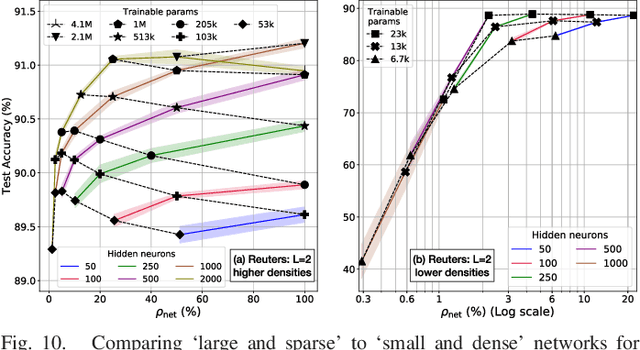
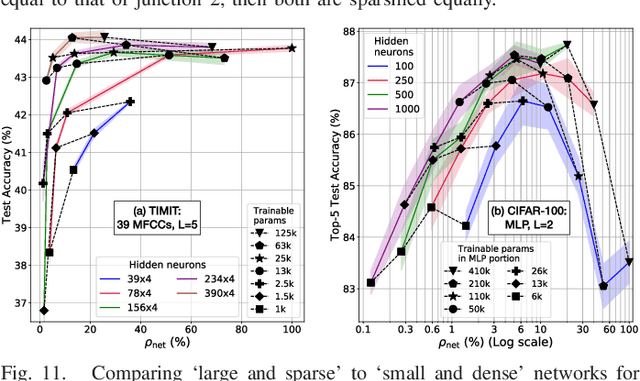
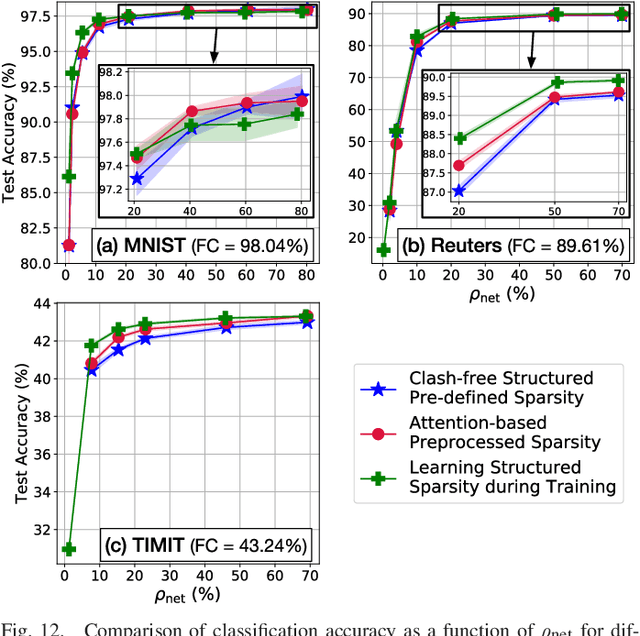
Neural networks have proven to be extremely powerful tools for modern artificial intelligence applications, but computational and storage complexity remain limiting factors. This paper presents two compatible contributions towards reducing the time, energy, computational, and storage complexities associated with multilayer perceptrons. Pre-defined sparsity is proposed to reduce the complexity during both training and inference, regardless of the implementation platform. Our results show that storage and computational complexity can be reduced by factors greater than 5X without significant performance loss. The second contribution is an architecture for hardware acceleration that is compatible with pre-defined sparsity. This architecture supports both training and inference modes and is flexible in the sense that it is not tied to a specific number of neurons. For example, this flexibility implies that various sized neural networks can be supported on various sized Field Programmable Gate Array (FPGA)s.
A Highly Parallel FPGA Implementation of Sparse Neural Network Training
Oct 11, 2018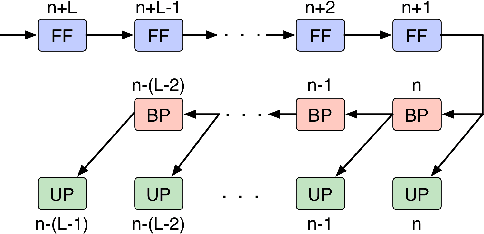
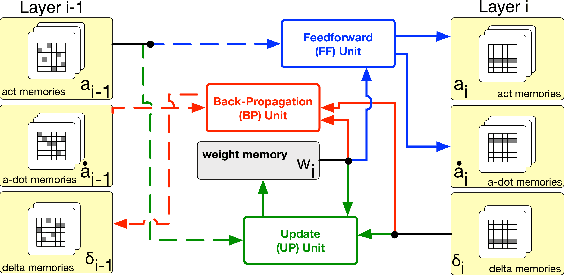
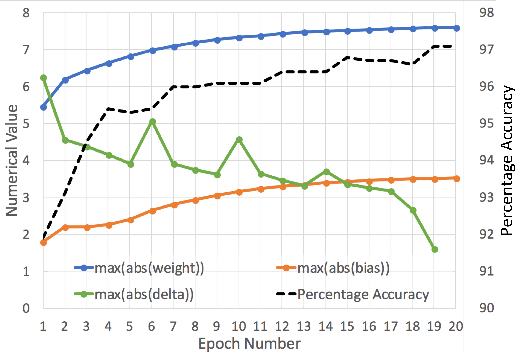
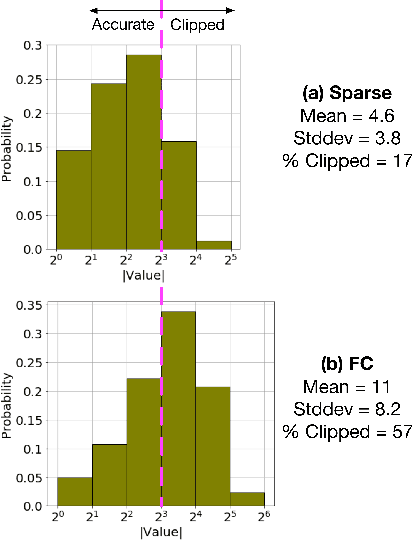
We demonstrate an FPGA implementation of a parallel and reconfigurable architecture for sparse neural networks, capable of on-chip training and inference. The network connectivity uses pre-determined, structured sparsity to significantly reduce complexity by lowering memory and computational requirements. The architecture uses a notion of edge-processing, leading to efficient pipelining and parallelization. Moreover, the device can be reconfigured to trade off resource utilization with training time to fit networks and datasets of varying sizes. The combined effects of complexity reduction and easy reconfigurability enable significantly greater exploration of network hyperparameters and structures on-chip. As proof of concept, we show implementation results on an Artix-7 FPGA.
Morse Code Datasets for Machine Learning
Jul 11, 2018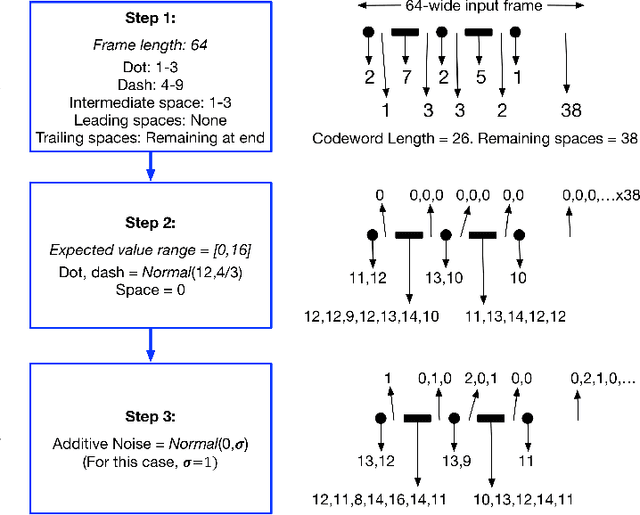
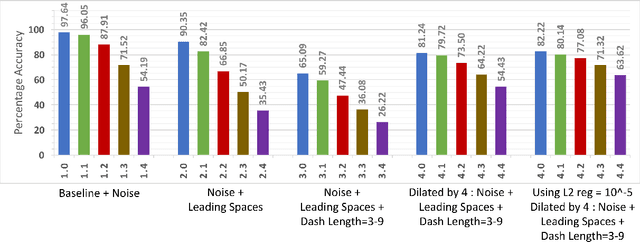
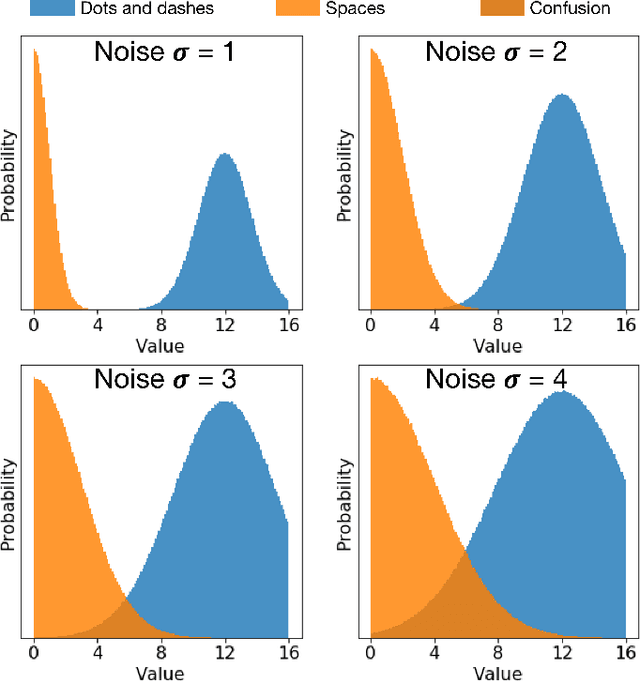
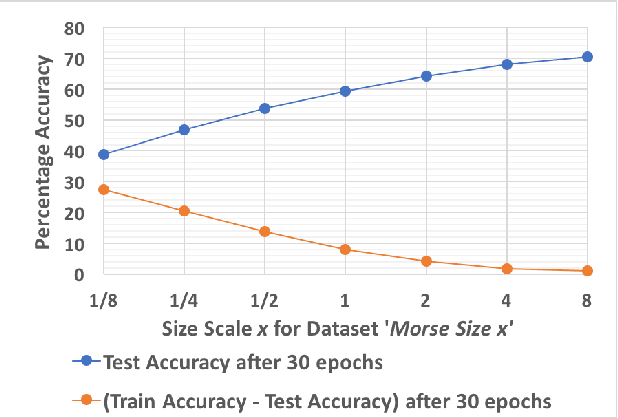
We present an algorithm to generate synthetic datasets of tunable difficulty on classification of Morse code symbols for supervised machine learning problems, in particular, neural networks. The datasets are spatially one-dimensional and have a small number of input features, leading to high density of input information content. This makes them particularly challenging when implementing network complexity reduction methods. We explore how network performance is affected by deliberately adding various forms of noise and expanding the feature set and dataset size. Finally, we establish several metrics to indicate the difficulty of a dataset, and evaluate their merits. The algorithm and datasets are open-source.
Interleaver Design for Deep Neural Networks
Apr 22, 2018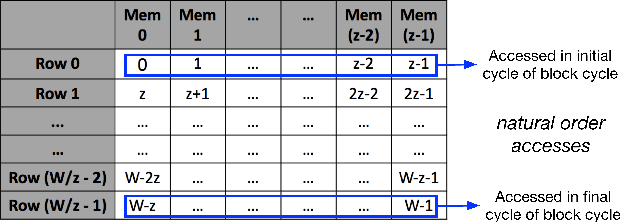
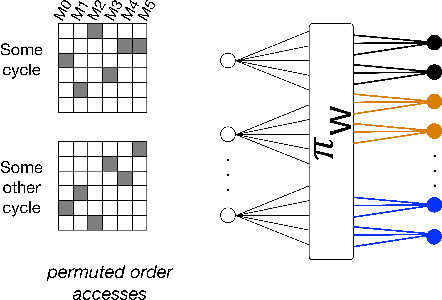
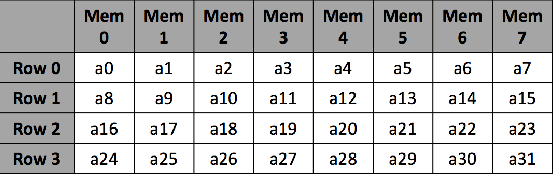
We propose a class of interleavers for a novel deep neural network (DNN) architecture that uses algorithmically pre-determined, structured sparsity to significantly lower memory and computational requirements, and speed up training. The interleavers guarantee clash-free memory accesses to eliminate idle operational cycles, optimize spread and dispersion to improve network performance, and are designed to ease the complexity of memory address computations in hardware. We present a design algorithm with mathematical proofs for these properties. We also explore interleaver variations and analyze the behavior of neural networks as a function of interleaver metrics.