Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaver Design for Deep Neural Networks
Paper and Code
Apr 22, 2018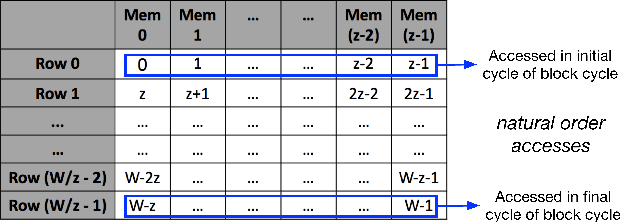
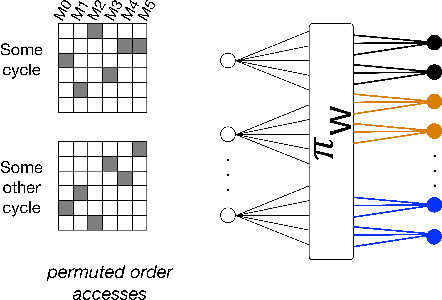
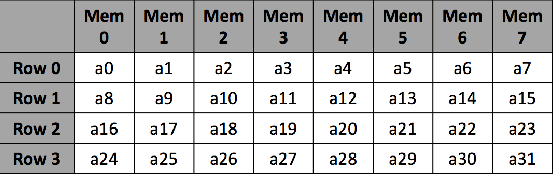
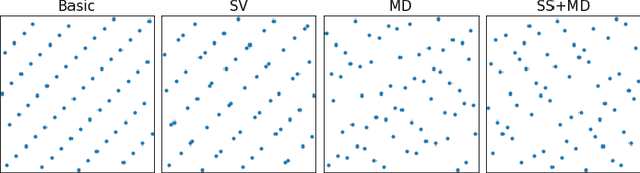
We propose a class of interleavers for a novel deep neural network (DNN) architecture that uses algorithmically pre-determined, structured sparsity to significantly lower memory and computational requirements, and speed up training. The interleavers guarantee clash-free memory accesses to eliminate idle operational cycles, optimize spread and dispersion to improve network performance, and are designed to ease the complexity of memory address computations in hardware. We present a design algorithm with mathematical proofs for these properties. We also explore interleaver variations and analyze the behavior of neural networks as a function of interleaver metrics.
* Presented at the 2017 51st Asilomar Conference on Signals, Systems,
and Computers, copyright IEEE
View paper on