 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemRoPE: Training-Free Infinite Video Generation via Evolving Memory Tokens
Mar 12, 2026Autoregressive diffusion enables real-time frame streaming, yet existing sliding-window caches discard past context, causing fidelity degradation, identity drift, and motion stagnation over long horizons. Current approaches preserve a fixed set of early tokens as attention sinks, but this static anchor cannot reflect the evolving content of a growing video. We introduce MemRoPE, a training-free framework with two co-designed components. Memory Tokens continuously compress all past keys into dual long-term and short-term streams via exponential moving averages, maintaining both global identity and recent dynamics within a fixed-size cache. Online RoPE Indexing caches unrotated keys and applies positional embeddings dynamically at attention time, ensuring the aggregation is free of conflicting positional phases. These two mechanisms are mutually enabling: positional decoupling makes temporal aggregation well-defined, while aggregation makes fixed-size caching viable for unbounded generation. Extensive experiments validate that MemRoPE outperforms existing methods in temporal coherence, visual fidelity, and subject consistency across minute- to hour-scale generation.
RedVTP: Training-Free Acceleration of Diffusion Vision-Language Models Inference via Masked Token-Guided Visual Token Pruning
Nov 16, 2025



Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning and generation, yet their high computational demands remain a major challenge. Diffusion Vision-Language Models (DVLMs) are particularly attractive because they enable parallel token decoding, but the large number of visual tokens still significantly hinders their inference efficiency. While visual token pruning has been extensively studied for autoregressive VLMs (AVLMs), it remains largely unexplored for DVLMs. In this work, we propose RedVTP, a response-driven visual token pruning strategy that leverages the inference dynamics of DVLMs. Our method estimates visual token importance using attention from the masked response tokens. Based on the observation that these importance scores remain consistent across steps, RedVTP prunes the less important visual tokens from the masked tokens after the first inference step, thereby maximizing inference efficiency. Experiments show that RedVTP improves token generation throughput of LLaDA-V and LaViDa by up to 186% and 28.05%, respectively, and reduces inference latency by up to 64.97% and 21.87%, without compromising-and in some cases improving-accuracy.
FPAN: Mitigating Replication in Diffusion Models through the Fine-Grained Probabilistic Addition of Noise to Token Embeddings
May 28, 2025Diffusion models have demonstrated remarkable potential in generating high-quality images. However, their tendency to replicate training data raises serious privacy concerns, particularly when the training datasets contain sensitive or private information. Existing mitigation strategies primarily focus on reducing image duplication, modifying the cross-attention mechanism, and altering the denoising backbone architecture of diffusion models. Moreover, recent work has shown that adding a consistent small amount of noise to text embeddings can reduce replication to some degree. In this work, we begin by analyzing the impact of adding varying amounts of noise. Based on our analysis, we propose a fine-grained noise injection technique that probabilistically adds a larger amount of noise to token embeddings. We refer to our method as Fine-grained Probabilistic Addition of Noise (FPAN). Through our extensive experiments, we show that our proposed FPAN can reduce replication by an average of 28.78% compared to the baseline diffusion model without significantly impacting image quality, and outperforms the prior consistent-magnitude-noise-addition approach by 26.51%. Moreover, when combined with other existing mitigation methods, our FPAN approach can further reduce replication by up to 16.82% with similar, if not improved, image quality.
Mitigating Hallucinations in Vision-Language Models through Image-Guided Head Suppression
May 22, 2025
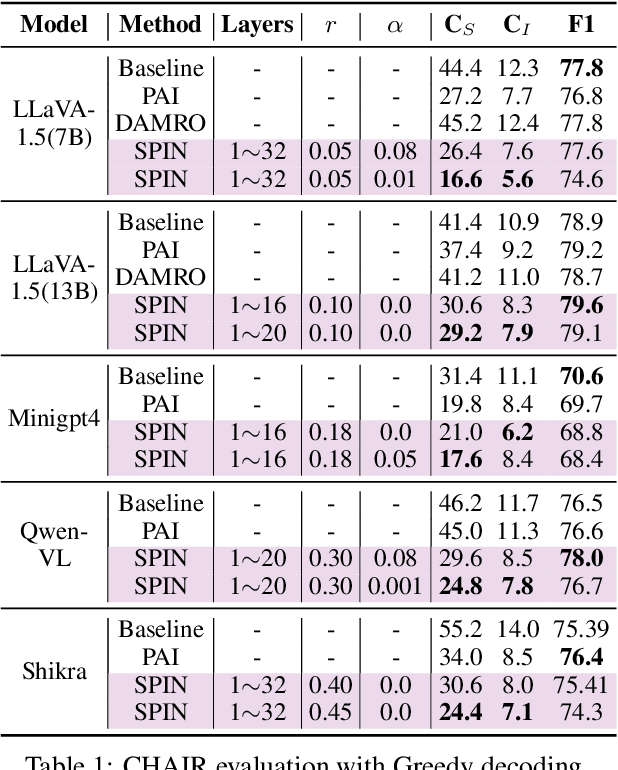
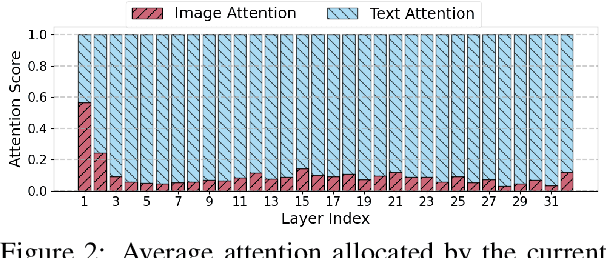
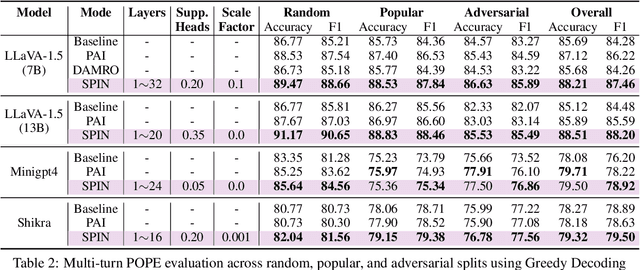
Despite their remarkable progress in multimodal understanding tasks, large vision language models (LVLMs) often suffer from "hallucinations", generating texts misaligned with the visual context. Existing methods aimed at reducing hallucinations through inference time intervention incur a significant increase in latency. To mitigate this, we present SPIN, a task-agnostic attention-guided head suppression strategy that can be seamlessly integrated during inference, without incurring any significant compute or latency overhead. We investigate whether hallucination in LVLMs can be linked to specific model components. Our analysis suggests that hallucinations can be attributed to a dynamic subset of attention heads in each layer. Leveraging this insight, for each text query token, we selectively suppress attention heads that exhibit low attention to image tokens, keeping the top-K attention heads intact. Extensive evaluations on visual question answering and image description tasks demonstrate the efficacy of SPIN in reducing hallucination scores up to 2.7x while maintaining F1, and improving throughput by 1.8x compared to existing alternatives. Code is available at https://github.com/YUECHE77/SPIN.
Region Masking to Accelerate Video Processing on Neuromorphic Hardware
Mar 21, 2025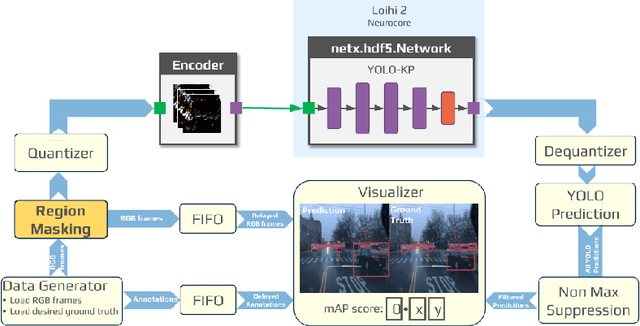
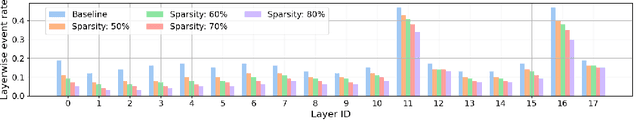
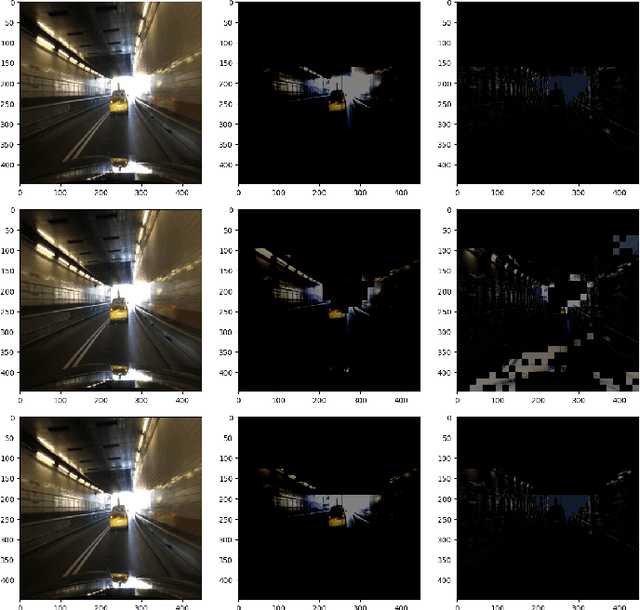
The rapidly growing demand for on-chip edge intelligence on resource-constrained devices has motivated approaches to reduce energy and latency of deep learning models. Spiking neural networks (SNNs) have gained particular interest due to their promise to reduce energy consumption using event-based processing. We assert that while sigma-delta encoding in SNNs can take advantage of the temporal redundancy across video frames, they still involve a significant amount of redundant computations due to processing insignificant events. In this paper, we propose a region masking strategy that identifies regions of interest at the input of the SNN, thereby eliminating computation and data movement for events arising from unimportant regions. Our approach demonstrates that masking regions at the input not only significantly reduces the overall spiking activity of the network, but also provides significant improvement in throughput and latency. We apply region masking during video object detection on Loihi 2, demonstrating that masking approximately 60% of input regions can reduce energy-delay product by 1.65x over a baseline sigma-delta network, with a degradation in mAP@0.5 by 1.09%.
LoyalDiffusion: A Diffusion Model Guarding Against Data Replication
Dec 02, 2024



Diffusion models have demonstrated significant potential in image generation. However, their ability to replicate training data presents a privacy risk, particularly when the training data includes confidential information. Existing mitigation strategies primarily focus on augmenting the training dataset, leaving the impact of diffusion model architecture under explored. In this paper, we address this gap by examining and mitigating the impact of the model structure, specifically the skip connections in the diffusion model's U-Net model. We first present our observation on a trade-off in the skip connections. While they enhance image generation quality, they also reinforce the memorization of training data, increasing the risk of replication. To address this, we propose a replication-aware U-Net (RAU-Net) architecture that incorporates information transfer blocks into skip connections that are less essential for image quality. Recognizing the potential impact of RAU-Net on generation quality, we further investigate and identify specific timesteps during which the impact on memorization is most pronounced. By applying RAU-Net selectively at these critical timesteps, we couple our novel diffusion model with a targeted training and inference strategy, forming a framework we refer to as LoyalDiffusion. Extensive experiments demonstrate that LoyalDiffusion outperforms the state-of-the-art replication mitigation method achieving a 48.63% reduction in replication while maintaining comparable image quality.
TinyML Security: Exploring Vulnerabilities in Resource-Constrained Machine Learning Systems
Nov 11, 2024



Tiny Machine Learning (TinyML) systems, which enable machine learning inference on highly resource-constrained devices, are transforming edge computing but encounter unique security challenges. These devices, restricted by RAM and CPU capabilities two to three orders of magnitude smaller than conventional systems, make traditional software and hardware security solutions impractical. The physical accessibility of these devices exacerbates their susceptibility to side-channel attacks and information leakage. Additionally, TinyML models pose security risks, with weights potentially encoding sensitive data and query interfaces that can be exploited. This paper offers the first thorough survey of TinyML security threats. We present a device taxonomy that differentiates between IoT, EdgeML, and TinyML, highlighting vulnerabilities unique to TinyML. We list various attack vectors, assess their threat levels using the Common Vulnerability Scoring System, and evaluate both existing and possible defenses. Our analysis identifies where traditional security measures are adequate and where solutions tailored to TinyML are essential. Our results underscore the pressing need for specialized security solutions in TinyML to ensure robust and secure edge computing applications. We aim to inform the research community and inspire innovative approaches to protecting this rapidly evolving and critical field.
Voltage-Controlled Magnetic Tunnel Junction based ADC-less Global Shutter Processing-in-Pixel for Extreme-Edge Intelligence
Oct 14, 2024



The vast amount of data generated by camera sensors has prompted the exploration of energy-efficient processing solutions for deploying computer vision tasks on edge devices. Among the various approaches studied, processing-in-pixel integrates massively parallel analog computational capabilities at the extreme-edge, i.e., within the pixel array and exhibits enhanced energy and bandwidth efficiency by generating the output activations of the first neural network layer rather than the raw sensory data. In this article, we propose an energy and bandwidth efficient ADC-less processing-in-pixel architecture. This architecture implements an optimized binary activation neural network trained using Hoyer regularizer for high accuracy on complex vision tasks. In addition, we also introduce a global shutter burst memory read scheme utilizing fast and disturb-free read operation leveraging innovative use of nanoscale voltage-controlled magnetic tunnel junctions (VC-MTJs). Moreover, we develop an algorithmic framework incorporating device and circuit constraints (characteristic device switching behavior and circuit non-linearity) based on state-of-the-art fabricated VC-MTJ characteristics and extensive circuit simulations using commercial GlobalFoundries 22nm FDX technology. Finally, we evaluate the proposed system's performance on two complex datasets - CIFAR10 and ImageNet, showing improvements in front-end and communication energy efficiency by 8.2x and 8.5x respectively and reduction in bandwidth by 6x compared to traditional computer vision systems, without any significant drop in the test accuracy.
Energy-Efficient & Real-Time Computer Vision with Intelligent Skipping via Reconfigurable CMOS Image Sensors
Sep 25, 2024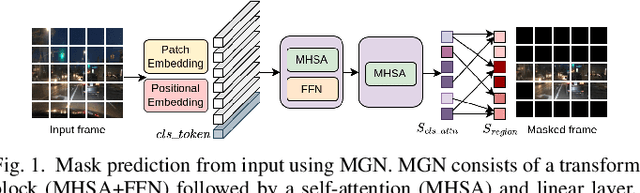
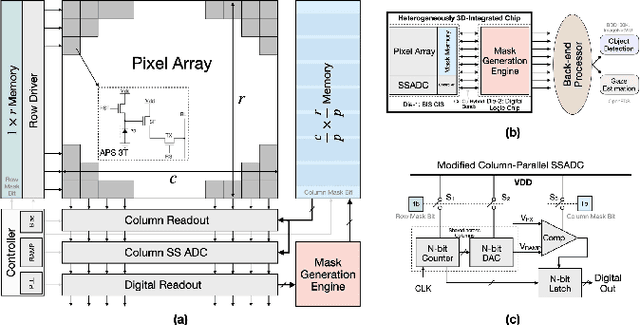
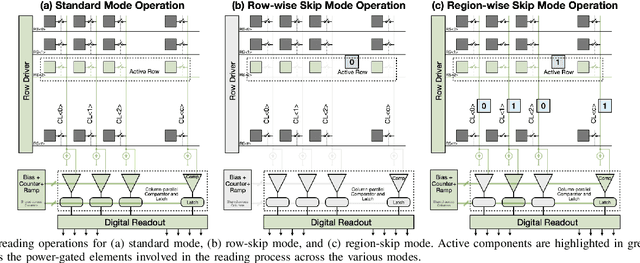
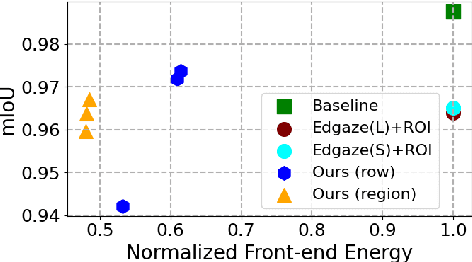
Current video-based computer vision (CV) applications typically suffer from high energy consumption due to reading and processing all pixels in a frame, regardless of their significance. While previous works have attempted to reduce this energy by skipping input patches or pixels and using feedback from the end task to guide the skipping algorithm, the skipping is not performed during the sensor read phase. As a result, these methods can not optimize the front-end sensor energy. Moreover, they may not be suitable for real-time applications due to the long latency of modern CV networks that are deployed in the back-end. To address this challenge, this paper presents a custom-designed reconfigurable CMOS image sensor (CIS) system that improves energy efficiency by selectively skipping uneventful regions or rows within a frame during the sensor's readout phase, and the subsequent analog-to-digital conversion (ADC) phase. A novel masking algorithm intelligently directs the skipping process in real-time, optimizing both the front-end sensor and back-end neural networks for applications including autonomous driving and augmented/virtual reality (AR/VR). Our system can also operate in standard mode without skipping, depending on application needs. We evaluate our hardware-algorithm co-design framework on object detection based on BDD100K and ImageNetVID, and gaze estimation based on OpenEDS, achieving up to 53% reduction in front-end sensor energy while maintaining state-of-the-art (SOTA) accuracy.
MaskVD: Region Masking for Efficient Video Object Detection
Jul 16, 2024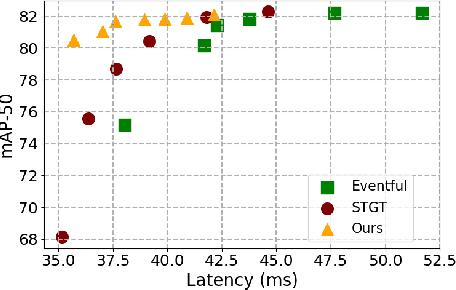
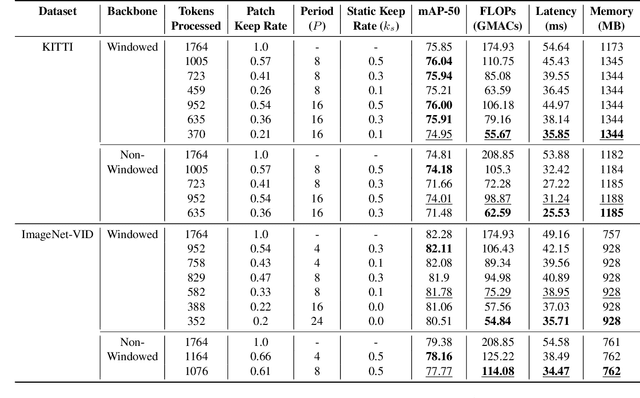
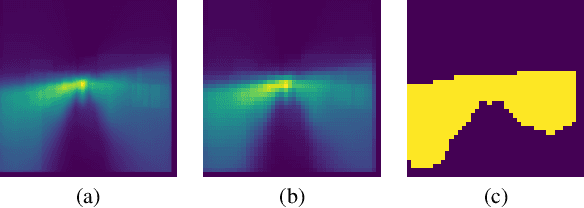
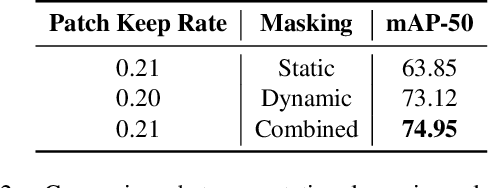
Video tasks are compute-heavy and thus pose a challenge when deploying in real-time applications, particularly for tasks that require state-of-the-art Vision Transformers (ViTs). Several research efforts have tried to address this challenge by leveraging the fact that large portions of the video undergo very little change across frames, leading to redundant computations in frame-based video processing. In particular, some works leverage pixel or semantic differences across frames, however, this yields limited latency benefits with significantly increased memory overhead. This paper, in contrast, presents a strategy for masking regions in video frames that leverages the semantic information in images and the temporal correlation between frames to significantly reduce FLOPs and latency with little to no penalty in performance over baseline models. In particular, we demonstrate that by leveraging extracted features from previous frames, ViT backbones directly benefit from region masking, skipping up to 80% of input regions, improving FLOPs and latency by 3.14x and 1.5x. We improve memory and latency over the state-of-the-art (SOTA) by 2.3x and 1.14x, while maintaining similar detection performance. Additionally, our approach demonstrates promising results on convolutional neural networks (CNNs) and provides latency improvements over the SOTA up to 1.3x using specialized computational kernels.