 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoyalDiffusion: A Diffusion Model Guarding Against Data Replication
Dec 02, 2024



Diffusion models have demonstrated significant potential in image generation. However, their ability to replicate training data presents a privacy risk, particularly when the training data includes confidential information. Existing mitigation strategies primarily focus on augmenting the training dataset, leaving the impact of diffusion model architecture under explored. In this paper, we address this gap by examining and mitigating the impact of the model structure, specifically the skip connections in the diffusion model's U-Net model. We first present our observation on a trade-off in the skip connections. While they enhance image generation quality, they also reinforce the memorization of training data, increasing the risk of replication. To address this, we propose a replication-aware U-Net (RAU-Net) architecture that incorporates information transfer blocks into skip connections that are less essential for image quality. Recognizing the potential impact of RAU-Net on generation quality, we further investigate and identify specific timesteps during which the impact on memorization is most pronounced. By applying RAU-Net selectively at these critical timesteps, we couple our novel diffusion model with a targeted training and inference strategy, forming a framework we refer to as LoyalDiffusion. Extensive experiments demonstrate that LoyalDiffusion outperforms the state-of-the-art replication mitigation method achieving a 48.63% reduction in replication while maintaining comparable image quality.
Quantitative causality, causality-guided scientific discovery, and causal machine learning
Feb 20, 2024It has been said, arguably, that causality analysis should pave a promising way to interpretable deep learning and generalization. Incorporation of causality into artificial intelligence (AI) algorithms, however, is challenged with its vagueness, non-quantitiveness, computational inefficiency, etc. During the past 18 years, these challenges have been essentially resolved, with the establishment of a rigorous formalism of causality analysis initially motivated from atmospheric predictability. This not only opens a new field in the atmosphere-ocean science, namely, information flow, but also has led to scientific discoveries in other disciplines, such as quantum mechanics, neuroscience, financial economics, etc., through various applications. This note provides a brief review of the decade-long effort, including a list of major theoretical results, a sketch of the causal deep learning framework, and some representative real-world applications in geoscience pertaining to this journal, such as those on the anthropogenic cause of global warming, the decadal prediction of El Ni\~no Modoki, the forecasting of an extreme drought in China, among others.
GameGPT: Multi-agent Collaborative Framework for Game Development
Oct 12, 2023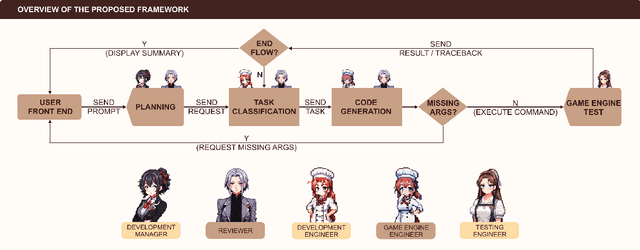
The large language model (LLM) based agents have demonstrated their capacity to automate and expedite software development processes. In this paper, we focus on game development and propose a multi-agent collaborative framework, dubbed GameGPT, to automate game development. While many studies have pinpointed hallucination as a primary roadblock for deploying LLMs in production, we identify another concern: redundancy. Our framework presents a series of methods to mitigate both concerns. These methods include dual collaboration and layered approaches with several in-house lexicons, to mitigate the hallucination and redundancy in the planning, task identification, and implementation phases. Furthermore, a decoupling approach is also introduced to achieve code generation with better precision.
Mitigate Replication and Copying in Diffusion Models with Generalized Caption and Dual Fusion Enhancement
Sep 13, 2023



While diffusion models demonstrate a remarkable capability for generating high-quality images, their tendency to `replicate' training data raises privacy concerns. Although recent research suggests that this replication may stem from the insufficient generalization of training data captions and duplication of training images, effective mitigation strategies remain elusive. To address this gap, our paper first introduces a generality score that measures the caption generality and employ large language model (LLM) to generalize training captions. Subsequently, we leverage generalized captions and propose a novel dual fusion enhancement approach to mitigate the replication of diffusion models. Our empirical results demonstrate that our proposed methods can significantly reduce replication by 43.5% compared to the original diffusion model while maintaining the diversity and quality of generations.
Island-based Random Dynamic Voltage Scaling vs ML-Enhanced Power Side-Channel Attacks
Jun 13, 2023In this paper, we describe and analyze an island-based random dynamic voltage scaling (iRDVS) approach to thwart power side-channel attacks. We first analyze the impact of the number of independent voltage islands on the resulting signal-to-noise ratio and trace misalignment. As part of our analysis of misalignment, we propose a novel unsupervised machine learning (ML) based attack that is effective on systems with three or fewer independent voltages. Our results show that iRDVS with four voltage islands, however, cannot be broken with 200k encryption traces, suggesting that iRDVS can be effective. We finish the talk by describing an iRDVS test chip in a 12nm FinFet process that incorporates three variants of an AES-256 accelerator, all originating from the same RTL. This included a synchronous core, an asynchronous core with no protection, and a core employing the iRDVS technique using asynchronous logic. Lab measurements from the chips indicated that both unprotected variants failed the test vector leakage assessment (TVLA) security metric test, while the iRDVS was proven secure in a variety of configurations.
Making Models Shallow Again: Jointly Learning to Reduce Non-Linearity and Depth for Latency-Efficient Private Inference
Apr 26, 2023



Large number of ReLU and MAC operations of Deep neural networks make them ill-suited for latency and compute-efficient private inference. In this paper, we present a model optimization method that allows a model to learn to be shallow. In particular, we leverage the ReLU sensitivity of a convolutional block to remove a ReLU layer and merge its succeeding and preceding convolution layers to a shallow block. Unlike existing ReLU reduction methods, our joint reduction method can yield models with improved reduction of both ReLUs and linear operations by up to 1.73x and 1.47x, respectively, evaluated with ResNet18 on CIFAR-100 without any significant accuracy-drop.