 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPAN: Mitigating Replication in Diffusion Models through the Fine-Grained Probabilistic Addition of Noise to Token Embeddings
May 28, 2025Diffusion models have demonstrated remarkable potential in generating high-quality images. However, their tendency to replicate training data raises serious privacy concerns, particularly when the training datasets contain sensitive or private information. Existing mitigation strategies primarily focus on reducing image duplication, modifying the cross-attention mechanism, and altering the denoising backbone architecture of diffusion models. Moreover, recent work has shown that adding a consistent small amount of noise to text embeddings can reduce replication to some degree. In this work, we begin by analyzing the impact of adding varying amounts of noise. Based on our analysis, we propose a fine-grained noise injection technique that probabilistically adds a larger amount of noise to token embeddings. We refer to our method as Fine-grained Probabilistic Addition of Noise (FPAN). Through our extensive experiments, we show that our proposed FPAN can reduce replication by an average of 28.78% compared to the baseline diffusion model without significantly impacting image quality, and outperforms the prior consistent-magnitude-noise-addition approach by 26.51%. Moreover, when combined with other existing mitigation methods, our FPAN approach can further reduce replication by up to 16.82% with similar, if not improved, image quality.
Interpretable Machine Learning for Macro Alpha: A News Sentiment Case Study
May 22, 2025This study introduces an interpretable machine learning (ML) framework to extract macroeconomic alpha from global news sentiment. We process the Global Database of Events, Language, and Tone (GDELT) Project's worldwide news feed using FinBERT -- a Bidirectional Encoder Representations from Transformers (BERT) based model pretrained on finance-specific language -- to construct daily sentiment indices incorporating mean tone, dispersion, and event impact. These indices drive an XGBoost classifier, benchmarked against logistic regression, to predict next-day returns for EUR/USD, USD/JPY, and 10-year U.S. Treasury futures (ZN). Rigorous out-of-sample (OOS) backtesting (5-fold expanding-window cross-validation, OOS period: c. 2017-April 2025) demonstrates exceptional, cost-adjusted performance for the XGBoost strategy: Sharpe ratios achieve 5.87 (EUR/USD), 4.65 (USD/JPY), and 4.65 (Treasuries), with respective compound annual growth rates (CAGRs) exceeding 50% in Foreign Exchange (FX) and 22% in bonds. Shapley Additive Explanations (SHAP) affirm that sentiment dispersion and article impact are key predictive features. Our findings establish that integrating domain-specific Natural Language Processing (NLP) with interpretable ML offers a potent and explainable source of macro alpha.
LoyalDiffusion: A Diffusion Model Guarding Against Data Replication
Dec 02, 2024



Diffusion models have demonstrated significant potential in image generation. However, their ability to replicate training data presents a privacy risk, particularly when the training data includes confidential information. Existing mitigation strategies primarily focus on augmenting the training dataset, leaving the impact of diffusion model architecture under explored. In this paper, we address this gap by examining and mitigating the impact of the model structure, specifically the skip connections in the diffusion model's U-Net model. We first present our observation on a trade-off in the skip connections. While they enhance image generation quality, they also reinforce the memorization of training data, increasing the risk of replication. To address this, we propose a replication-aware U-Net (RAU-Net) architecture that incorporates information transfer blocks into skip connections that are less essential for image quality. Recognizing the potential impact of RAU-Net on generation quality, we further investigate and identify specific timesteps during which the impact on memorization is most pronounced. By applying RAU-Net selectively at these critical timesteps, we couple our novel diffusion model with a targeted training and inference strategy, forming a framework we refer to as LoyalDiffusion. Extensive experiments demonstrate that LoyalDiffusion outperforms the state-of-the-art replication mitigation method achieving a 48.63% reduction in replication while maintaining comparable image quality.
TinyML Security: Exploring Vulnerabilities in Resource-Constrained Machine Learning Systems
Nov 11, 2024



Tiny Machine Learning (TinyML) systems, which enable machine learning inference on highly resource-constrained devices, are transforming edge computing but encounter unique security challenges. These devices, restricted by RAM and CPU capabilities two to three orders of magnitude smaller than conventional systems, make traditional software and hardware security solutions impractical. The physical accessibility of these devices exacerbates their susceptibility to side-channel attacks and information leakage. Additionally, TinyML models pose security risks, with weights potentially encoding sensitive data and query interfaces that can be exploited. This paper offers the first thorough survey of TinyML security threats. We present a device taxonomy that differentiates between IoT, EdgeML, and TinyML, highlighting vulnerabilities unique to TinyML. We list various attack vectors, assess their threat levels using the Common Vulnerability Scoring System, and evaluate both existing and possible defenses. Our analysis identifies where traditional security measures are adequate and where solutions tailored to TinyML are essential. Our results underscore the pressing need for specialized security solutions in TinyML to ensure robust and secure edge computing applications. We aim to inform the research community and inspire innovative approaches to protecting this rapidly evolving and critical field.
Mitigate Replication and Copying in Diffusion Models with Generalized Caption and Dual Fusion Enhancement
Sep 13, 2023



While diffusion models demonstrate a remarkable capability for generating high-quality images, their tendency to `replicate' training data raises privacy concerns. Although recent research suggests that this replication may stem from the insufficient generalization of training data captions and duplication of training images, effective mitigation strategies remain elusive. To address this gap, our paper first introduces a generality score that measures the caption generality and employ large language model (LLM) to generalize training captions. Subsequently, we leverage generalized captions and propose a novel dual fusion enhancement approach to mitigate the replication of diffusion models. Our empirical results demonstrate that our proposed methods can significantly reduce replication by 43.5% compared to the original diffusion model while maintaining the diversity and quality of generations.
Making Models Shallow Again: Jointly Learning to Reduce Non-Linearity and Depth for Latency-Efficient Private Inference
Apr 26, 2023



Large number of ReLU and MAC operations of Deep neural networks make them ill-suited for latency and compute-efficient private inference. In this paper, we present a model optimization method that allows a model to learn to be shallow. In particular, we leverage the ReLU sensitivity of a convolutional block to remove a ReLU layer and merge its succeeding and preceding convolution layers to a shallow block. Unlike existing ReLU reduction methods, our joint reduction method can yield models with improved reduction of both ReLUs and linear operations by up to 1.73x and 1.47x, respectively, evaluated with ResNet18 on CIFAR-100 without any significant accuracy-drop.
Learning to Linearize Deep Neural Networks for Secure and Efficient Private Inference
Jan 23, 2023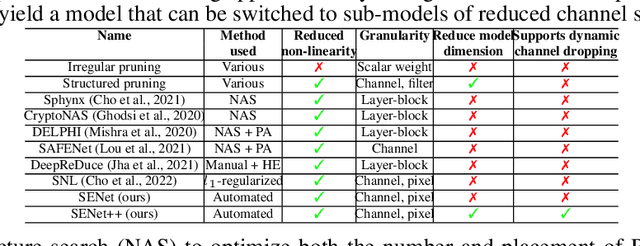
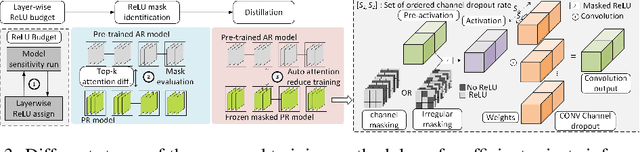
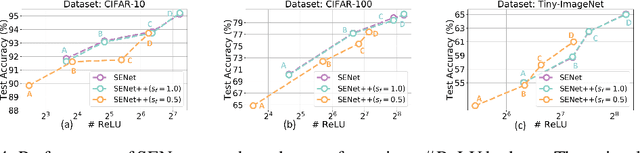
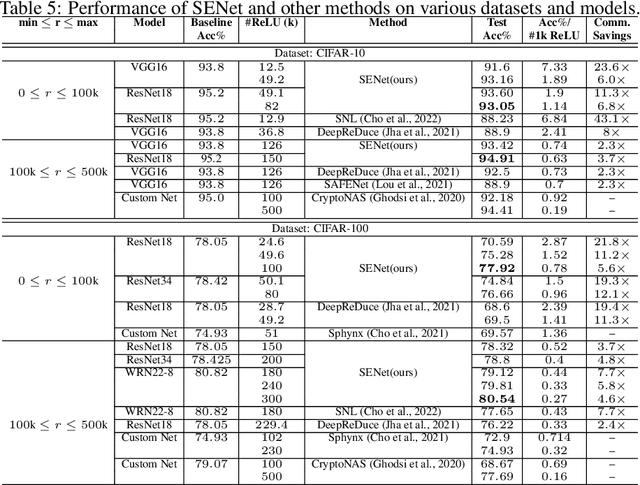
The large number of ReLU non-linearity operations in existing deep neural networks makes them ill-suited for latency-efficient private inference (PI). Existing techniques to reduce ReLU operations often involve manual effort and sacrifice significant accuracy. In this paper, we first present a novel measure of non-linearity layers' ReLU sensitivity, enabling mitigation of the time-consuming manual efforts in identifying the same. Based on this sensitivity, we then present SENet, a three-stage training method that for a given ReLU budget, automatically assigns per-layer ReLU counts, decides the ReLU locations for each layer's activation map, and trains a model with significantly fewer ReLUs to potentially yield latency and communication efficient PI. Experimental evaluations with multiple models on various datasets show SENet's superior performance both in terms of reduced ReLUs and improved classification accuracy compared to existing alternatives. In particular, SENet can yield models that require up to ~2x fewer ReLUs while yielding similar accuracy. For a similar ReLU budget SENet can yield models with ~2.32% improved classification accuracy, evaluated on CIFAR-100.
Deep Compression of Sum-Product Networks on Tensor Networks
Nov 09, 2018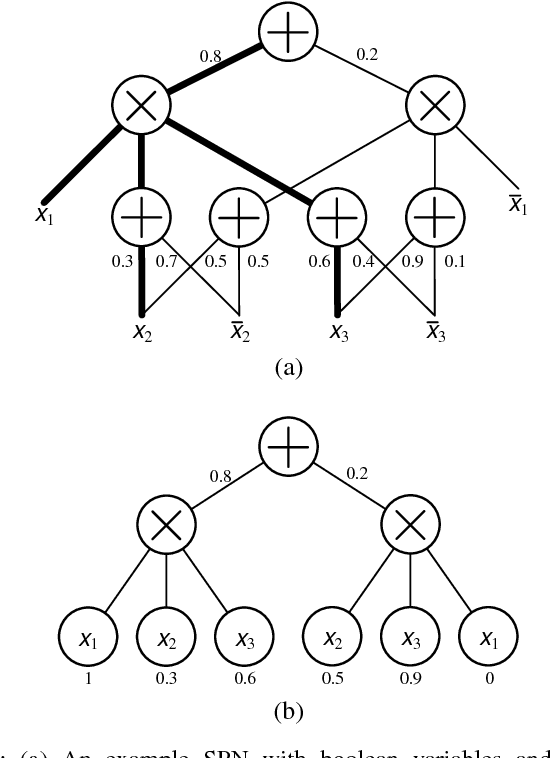
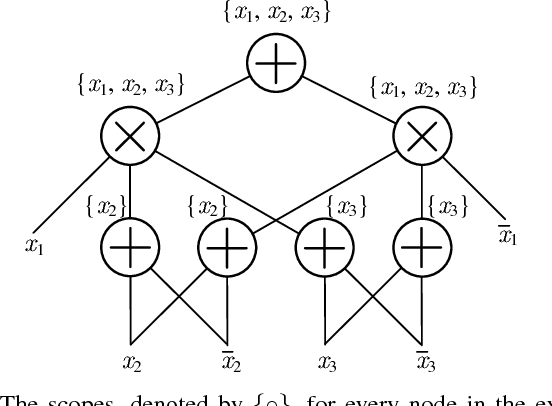
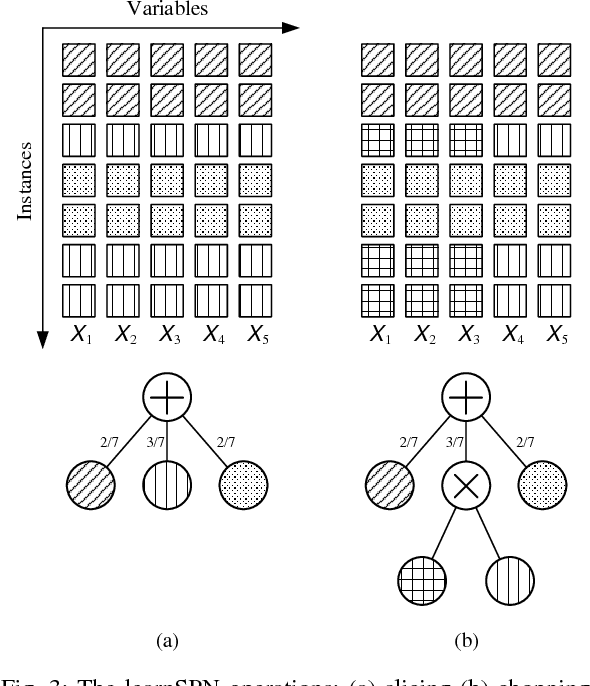

Sum-product networks (SPNs) represent an emerging class of neural networks with clear probabilistic semantics and superior inference speed over graphical models. This work reveals a strikingly intimate connection between SPNs and tensor networks, thus leading to a highly efficient representation that we call tensor SPNs (tSPNs). For the first time, through mapping an SPN onto a tSPN and employing novel optimization techniques, we demonstrate remarkable parameter compression with negligible loss in accuracy.