 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Chain-of-Thought in Large Language Models via Topological Data Analysis
Dec 22, 2025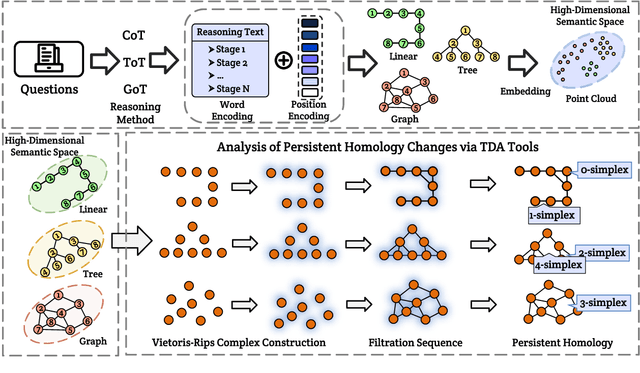
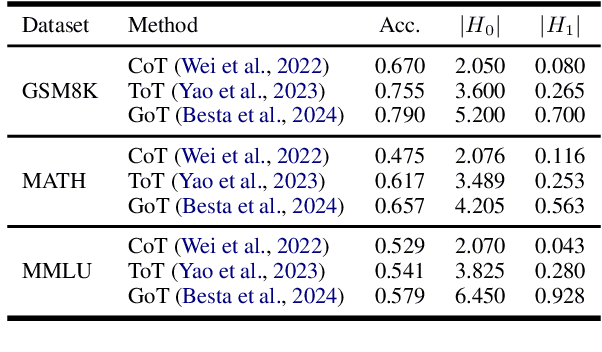
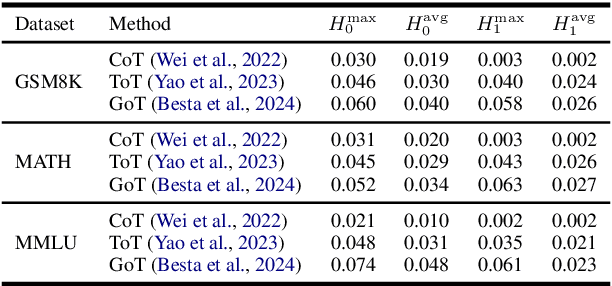
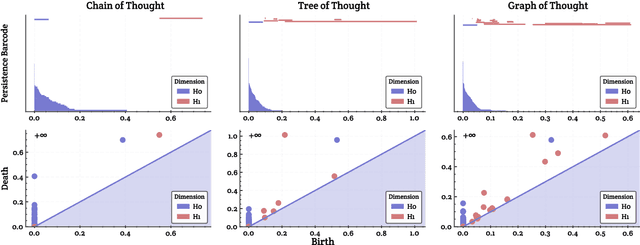
With the development of large language models (LLMs), particularly with the introduction of the long reasoning chain technique, the reasoning ability of LLMs in complex problem-solving has been significantly enhanced. While acknowledging the power of long reasoning chains, we cannot help but wonder: Why do different reasoning chains perform differently in reasoning? What components of the reasoning chains play a key role? Existing studies mainly focus on evaluating reasoning chains from a functional perspective, with little attention paid to their structural mechanisms. To address this gap, this work is the first to analyze and evaluate the quality of the reasoning chain from a structural perspective. We apply persistent homology from Topological Data Analysis (TDA) to map reasoning steps into semantic space, extract topological features, and analyze structural changes. These changes reveal semantic coherence, logical redundancy, and identify logical breaks and gaps. By calculating homology groups, we assess connectivity and redundancy at various scales, using barcode and persistence diagrams to quantify stability and consistency. Our results show that the topological structural complexity of reasoning chains correlates positively with accuracy. More complex chains identify correct answers sooner, while successful reasoning exhibits simpler topologies, reducing redundancy and cycles, enhancing efficiency and interpretability. This work provides a new perspective on reasoning chain quality assessment and offers guidance for future optimization.
RedVTP: Training-Free Acceleration of Diffusion Vision-Language Models Inference via Masked Token-Guided Visual Token Pruning
Nov 16, 2025



Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning and generation, yet their high computational demands remain a major challenge. Diffusion Vision-Language Models (DVLMs) are particularly attractive because they enable parallel token decoding, but the large number of visual tokens still significantly hinders their inference efficiency. While visual token pruning has been extensively studied for autoregressive VLMs (AVLMs), it remains largely unexplored for DVLMs. In this work, we propose RedVTP, a response-driven visual token pruning strategy that leverages the inference dynamics of DVLMs. Our method estimates visual token importance using attention from the masked response tokens. Based on the observation that these importance scores remain consistent across steps, RedVTP prunes the less important visual tokens from the masked tokens after the first inference step, thereby maximizing inference efficiency. Experiments show that RedVTP improves token generation throughput of LLaDA-V and LaViDa by up to 186% and 28.05%, respectively, and reduces inference latency by up to 64.97% and 21.87%, without compromising-and in some cases improving-accuracy.
Continual Knowledge Adaptation for Reinforcement Learning
Oct 22, 2025Reinforcement Learning enables agents to learn optimal behaviors through interactions with environments. However, real-world environments are typically non-stationary, requiring agents to continuously adapt to new tasks and changing conditions. Although Continual Reinforcement Learning facilitates learning across multiple tasks, existing methods often suffer from catastrophic forgetting and inefficient knowledge utilization. To address these challenges, we propose Continual Knowledge Adaptation for Reinforcement Learning (CKA-RL), which enables the accumulation and effective utilization of historical knowledge. Specifically, we introduce a Continual Knowledge Adaptation strategy, which involves maintaining a task-specific knowledge vector pool and dynamically using historical knowledge to adapt the agent to new tasks. This process mitigates catastrophic forgetting and enables efficient knowledge transfer across tasks by preserving and adapting critical model parameters. Additionally, we propose an Adaptive Knowledge Merging mechanism that combines similar knowledge vectors to address scalability challenges, reducing memory requirements while ensuring the retention of essential knowledge. Experiments on three benchmarks demonstrate that the proposed CKA-RL outperforms state-of-the-art methods, achieving an improvement of 4.20% in overall performance and 8.02% in forward transfer. The source code is available at https://github.com/Fhujinwu/CKA-RL.
GLIDE: A Coordinated Aerial-Ground Framework for Search and Rescue in Unknown Environments
Sep 17, 2025We present a cooperative aerial-ground search-and-rescue (SAR) framework that pairs two unmanned aerial vehicles (UAVs) with an unmanned ground vehicle (UGV) to achieve rapid victim localization and obstacle-aware navigation in unknown environments. We dub this framework Guided Long-horizon Integrated Drone Escort (GLIDE), highlighting the UGV's reliance on UAV guidance for long-horizon planning. In our framework, a goal-searching UAV executes real-time onboard victim detection and georeferencing to nominate goals for the ground platform, while a terrain-scouting UAV flies ahead of the UGV's planned route to provide mid-level traversability updates. The UGV fuses aerial cues with local sensing to perform time-efficient A* planning and continuous replanning as information arrives. Additionally, we present a hardware demonstration (using a GEM e6 golf cart as the UGV and two X500 UAVs) to evaluate end-to-end SAR mission performance and include simulation ablations to assess the planning stack in isolation from detection. Empirical results demonstrate that explicit role separation across UAVs, coupled with terrain scouting and guided planning, improves reach time and navigation safety in time-critical SAR missions.
Re-Initialization Token Learning for Tool-Augmented Large Language Models
Jun 17, 2025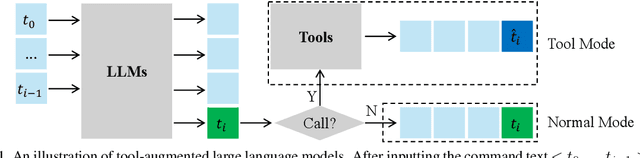
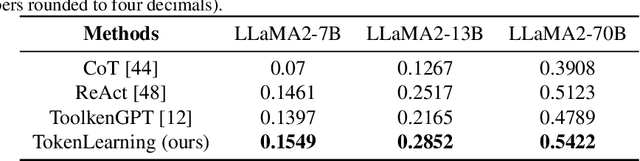
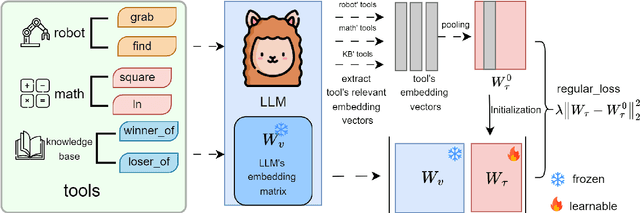
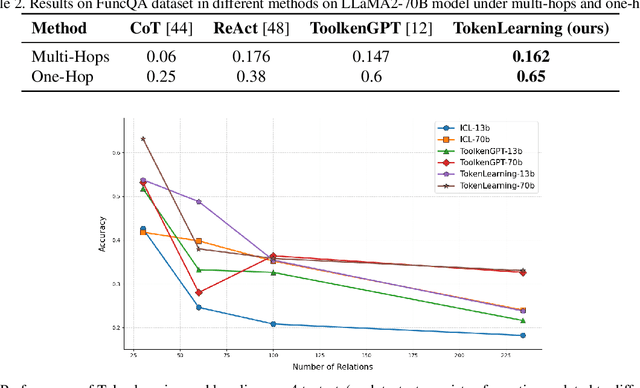
Large language models have demonstrated exceptional performance, yet struggle with complex tasks such as numerical reasoning, plan generation. Integrating external tools, such as calculators and databases, into large language models (LLMs) is crucial for enhancing problem-solving capabilities. Current methods assign a unique token to each tool, enabling LLMs to call tools through token prediction-similar to word generation. However, this approach fails to account for the relationship between tool and word tokens, limiting adaptability within pre-trained LLMs. To address this issue, we propose a novel token learning method that aligns tool tokens with the existing word embedding space from the perspective of initialization, thereby enhancing model performance. We begin by constructing prior token embeddings for each tool based on the tool's name or description, which are used to initialize and regularize the learnable tool token embeddings. This ensures the learned embeddings are well-aligned with the word token space, improving tool call accuracy. We evaluate the method on tasks such as numerical reasoning, knowledge-based question answering, and embodied plan generation using GSM8K-XL, FuncQA, KAMEL, and VirtualHome datasets. The results demonstrate clear improvements over recent baselines, including CoT, REACT, ICL, and ToolkenGPT, indicating that our approach effectively augments LLMs with tools through relevant tokens across diverse domains.
FPAN: Mitigating Replication in Diffusion Models through the Fine-Grained Probabilistic Addition of Noise to Token Embeddings
May 28, 2025Diffusion models have demonstrated remarkable potential in generating high-quality images. However, their tendency to replicate training data raises serious privacy concerns, particularly when the training datasets contain sensitive or private information. Existing mitigation strategies primarily focus on reducing image duplication, modifying the cross-attention mechanism, and altering the denoising backbone architecture of diffusion models. Moreover, recent work has shown that adding a consistent small amount of noise to text embeddings can reduce replication to some degree. In this work, we begin by analyzing the impact of adding varying amounts of noise. Based on our analysis, we propose a fine-grained noise injection technique that probabilistically adds a larger amount of noise to token embeddings. We refer to our method as Fine-grained Probabilistic Addition of Noise (FPAN). Through our extensive experiments, we show that our proposed FPAN can reduce replication by an average of 28.78% compared to the baseline diffusion model without significantly impacting image quality, and outperforms the prior consistent-magnitude-noise-addition approach by 26.51%. Moreover, when combined with other existing mitigation methods, our FPAN approach can further reduce replication by up to 16.82% with similar, if not improved, image quality.
Syzygy of Thoughts: Improving LLM CoT with the Minimal Free Resolution
Apr 16, 2025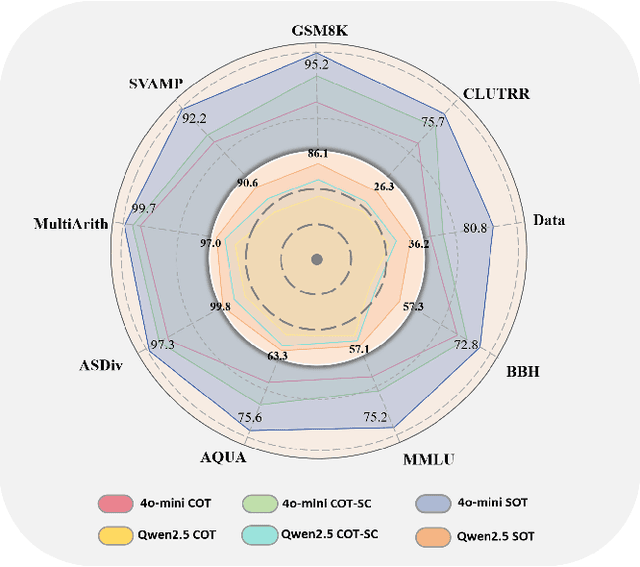
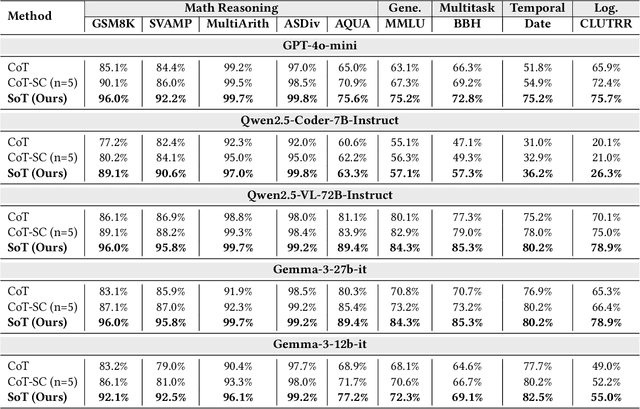
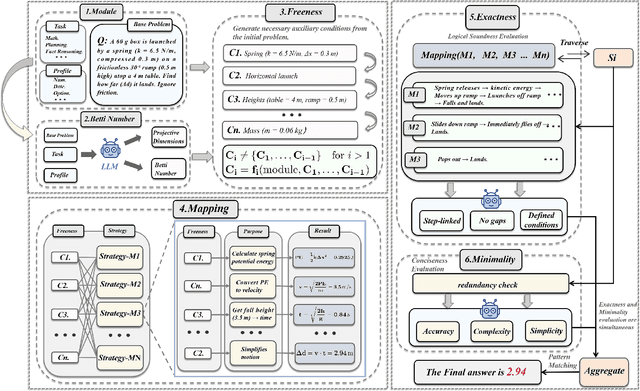

Chain-of-Thought (CoT) prompting enhances the reasoning of large language models (LLMs) by decomposing problems into sequential steps, mimicking human logic and reducing errors. However, complex tasks with vast solution spaces and vague constraints often exceed the capacity of a single reasoning chain. Inspired by Minimal Free Resolution (MFR) in commutative algebra and algebraic geometry, we propose Syzygy of Thoughts (SoT)-a novel framework that extends CoT by introducing auxiliary, interrelated reasoning paths. SoT captures deeper logical dependencies, enabling more robust and structured problem-solving. MFR decomposes a module into a sequence of free modules with minimal rank, providing a structured analytical approach to complex systems. This method introduces the concepts of "Module", "Betti numbers","Freeness", "Mapping", "Exactness" and "Minimality", enabling the systematic decomposition of the original complex problem into logically complete minimal subproblems while preserving key problem features and reducing reasoning length. We tested SoT across diverse datasets (e.g., GSM8K, MATH) and models (e.g., GPT-4o-mini, Qwen2.5), achieving inference accuracy that matches or surpasses mainstream CoTs standards. Additionally, by aligning the sampling process with algebraic constraints, our approach enhances the scalability of inference time in LLMs, ensuring both transparent reasoning and high performance. Our code will be publicly available at https://github.com/dlMARiA/Syzygy-of-thoughts.
Safe Human Robot Navigation in Warehouse Scenario
Mar 27, 2025The integration of autonomous mobile robots (AMRs) in industrial environments, particularly warehouses, has revolutionized logistics and operational efficiency. However, ensuring the safety of human workers in dynamic, shared spaces remains a critical challenge. This work proposes a novel methodology that leverages control barrier functions (CBFs) to enhance safety in warehouse navigation. By integrating learning-based CBFs with the Open Robotics Middleware Framework (OpenRMF), the system achieves adaptive and safety-enhanced controls in multi-robot, multi-agent scenarios. Experiments conducted using various robot platforms demonstrate the efficacy of the proposed approach in avoiding static and dynamic obstacles, including human pedestrians. Our experiments evaluate different scenarios in which the number of robots, robot platforms, speed, and number of obstacles are varied, from which we achieve promising performance.
Quality-focused Active Adversarial Policy for Safe Grasping in Human-Robot Interaction
Mar 25, 2025Vision-guided robot grasping methods based on Deep Neural Networks (DNNs) have achieved remarkable success in handling unknown objects, attributable to their powerful generalizability. However, these methods with this generalizability tend to recognize the human hand and its adjacent objects as graspable targets, compromising safety during Human-Robot Interaction (HRI). In this work, we propose the Quality-focused Active Adversarial Policy (QFAAP) to solve this problem. Specifically, the first part is the Adversarial Quality Patch (AQP), wherein we design the adversarial quality patch loss and leverage the grasp dataset to optimize a patch with high quality scores. Next, we construct the Projected Quality Gradient Descent (PQGD) and integrate it with the AQP, which contains only the hand region within each real-time frame, endowing the AQP with fast adaptability to the human hand shape. Through AQP and PQGD, the hand can be actively adversarial with the surrounding objects, lowering their quality scores. Therefore, further setting the quality score of the hand to zero will reduce the grasping priority of both the hand and its adjacent objects, enabling the robot to grasp other objects away from the hand without emergency stops. We conduct extensive experiments on the benchmark datasets and a cobot, showing the effectiveness of QFAAP. Our code and demo videos are available here: https://github.com/clee-jaist/QFAAP.
Fewer May Be Better: Enhancing Offline Reinforcement Learning with Reduced Dataset
Feb 26, 2025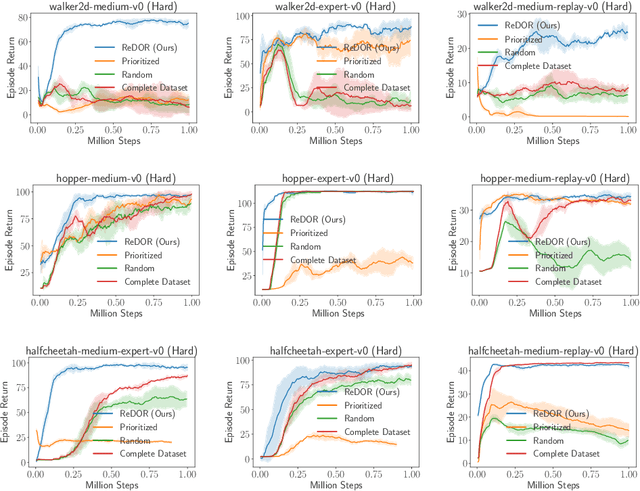
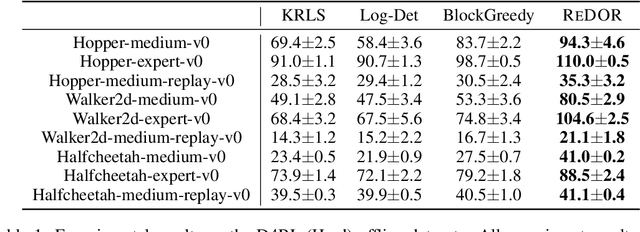

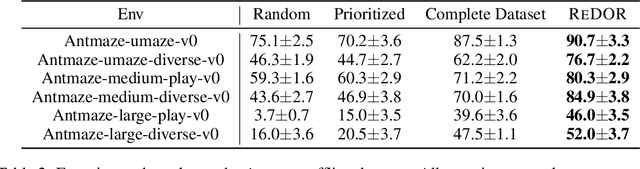
Offline reinforcement learning (RL) represents a significant shift in RL research, allowing agents to learn from pre-collected datasets without further interaction with the environment. A key, yet underexplored, challenge in offline RL is selecting an optimal subset of the offline dataset that enhances both algorithm performance and training efficiency. Reducing dataset size can also reveal the minimal data requirements necessary for solving similar problems. In response to this challenge, we introduce ReDOR (Reduced Datasets for Offline RL), a method that frames dataset selection as a gradient approximation optimization problem. We demonstrate that the widely used actor-critic framework in RL can be reformulated as a submodular optimization objective, enabling efficient subset selection. To achieve this, we adapt orthogonal matching pursuit (OMP), incorporating several novel modifications tailored for offline RL. Our experimental results show that the data subsets identified by ReDOR not only boost algorithm performance but also do so with significantly lower computational complexity.