 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLKCA: Large Kernel Convolutional Attention
Jan 11, 2024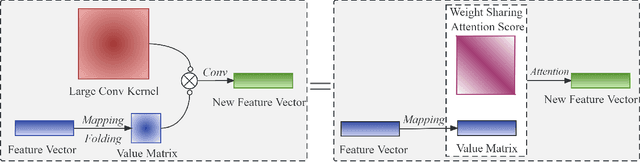
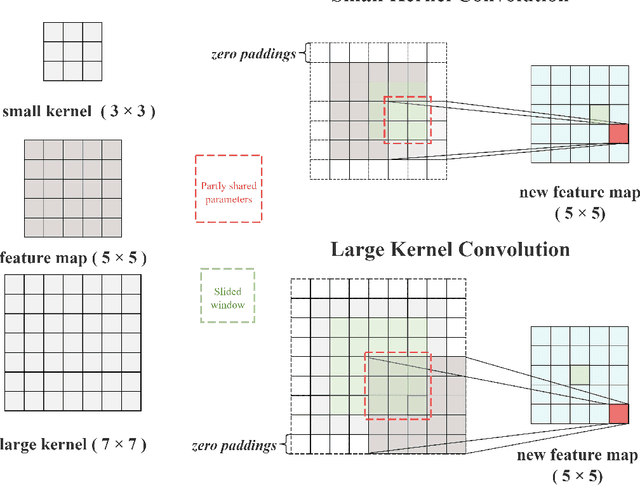
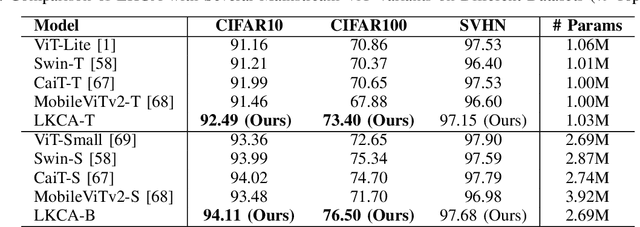
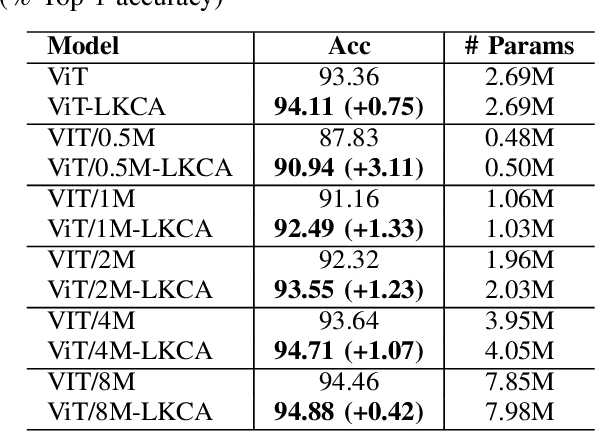
We revisit the relationship between attention mechanisms and large kernel ConvNets in visual transformers and propose a new spatial attention named Large Kernel Convolutional Attention (LKCA). It simplifies the attention operation by replacing it with a single large kernel convolution. LKCA combines the advantages of convolutional neural networks and visual transformers, possessing a large receptive field, locality, and parameter sharing. We explained the superiority of LKCA from both convolution and attention perspectives, providing equivalent code implementations for each view. Experiments confirm that LKCA implemented from both the convolutional and attention perspectives exhibit equivalent performance. We extensively experimented with the LKCA variant of ViT in both classification and segmentation tasks. The experiments demonstrated that LKCA exhibits competitive performance in visual tasks. Our code will be made publicly available at https://github.com/CatworldLee/LKCA.
Boosting Adversarial Attacks by Leveraging Decision Boundary Information
Mar 10, 2023
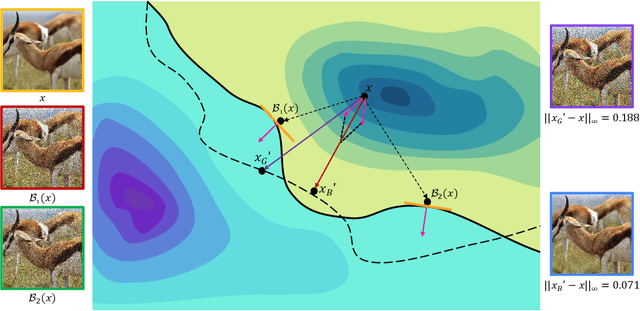
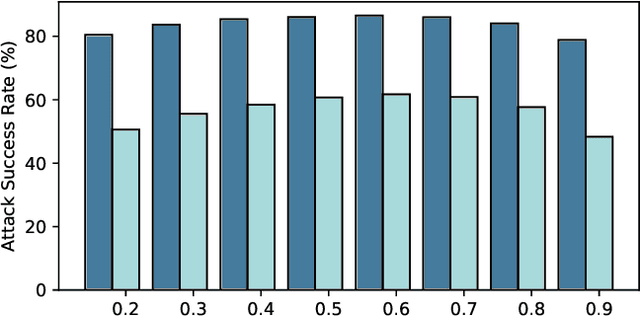
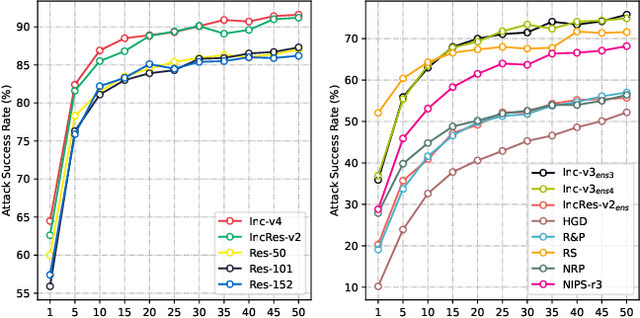
Due to the gap between a substitute model and a victim model, the gradient-based noise generated from a substitute model may have low transferability for a victim model since their gradients are different. Inspired by the fact that the decision boundaries of different models do not differ much, we conduct experiments and discover that the gradients of different models are more similar on the decision boundary than in the original position. Moreover, since the decision boundary in the vicinity of an input image is flat along most directions, we conjecture that the boundary gradients can help find an effective direction to cross the decision boundary of the victim models. Based on it, we propose a Boundary Fitting Attack to improve transferability. Specifically, we introduce a method to obtain a set of boundary points and leverage the gradient information of these points to update the adversarial examples. Notably, our method can be combined with existing gradient-based methods. Extensive experiments prove the effectiveness of our method, i.e., improving the success rate by 5.6% against normally trained CNNs and 14.9% against defense CNNs on average compared to state-of-the-art transfer-based attacks. Further we compare transformers with CNNs, the results indicate that transformers are more robust than CNNs. However, our method still outperforms existing methods when attacking transformers. Specifically, when using CNNs as substitute models, our method obtains an average attack success rate of 58.2%, which is 10.8% higher than other state-of-the-art transfer-based attacks.
Frequency Domain Model Augmentation for Adversarial Attack
Jul 12, 2022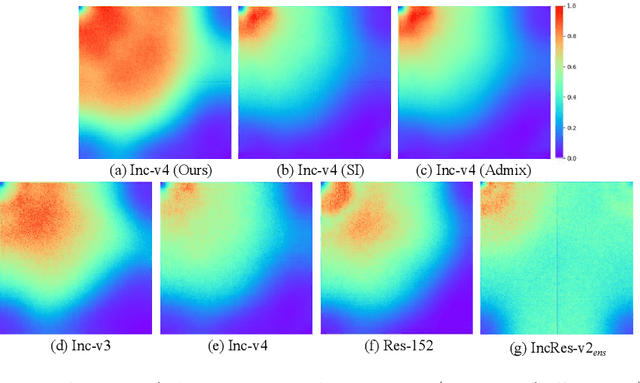
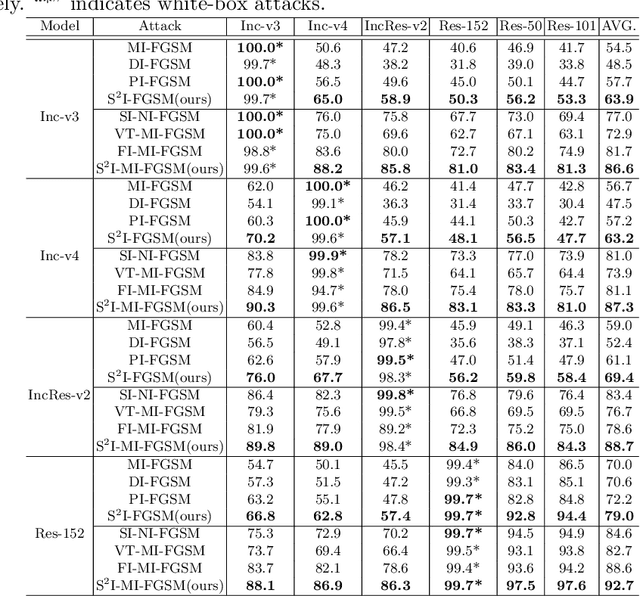


For black-box attacks, the gap between the substitute model and the victim model is usually large, which manifests as a weak attack performance. Motivated by the observation that the transferability of adversarial examples can be improved by attacking diverse models simultaneously, model augmentation methods which simulate different models by using transformed images are proposed. However, existing transformations for spatial domain do not translate to significantly diverse augmented models. To tackle this issue, we propose a novel spectrum simulation attack to craft more transferable adversarial examples against both normally trained and defense models. Specifically, we apply a spectrum transformation to the input and thus perform the model augmentation in the frequency domain. We theoretically prove that the transformation derived from frequency domain leads to a diverse spectrum saliency map, an indicator we proposed to reflect the diversity of substitute models. Notably, our method can be generally combined with existing attacks. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our method, \textit{e.g.}, attacking nine state-of-the-art defense models with an average success rate of \textbf{95.4\%}. Our code is available in \url{https://github.com/yuyang-long/SSA}.