 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D object-centric representation through prediction
Mar 06, 2024

As part of human core knowledge, the representation of objects is the building block of mental representation that supports high-level concepts and symbolic reasoning. While humans develop the ability of perceiving objects situated in 3D environments without supervision, models that learn the same set of abilities with similar constraints faced by human infants are lacking. Towards this end, we developed a novel network architecture that simultaneously learns to 1) segment objects from discrete images, 2) infer their 3D locations, and 3) perceive depth, all while using only information directly available to the brain as training data, namely: sequences of images and self-motion. The core idea is treating objects as latent causes of visual input which the brain uses to make efficient predictions of future scenes. This results in object representations being learned as an essential byproduct of learning to predict.
LKCA: Large Kernel Convolutional Attention
Jan 11, 2024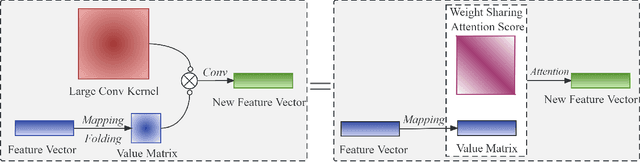
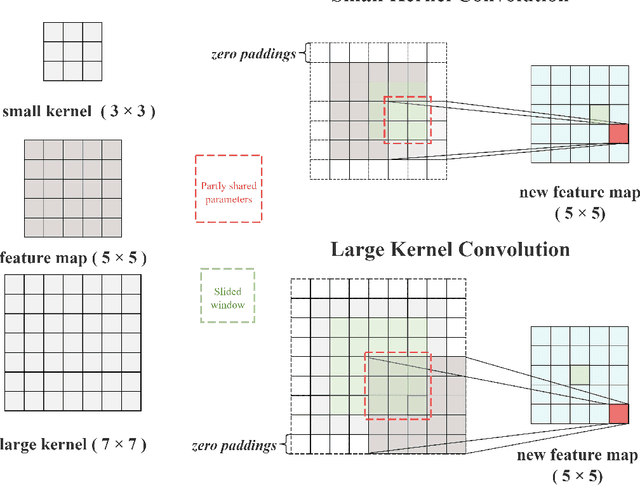
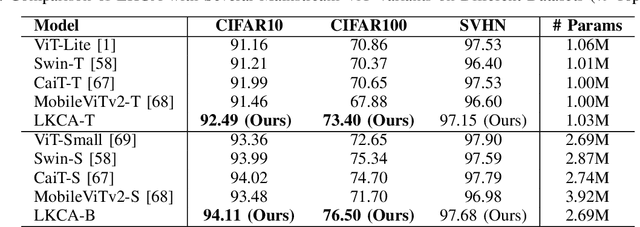
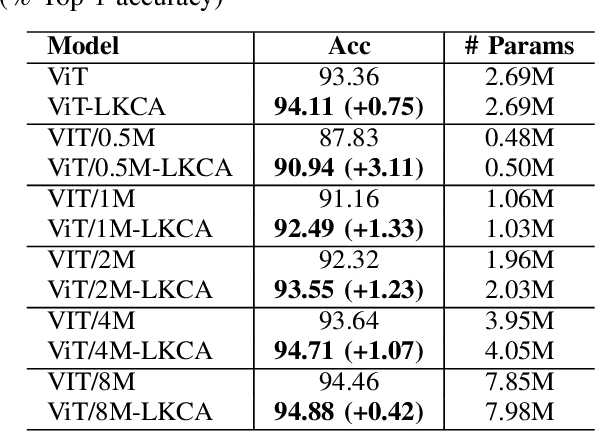
We revisit the relationship between attention mechanisms and large kernel ConvNets in visual transformers and propose a new spatial attention named Large Kernel Convolutional Attention (LKCA). It simplifies the attention operation by replacing it with a single large kernel convolution. LKCA combines the advantages of convolutional neural networks and visual transformers, possessing a large receptive field, locality, and parameter sharing. We explained the superiority of LKCA from both convolution and attention perspectives, providing equivalent code implementations for each view. Experiments confirm that LKCA implemented from both the convolutional and attention perspectives exhibit equivalent performance. We extensively experimented with the LKCA variant of ViT in both classification and segmentation tasks. The experiments demonstrated that LKCA exhibits competitive performance in visual tasks. Our code will be made publicly available at https://github.com/CatworldLee/LKCA.