 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D object-centric representation through prediction
Mar 06, 2024

As part of human core knowledge, the representation of objects is the building block of mental representation that supports high-level concepts and symbolic reasoning. While humans develop the ability of perceiving objects situated in 3D environments without supervision, models that learn the same set of abilities with similar constraints faced by human infants are lacking. Towards this end, we developed a novel network architecture that simultaneously learns to 1) segment objects from discrete images, 2) infer their 3D locations, and 3) perceive depth, all while using only information directly available to the brain as training data, namely: sequences of images and self-motion. The core idea is treating objects as latent causes of visual input which the brain uses to make efficient predictions of future scenes. This results in object representations being learned as an essential byproduct of learning to predict.
Implicit Equivariance in Convolutional Networks
Nov 28, 2021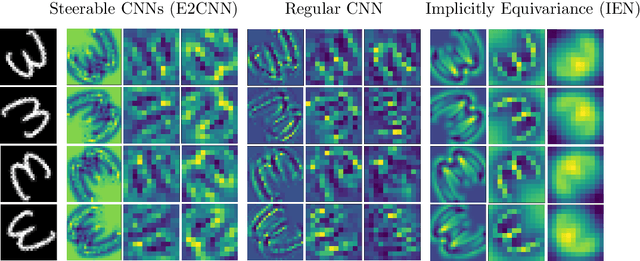
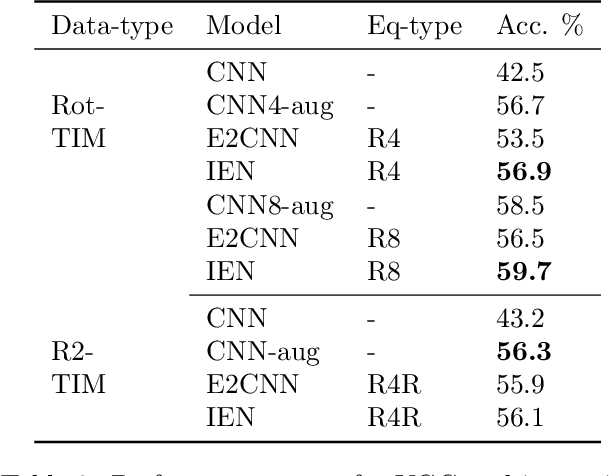
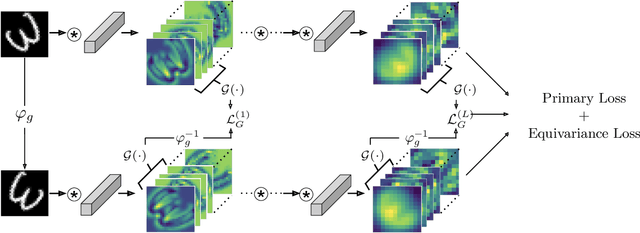
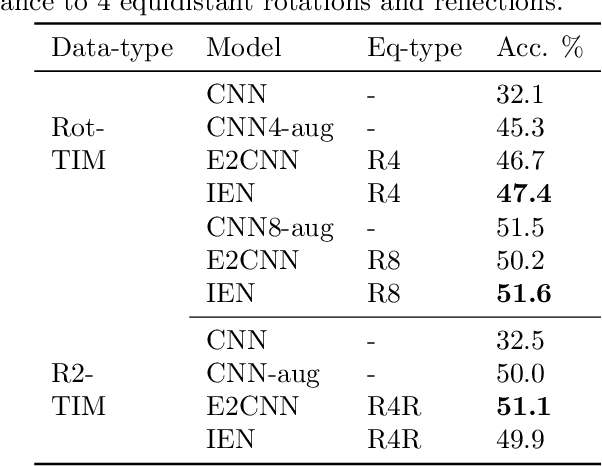
Convolutional Neural Networks(CNN) are inherently equivariant under translations, however, they do not have an equivalent embedded mechanism to handle other transformations such as rotations and change in scale. Several approaches exist that make CNNs equivariant under other transformation groups by design. Among these, steerable CNNs have been especially effective. However, these approaches require redesigning standard networks with filters mapped from combinations of predefined basis involving complex analytical functions. We experimentally demonstrate that these restrictions in the choice of basis can lead to model weights that are sub-optimal for the primary deep learning task (e.g. classification). Moreover, such hard-baked explicit formulations make it difficult to design composite networks comprising heterogeneous feature groups. To circumvent such issues, we propose Implicitly Equivariant Networks (IEN) which induce equivariance in the different layers of a standard CNN model by optimizing a multi-objective loss function that combines the primary loss with an equivariance loss term. Through experiments with VGG and ResNet models on Rot-MNIST , Rot-TinyImageNet, Scale-MNIST and STL-10 datasets, we show that IEN, even with its simple formulation, performs better than steerable networks. Also, IEN facilitates construction of heterogeneous filter groups allowing reduction in number of channels in CNNs by a factor of over 30% while maintaining performance on par with baselines. The efficacy of IEN is further validated on the hard problem of visual object tracking. We show that IEN outperforms the state-of-the-art rotation equivariant tracking method while providing faster inference speed.