 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable and Efficient Image Watermarking via Hierarchical Two-Stage Optimization
Aug 12, 2025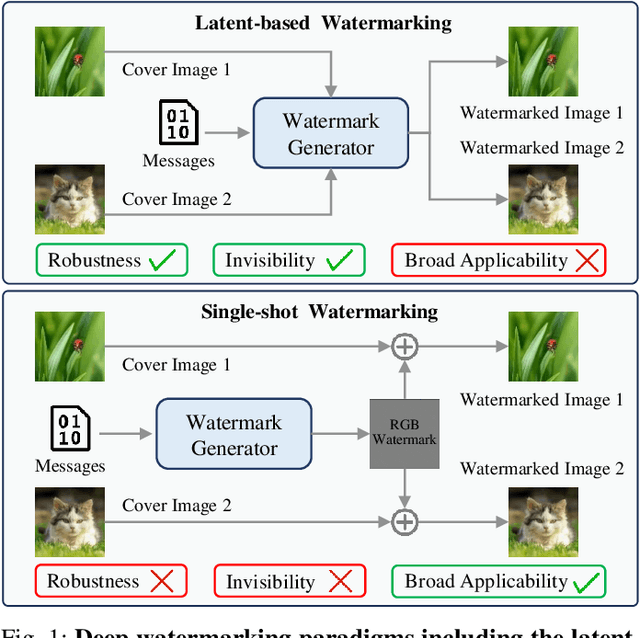

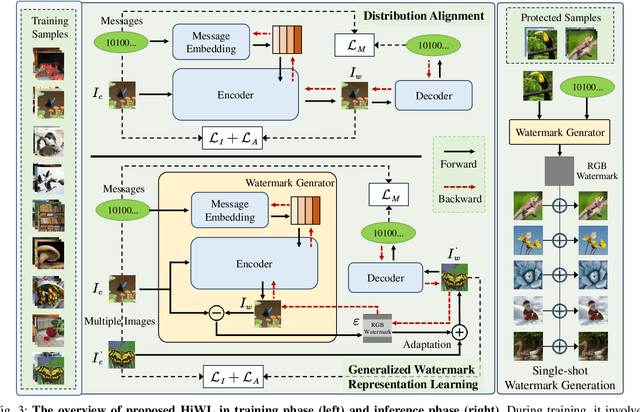

Deep image watermarking, which refers to enable imperceptible watermark embedding and reliable extraction in cover images, has shown to be effective for copyright protection of image assets. However, existing methods face limitations in simultaneously satisfying three essential criteria for generalizable watermarking: 1) invisibility (imperceptible hide of watermarks), 2) robustness (reliable watermark recovery under diverse conditions), and 3) broad applicability (low latency in watermarking process). To address these limitations, we propose a Hierarchical Watermark Learning (HiWL), a two-stage optimization that enable a watermarking model to simultaneously achieve three criteria. In the first stage, distribution alignment learning is designed to establish a common latent space with two constraints: 1) visual consistency between watermarked and non-watermarked images, and 2) information invariance across watermark latent representations. In this way, multi-modal inputs including watermark message (binary codes) and cover images (RGB pixels) can be well represented, ensuring the invisibility of watermarks and robustness in watermarking process thereby. The second stage employs generalized watermark representation learning to establish a disentanglement policy for separating watermarks from image content in RGB space. In particular, it strongly penalizes substantial fluctuations in separated RGB watermarks corresponding to identical messages. Consequently, HiWL effectively learns generalizable latent-space watermark representations while maintaining broad applicability. Extensive experiments demonstrate the effectiveness of proposed method. In particular, it achieves 7.6\% higher accuracy in watermark extraction than existing methods, while maintaining extremely low latency (100K images processed in 8s).
PILOC: A Pheromone Inverse Guidance Mechanism and Local-Communication Framework for Dynamic Target Search of Multi-Agent in Unknown Environments
Jul 10, 2025Multi-Agent Search and Rescue (MASAR) plays a vital role in disaster response, exploration, and reconnaissance. However, dynamic and unknown environments pose significant challenges due to target unpredictability and environmental uncertainty. To tackle these issues, we propose PILOC, a framework that operates without global prior knowledge, leveraging local perception and communication. It introduces a pheromone inverse guidance mechanism to enable efficient coordination and dynamic target localization. PILOC promotes decentralized cooperation through local communication, significantly reducing reliance on global channels. Unlike conventional heuristics, the pheromone mechanism is embedded into the observation space of Deep Reinforcement Learning (DRL), supporting indirect agent coordination based on environmental cues. We further integrate this strategy into a DRL-based multi-agent architecture and conduct extensive experiments. Results show that combining local communication with pheromone-based guidance significantly boosts search efficiency, adaptability, and system robustness. Compared to existing methods, PILOC performs better under dynamic and communication-constrained scenarios, offering promising directions for future MASAR applications.
Practical Deep Dispersed Watermarking with Synchronization and Fusion
Oct 23, 2023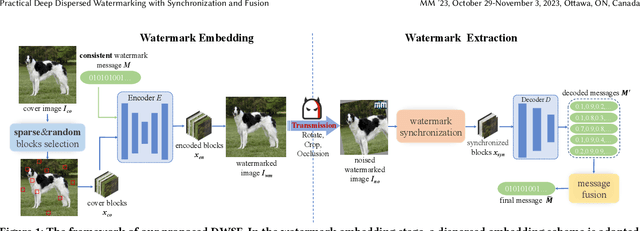

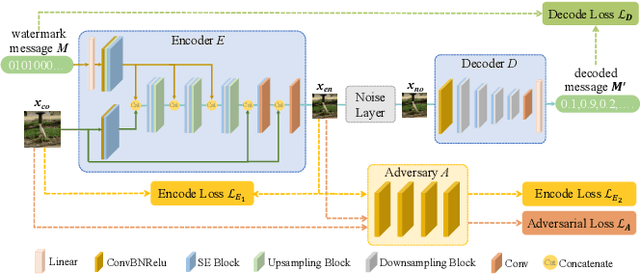
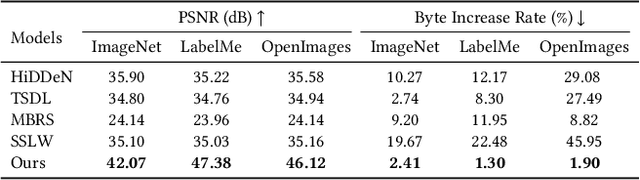
Deep learning based blind watermarking works have gradually emerged and achieved impressive performance. However, previous deep watermarking studies mainly focus on fixed low-resolution images while paying less attention to arbitrary resolution images, especially widespread high-resolution images nowadays. Moreover, most works usually demonstrate robustness against typical non-geometric attacks (\textit{e.g.}, JPEG compression) but ignore common geometric attacks (\textit{e.g.}, Rotate) and more challenging combined attacks. To overcome the above limitations, we propose a practical deep \textbf{D}ispersed \textbf{W}atermarking with \textbf{S}ynchronization and \textbf{F}usion, called \textbf{\proposed}. Specifically, given an arbitrary-resolution cover image, we adopt a dispersed embedding scheme which sparsely and randomly selects several fixed small-size cover blocks to embed a consistent watermark message by a well-trained encoder. In the extraction stage, we first design a watermark synchronization module to locate and rectify the encoded blocks in the noised watermarked image. We then utilize a decoder to obtain messages embedded in these blocks, and propose a message fusion strategy based on similarity to make full use of the consistency among messages, thus determining a reliable message. Extensive experiments conducted on different datasets convincingly demonstrate the effectiveness of our proposed {\proposed}. Compared with state-of-the-art approaches, our blind watermarking can achieve better performance: averagely improve the bit accuracy by 5.28\% and 5.93\% against single and combined attacks, respectively, and show less file size increment and better visual quality. Our code is available at https://github.com/bytedance/DWSF.
Natural Color Fool: Towards Boosting Black-box Unrestricted Attacks
Oct 05, 2022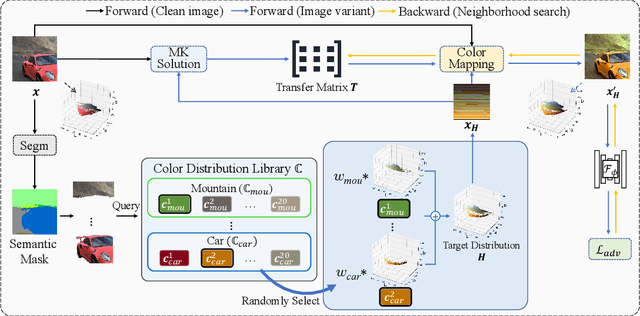
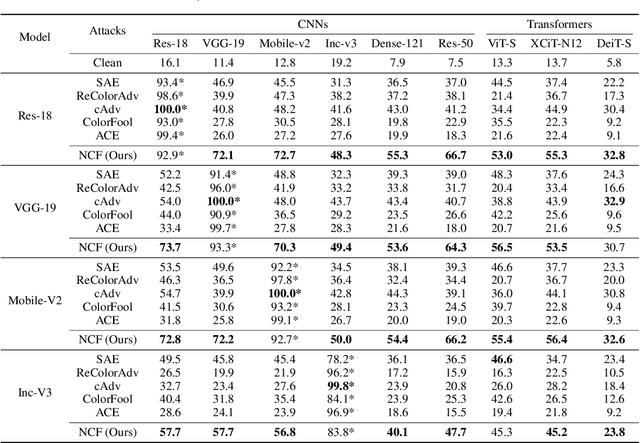

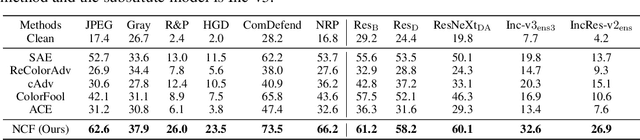
Unrestricted color attacks, which manipulate semantically meaningful color of an image, have shown their stealthiness and success in fooling both human eyes and deep neural networks. However, current works usually sacrifice the flexibility of the uncontrolled setting to ensure the naturalness of adversarial examples. As a result, the black-box attack performance of these methods is limited. To boost transferability of adversarial examples without damaging image quality, we propose a novel Natural Color Fool (NCF) which is guided by realistic color distributions sampled from a publicly available dataset and optimized by our neighborhood search and initialization reset. By conducting extensive experiments and visualizations, we convincingly demonstrate the effectiveness of our proposed method. Notably, on average, results show that our NCF can outperform state-of-the-art approaches by 15.0%$\sim$32.9% for fooling normally trained models and 10.0%$\sim$25.3% for evading defense methods. Our code is available at https://github.com/ylhz/Natural-Color-Fool.
Frequency Domain Model Augmentation for Adversarial Attack
Jul 12, 2022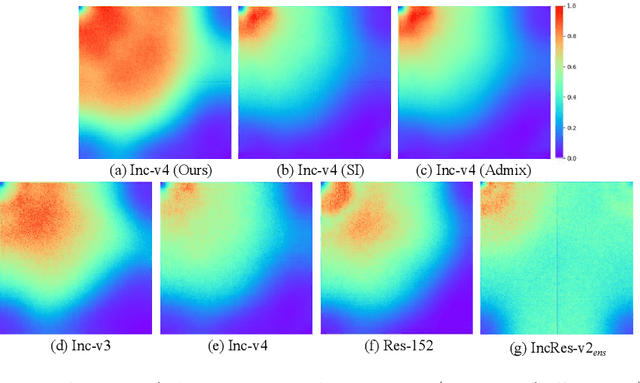
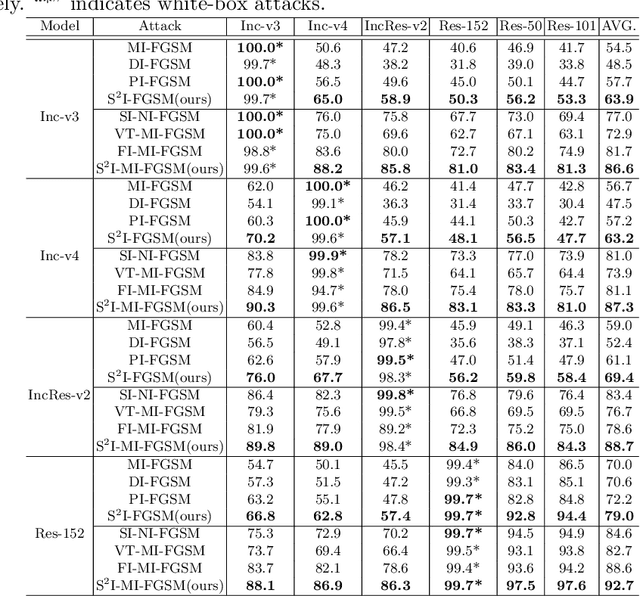


For black-box attacks, the gap between the substitute model and the victim model is usually large, which manifests as a weak attack performance. Motivated by the observation that the transferability of adversarial examples can be improved by attacking diverse models simultaneously, model augmentation methods which simulate different models by using transformed images are proposed. However, existing transformations for spatial domain do not translate to significantly diverse augmented models. To tackle this issue, we propose a novel spectrum simulation attack to craft more transferable adversarial examples against both normally trained and defense models. Specifically, we apply a spectrum transformation to the input and thus perform the model augmentation in the frequency domain. We theoretically prove that the transformation derived from frequency domain leads to a diverse spectrum saliency map, an indicator we proposed to reflect the diversity of substitute models. Notably, our method can be generally combined with existing attacks. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our method, \textit{e.g.}, attacking nine state-of-the-art defense models with an average success rate of \textbf{95.4\%}. Our code is available in \url{https://github.com/yuyang-long/SSA}.
Practical Evaluation of Adversarial Robustness via Adaptive Auto Attack
Mar 28, 2022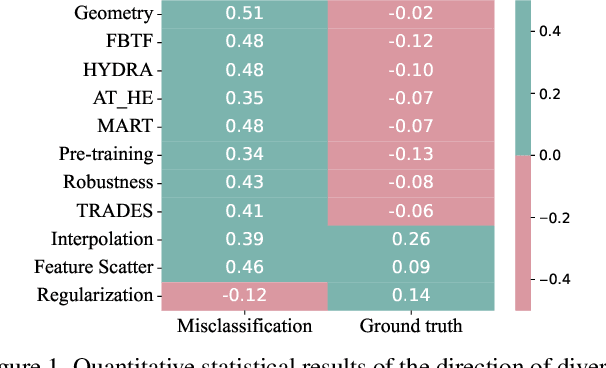
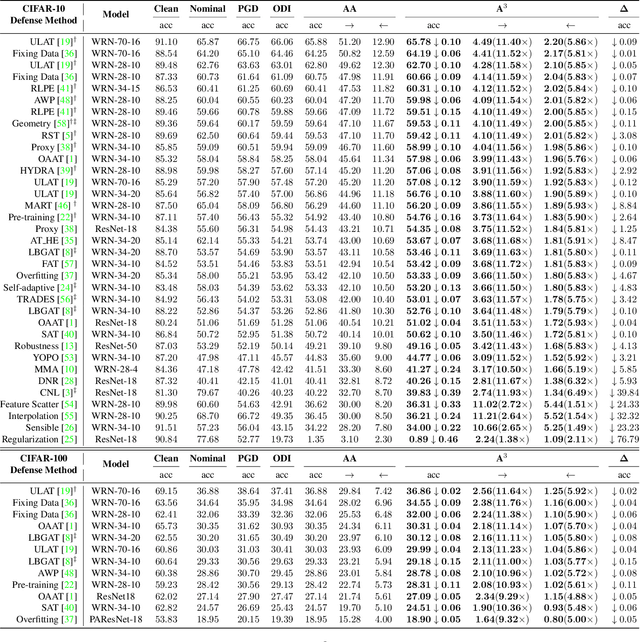
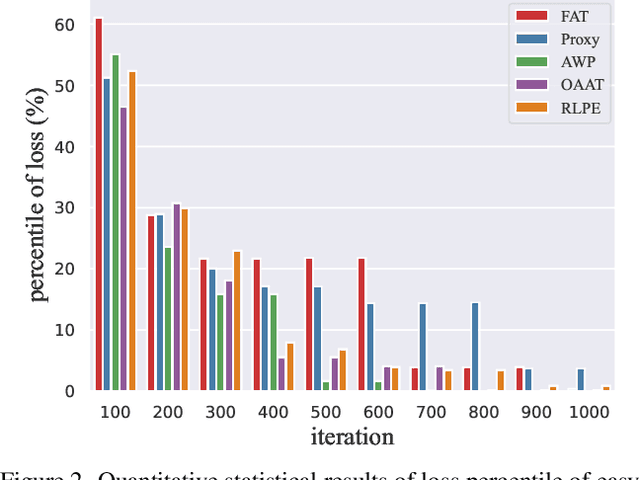
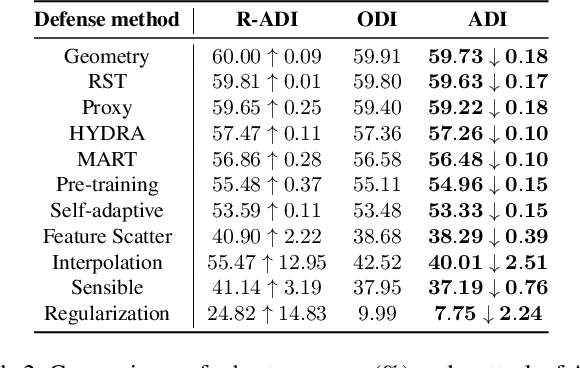
Defense models against adversarial attacks have grown significantly, but the lack of practical evaluation methods has hindered progress. Evaluation can be defined as looking for defense models' lower bound of robustness given a budget number of iterations and a test dataset. A practical evaluation method should be convenient (i.e., parameter-free), efficient (i.e., fewer iterations) and reliable (i.e., approaching the lower bound of robustness). Towards this target, we propose a parameter-free Adaptive Auto Attack (A$^3$) evaluation method which addresses the efficiency and reliability in a test-time-training fashion. Specifically, by observing that adversarial examples to a specific defense model follow some regularities in their starting points, we design an Adaptive Direction Initialization strategy to speed up the evaluation. Furthermore, to approach the lower bound of robustness under the budget number of iterations, we propose an online statistics-based discarding strategy that automatically identifies and abandons hard-to-attack images. Extensive experiments demonstrate the effectiveness of our A$^3$. Particularly, we apply A$^3$ to nearly 50 widely-used defense models. By consuming much fewer iterations than existing methods, i.e., $1/10$ on average (10$\times$ speed up), we achieve lower robust accuracy in all cases. Notably, we won $\textbf{first place}$ out of 1681 teams in CVPR 2021 White-box Adversarial Attacks on Defense Models competitions with this method. Code is available at: $\href{https://github.com/liuye6666/adaptive_auto_attack}{https://github.com/liuye6666/adaptive\_auto\_attack}$
Practical No-box Adversarial Attacks with Training-free Hybrid Image Transformation
Mar 09, 2022


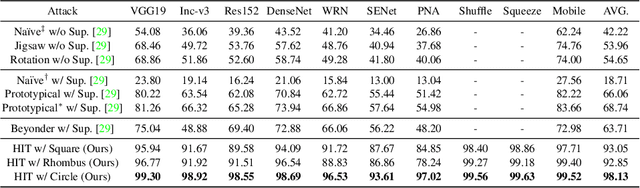
In recent years, the adversarial vulnerability of deep neural networks (DNNs) has raised increasing attention. Among all the threat models, no-box attacks are the most practical but extremely challenging since they neither rely on any knowledge of the target model or similar substitute model, nor access the dataset for training a new substitute model. Although a recent method has attempted such an attack in a loose sense, its performance is not good enough and computational overhead of training is expensive. In this paper, we move a step forward and show the existence of a \textbf{training-free} adversarial perturbation under the no-box threat model, which can be successfully used to attack different DNNs in real-time. Motivated by our observation that high-frequency component (HFC) domains in low-level features and plays a crucial role in classification, we attack an image mainly by manipulating its frequency components. Specifically, the perturbation is manipulated by suppression of the original HFC and adding of noisy HFC. We empirically and experimentally analyze the requirements of effective noisy HFC and show that it should be regionally homogeneous, repeating and dense. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our proposed no-box method. It attacks ten well-known models with a success rate of \textbf{98.13\%} on average, which outperforms state-of-the-art no-box attacks by \textbf{29.39\%}. Furthermore, our method is even competitive to mainstream transfer-based black-box attacks.
Beyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains
Feb 10, 2022
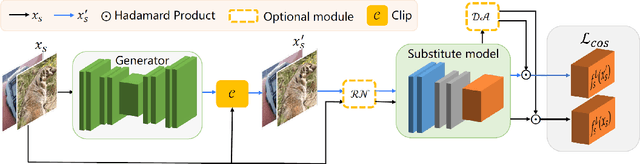

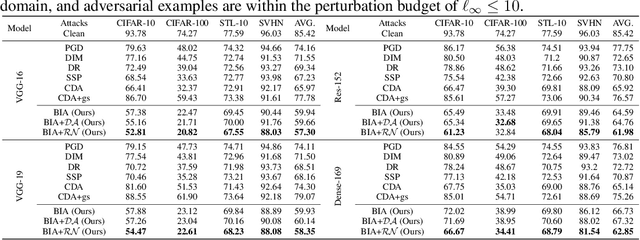
Adversarial examples have posed a severe threat to deep neural networks due to their transferable nature. Currently, various works have paid great efforts to enhance the cross-model transferability, which mostly assume the substitute model is trained in the same domain as the target model. However, in reality, the relevant information of the deployed model is unlikely to leak. Hence, it is vital to build a more practical black-box threat model to overcome this limitation and evaluate the vulnerability of deployed models. In this paper, with only the knowledge of the ImageNet domain, we propose a Beyond ImageNet Attack (BIA) to investigate the transferability towards black-box domains (unknown classification tasks). Specifically, we leverage a generative model to learn the adversarial function for disrupting low-level features of input images. Based on this framework, we further propose two variants to narrow the gap between the source and target domains from the data and model perspectives, respectively. Extensive experiments on coarse-grained and fine-grained domains demonstrate the effectiveness of our proposed methods. Notably, our methods outperform state-of-the-art approaches by up to 7.71\% (towards coarse-grained domains) and 25.91\% (towards fine-grained domains) on average. Our code is available at \url{https://github.com/qilong-zhang/Beyond-ImageNet-Attack}.
Fast Gradient Non-sign Methods
Oct 25, 2021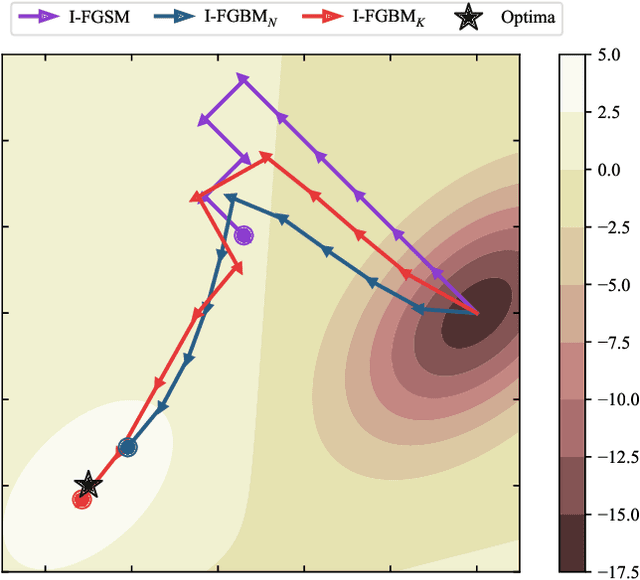

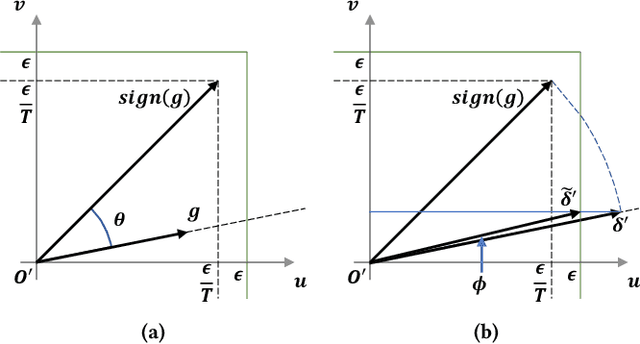
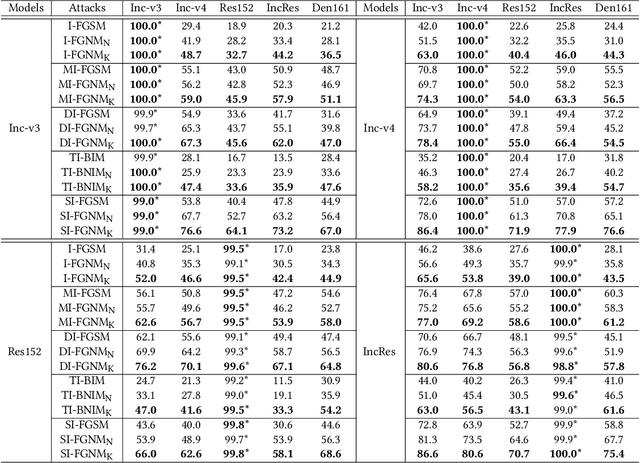
Adversarial attacks make their success in \enquote{fooling} DNNs and among them, gradient-based algorithms become one of the mainstreams. Based on the linearity hypothesis~\cite{fgsm}, under $\ell_\infty$ constraint, $sign$ operation applied to the gradients is a good choice for generating perturbations. However, the side-effect from such operation exists since it leads to the bias of direction between the real gradients and the perturbations. In other words, current methods contain a gap between real gradients and actual noises, which leads to biased and inefficient attacks. Therefore in this paper, based on the Taylor expansion, the bias is analyzed theoretically and the correction of $\sign$, \ie, Fast Gradient Non-sign Method (FGNM), is further proposed. Notably, FGNM is a general routine, which can seamlessly replace the conventional $sign$ operation in gradient-based attacks with negligible extra computational cost. Extensive experiments demonstrate the effectiveness of our methods. Specifically, ours outperform them by \textbf{27.5\%} at most and \textbf{9.5\%} on average. Our anonymous code is publicly available: \url{https://git.io/mm-fgnm}.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021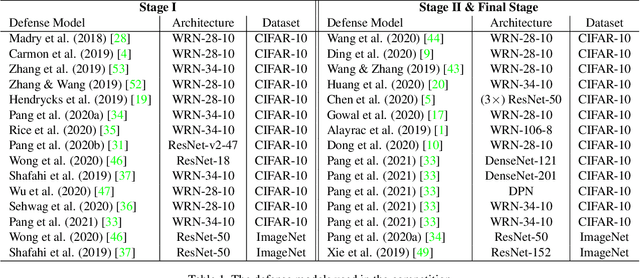
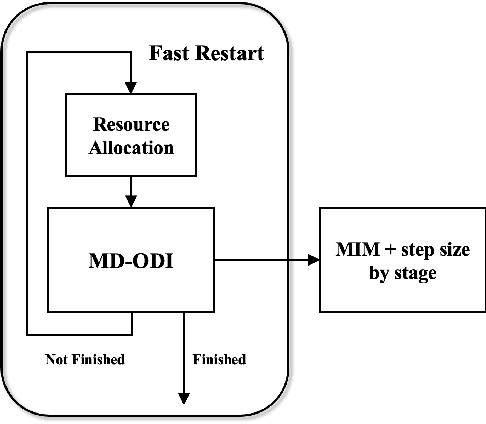
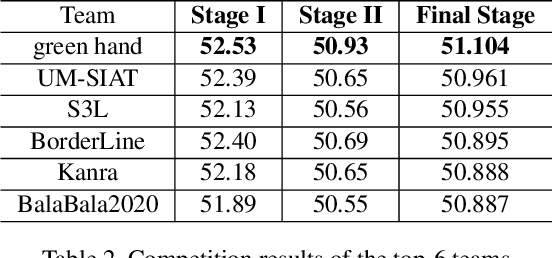
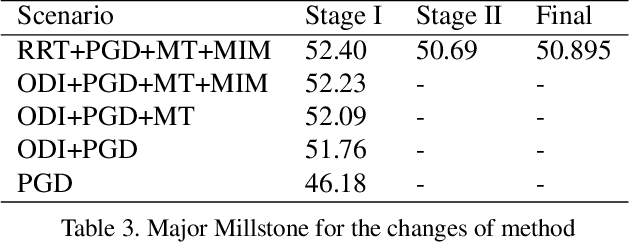
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.