 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Color Fool: Towards Boosting Black-box Unrestricted Attacks
Oct 05, 2022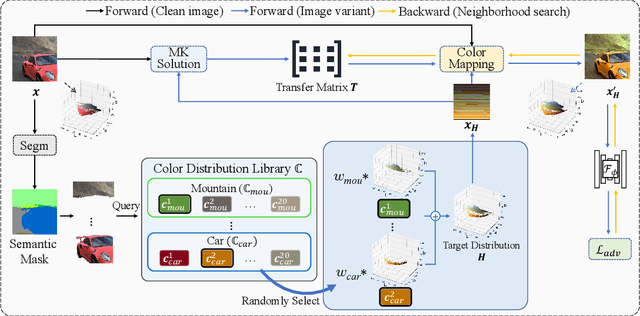
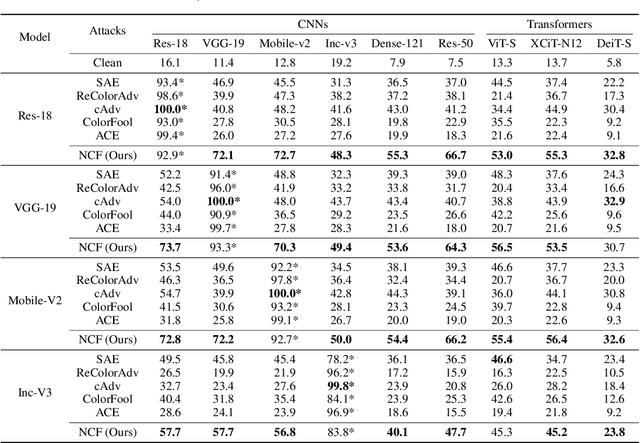

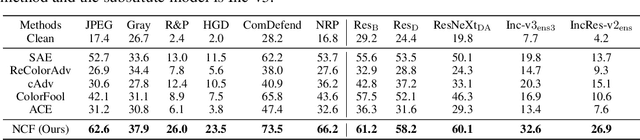
Unrestricted color attacks, which manipulate semantically meaningful color of an image, have shown their stealthiness and success in fooling both human eyes and deep neural networks. However, current works usually sacrifice the flexibility of the uncontrolled setting to ensure the naturalness of adversarial examples. As a result, the black-box attack performance of these methods is limited. To boost transferability of adversarial examples without damaging image quality, we propose a novel Natural Color Fool (NCF) which is guided by realistic color distributions sampled from a publicly available dataset and optimized by our neighborhood search and initialization reset. By conducting extensive experiments and visualizations, we convincingly demonstrate the effectiveness of our proposed method. Notably, on average, results show that our NCF can outperform state-of-the-art approaches by 15.0%$\sim$32.9% for fooling normally trained models and 10.0%$\sim$25.3% for evading defense methods. Our code is available at https://github.com/ylhz/Natural-Color-Fool.
Practical Evaluation of Adversarial Robustness via Adaptive Auto Attack
Mar 28, 2022
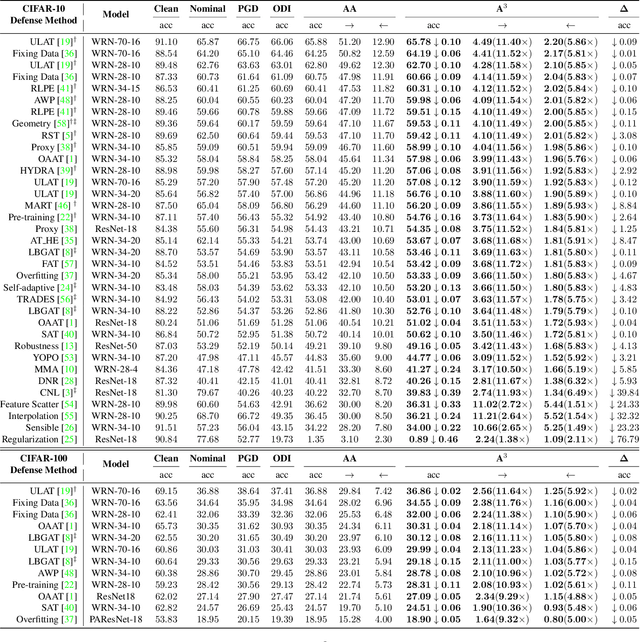
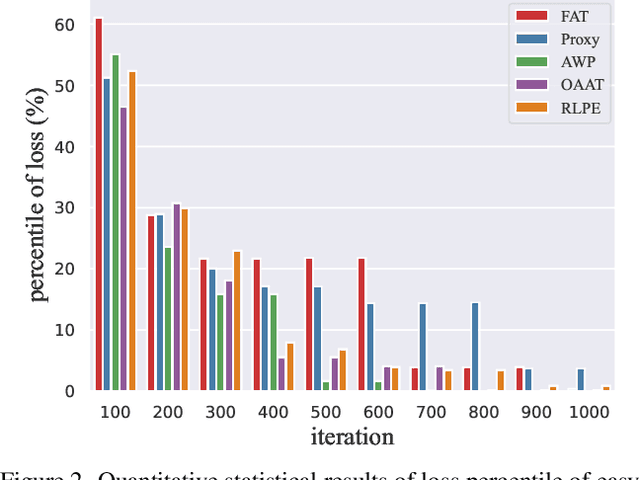
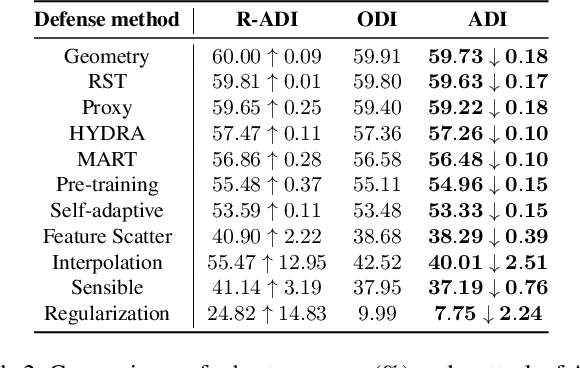
Defense models against adversarial attacks have grown significantly, but the lack of practical evaluation methods has hindered progress. Evaluation can be defined as looking for defense models' lower bound of robustness given a budget number of iterations and a test dataset. A practical evaluation method should be convenient (i.e., parameter-free), efficient (i.e., fewer iterations) and reliable (i.e., approaching the lower bound of robustness). Towards this target, we propose a parameter-free Adaptive Auto Attack (A$^3$) evaluation method which addresses the efficiency and reliability in a test-time-training fashion. Specifically, by observing that adversarial examples to a specific defense model follow some regularities in their starting points, we design an Adaptive Direction Initialization strategy to speed up the evaluation. Furthermore, to approach the lower bound of robustness under the budget number of iterations, we propose an online statistics-based discarding strategy that automatically identifies and abandons hard-to-attack images. Extensive experiments demonstrate the effectiveness of our A$^3$. Particularly, we apply A$^3$ to nearly 50 widely-used defense models. By consuming much fewer iterations than existing methods, i.e., $1/10$ on average (10$\times$ speed up), we achieve lower robust accuracy in all cases. Notably, we won $\textbf{first place}$ out of 1681 teams in CVPR 2021 White-box Adversarial Attacks on Defense Models competitions with this method. Code is available at: $\href{https://github.com/liuye6666/adaptive_auto_attack}{https://github.com/liuye6666/adaptive\_auto\_attack}$
Fast Gradient Non-sign Methods
Oct 25, 2021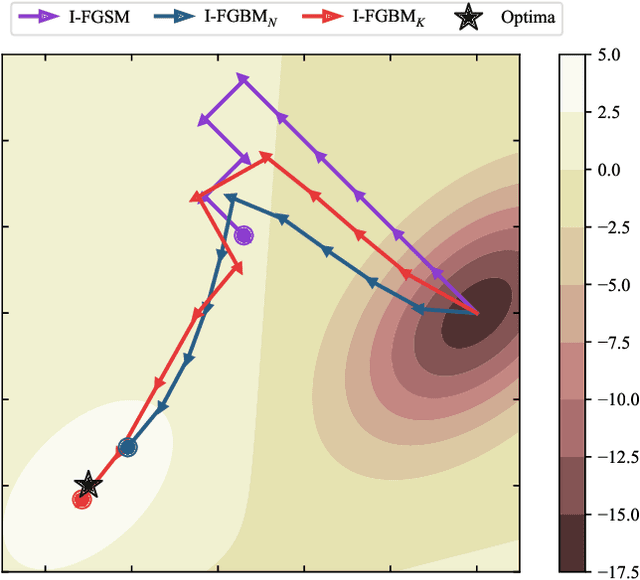

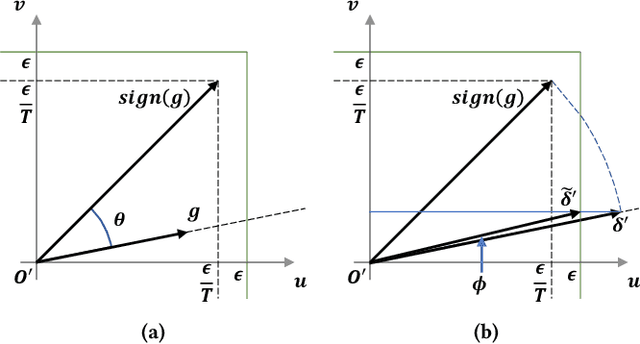
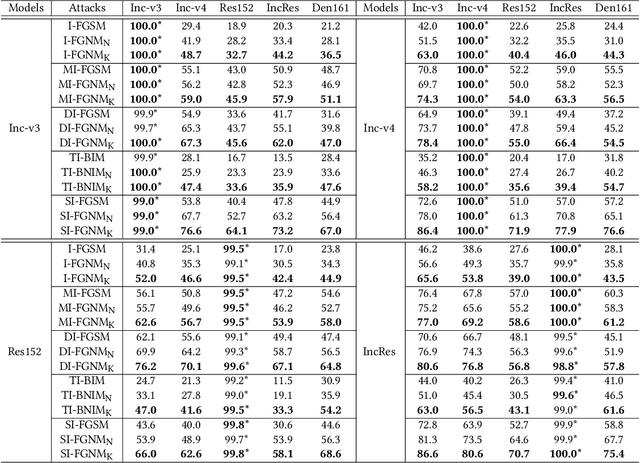
Adversarial attacks make their success in \enquote{fooling} DNNs and among them, gradient-based algorithms become one of the mainstreams. Based on the linearity hypothesis~\cite{fgsm}, under $\ell_\infty$ constraint, $sign$ operation applied to the gradients is a good choice for generating perturbations. However, the side-effect from such operation exists since it leads to the bias of direction between the real gradients and the perturbations. In other words, current methods contain a gap between real gradients and actual noises, which leads to biased and inefficient attacks. Therefore in this paper, based on the Taylor expansion, the bias is analyzed theoretically and the correction of $\sign$, \ie, Fast Gradient Non-sign Method (FGNM), is further proposed. Notably, FGNM is a general routine, which can seamlessly replace the conventional $sign$ operation in gradient-based attacks with negligible extra computational cost. Extensive experiments demonstrate the effectiveness of our methods. Specifically, ours outperform them by \textbf{27.5\%} at most and \textbf{9.5\%} on average. Our anonymous code is publicly available: \url{https://git.io/mm-fgnm}.
Feature Space Targeted Attacks by Statistic Alignment
May 25, 2021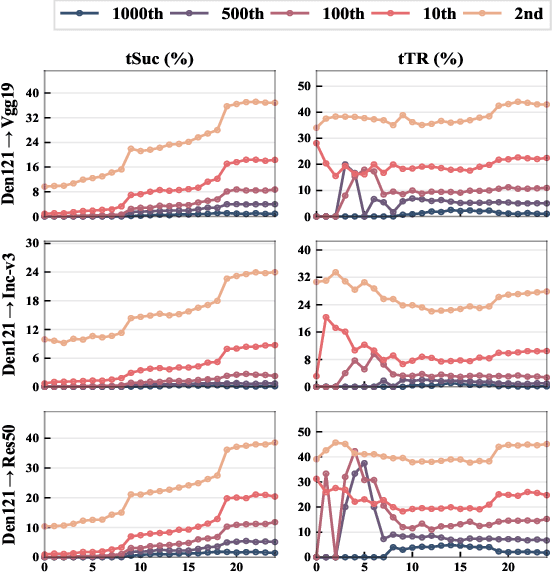
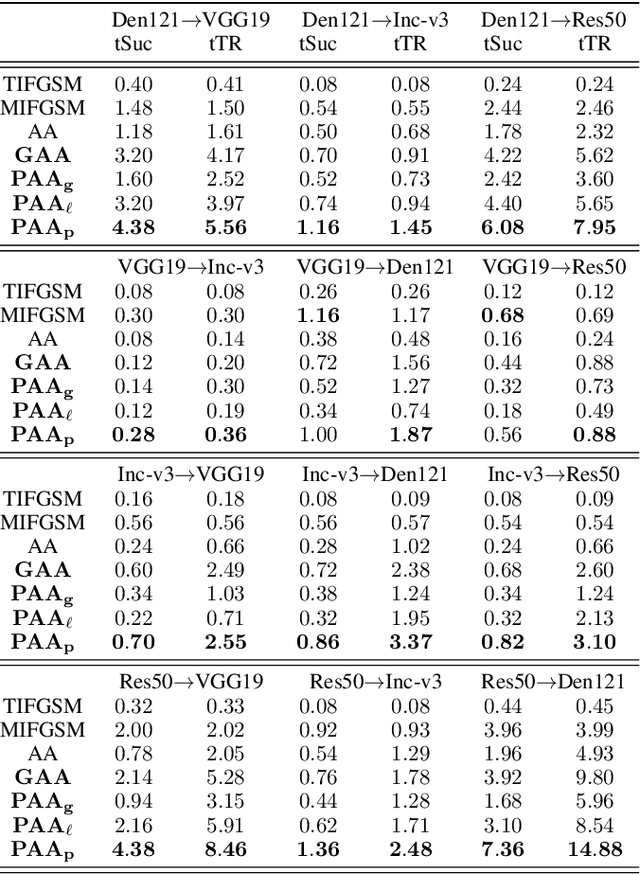
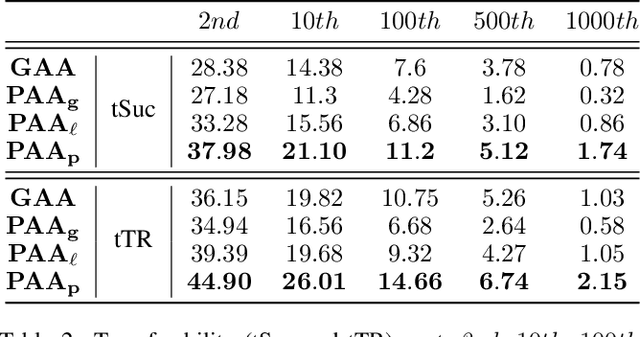
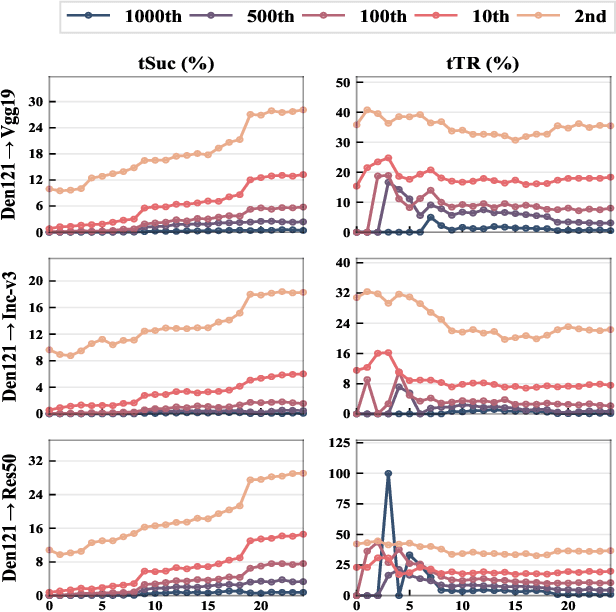
By adding human-imperceptible perturbations to images, DNNs can be easily fooled. As one of the mainstream methods, feature space targeted attacks perturb images by modulating their intermediate feature maps, for the discrepancy between the intermediate source and target features is minimized. However, the current choice of pixel-wise Euclidean Distance to measure the discrepancy is questionable because it unreasonably imposes a spatial-consistency constraint on the source and target features. Intuitively, an image can be categorized as "cat" no matter the cat is on the left or right of the image. To address this issue, we propose to measure this discrepancy using statistic alignment. Specifically, we design two novel approaches called Pair-wise Alignment Attack and Global-wise Alignment Attack, which attempt to measure similarities between feature maps by high-order statistics with translation invariance. Furthermore, we systematically analyze the layer-wise transferability with varied difficulties to obtain highly reliable attacks. Extensive experiments verify the effectiveness of our proposed method, and it outperforms the state-of-the-art algorithms by a large margin. Our code is publicly available at https://github.com/yaya-cheng/PAA-GAA.