 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception
May 17, 2024



We introduce RoScenes, the largest multi-view roadside perception dataset, which aims to shed light on the development of vision-centric Bird's Eye View (BEV) approaches for more challenging traffic scenes. The highlights of RoScenes include significantly large perception area, full scene coverage and crowded traffic. More specifically, our dataset achieves surprising 21.13M 3D annotations within 64,000 $m^2$. To relieve the expensive costs of roadside 3D labeling, we present a novel BEV-to-3D joint annotation pipeline to efficiently collect such a large volume of data. After that, we organize a comprehensive study for current BEV methods on RoScenes in terms of effectiveness and efficiency. Tested methods suffer from the vast perception area and variation of sensor layout across scenes, resulting in performance levels falling below expectations. To this end, we propose RoBEV that incorporates feature-guided position embedding for effective 2D-3D feature assignment. With its help, our method outperforms state-of-the-art by a large margin without extra computational overhead on validation set. Our dataset and devkit will be made available at https://github.com/xiaosu-zhu/RoScenes.
CUCL: Codebook for Unsupervised Continual Learning
Nov 25, 2023The focus of this study is on Unsupervised Continual Learning (UCL), as it presents an alternative to Supervised Continual Learning which needs high-quality manual labeled data. The experiments under the UCL paradigm indicate a phenomenon where the results on the first few tasks are suboptimal. This phenomenon can render the model inappropriate for practical applications. To address this issue, after analyzing the phenomenon and identifying the lack of diversity as a vital factor, we propose a method named Codebook for Unsupervised Continual Learning (CUCL) which promotes the model to learn discriminative features to complete the class boundary. Specifically, we first introduce a Product Quantization to inject diversity into the representation and apply a cross quantized contrastive loss between the original representation and the quantized one to capture discriminative information. Then, based on the quantizer, we propose an effective Codebook Rehearsal to address catastrophic forgetting. This study involves conducting extensive experiments on CIFAR100, TinyImageNet, and MiniImageNet benchmark datasets. Our method significantly boosts the performances of supervised and unsupervised methods. For instance, on TinyImageNet, our method led to a relative improvement of 12.76% and 7% when compared with Simsiam and BYOL, respectively.
Prototype-based Aleatoric Uncertainty Quantification for Cross-modal Retrieval
Sep 29, 2023Cross-modal Retrieval methods build similarity relations between vision and language modalities by jointly learning a common representation space. However, the predictions are often unreliable due to the Aleatoric uncertainty, which is induced by low-quality data, e.g., corrupt images, fast-paced videos, and non-detailed texts. In this paper, we propose a novel Prototype-based Aleatoric Uncertainty Quantification (PAU) framework to provide trustworthy predictions by quantifying the uncertainty arisen from the inherent data ambiguity. Concretely, we first construct a set of various learnable prototypes for each modality to represent the entire semantics subspace. Then Dempster-Shafer Theory and Subjective Logic Theory are utilized to build an evidential theoretical framework by associating evidence with Dirichlet Distribution parameters. The PAU model induces accurate uncertainty and reliable predictions for cross-modal retrieval. Extensive experiments are performed on four major benchmark datasets of MSR-VTT, MSVD, DiDeMo, and MS-COCO, demonstrating the effectiveness of our method. The code is accessible at https://github.com/leolee99/PAU.
A Lower Bound of Hash Codes' Performance
Oct 12, 2022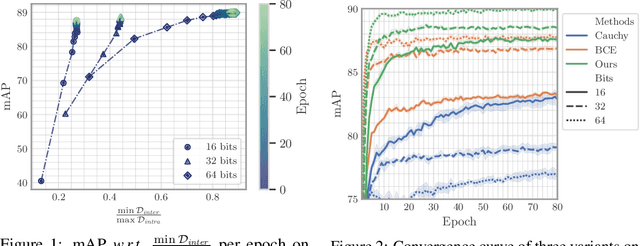
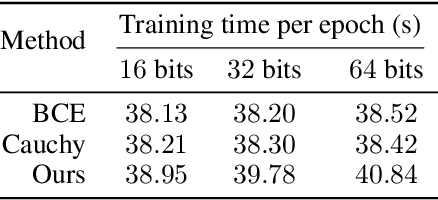
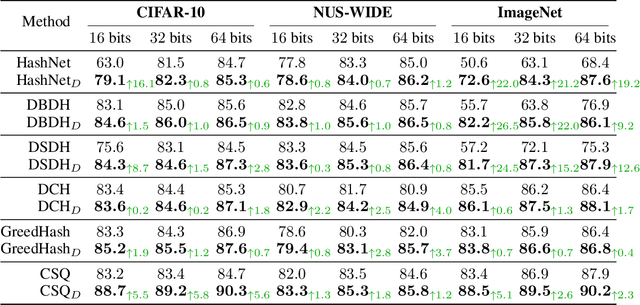
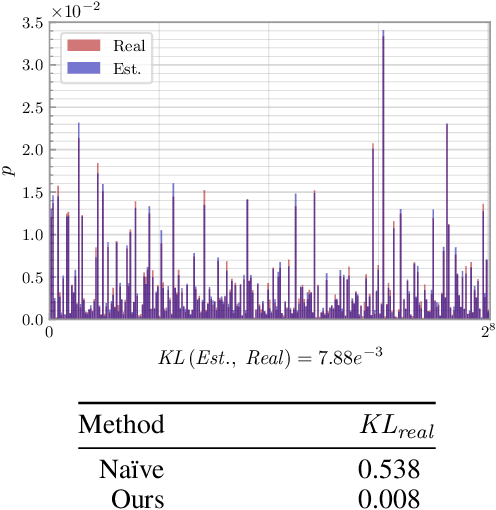
As a crucial approach for compact representation learning, hashing has achieved great success in effectiveness and efficiency. Numerous heuristic Hamming space metric learning objectives are designed to obtain high-quality hash codes. Nevertheless, a theoretical analysis of criteria for learning good hash codes remains largely unexploited. In this paper, we prove that inter-class distinctiveness and intra-class compactness among hash codes determine the lower bound of hash codes' performance. Promoting these two characteristics could lift the bound and improve hash learning. We then propose a surrogate model to fully exploit the above objective by estimating the posterior of hash codes and controlling it, which results in a low-bias optimization. Extensive experiments reveal the effectiveness of the proposed method. By testing on a series of hash-models, we obtain performance improvements among all of them, with an up to $26.5\%$ increase in mean Average Precision and an up to $20.5\%$ increase in accuracy. Our code is publicly available at \url{https://github.com/VL-Group/LBHash}.
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022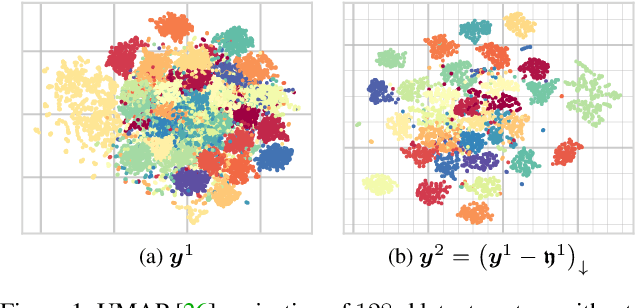
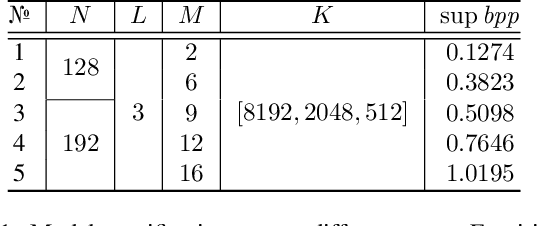
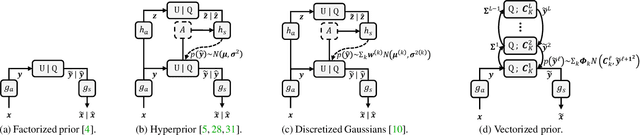
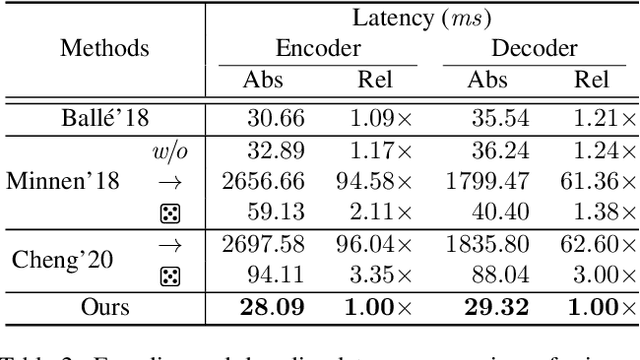
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022
Fast Gradient Non-sign Methods
Oct 25, 2021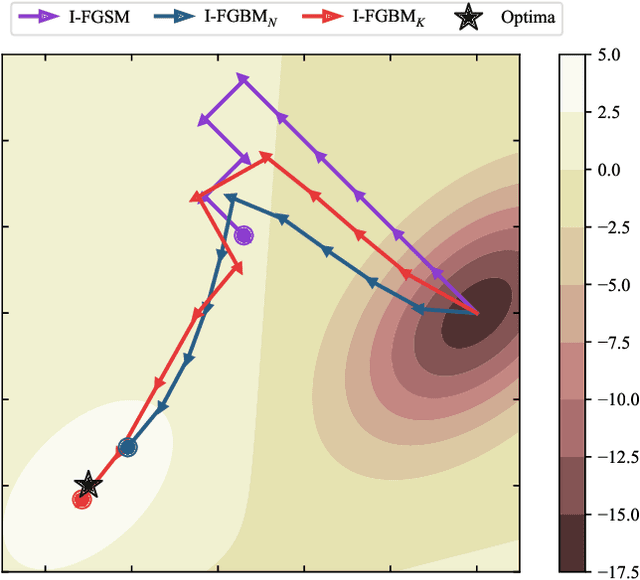

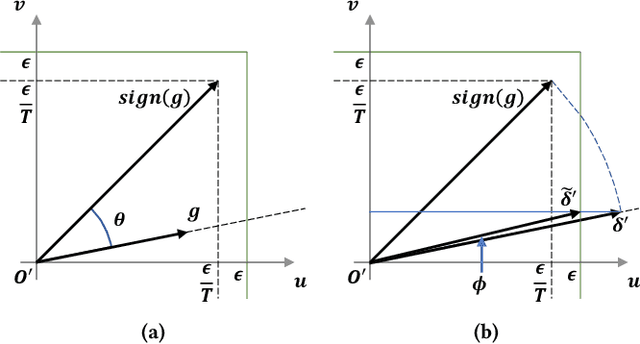
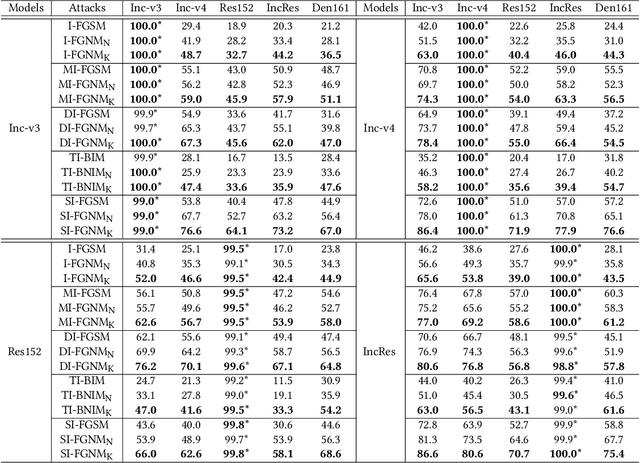
Adversarial attacks make their success in \enquote{fooling} DNNs and among them, gradient-based algorithms become one of the mainstreams. Based on the linearity hypothesis~\cite{fgsm}, under $\ell_\infty$ constraint, $sign$ operation applied to the gradients is a good choice for generating perturbations. However, the side-effect from such operation exists since it leads to the bias of direction between the real gradients and the perturbations. In other words, current methods contain a gap between real gradients and actual noises, which leads to biased and inefficient attacks. Therefore in this paper, based on the Taylor expansion, the bias is analyzed theoretically and the correction of $\sign$, \ie, Fast Gradient Non-sign Method (FGNM), is further proposed. Notably, FGNM is a general routine, which can seamlessly replace the conventional $sign$ operation in gradient-based attacks with negligible extra computational cost. Extensive experiments demonstrate the effectiveness of our methods. Specifically, ours outperform them by \textbf{27.5\%} at most and \textbf{9.5\%} on average. Our anonymous code is publicly available: \url{https://git.io/mm-fgnm}.
Staircase Sign Method for Boosting Adversarial Attacks
Apr 20, 2021
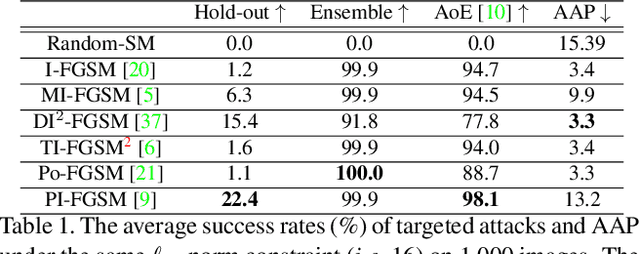
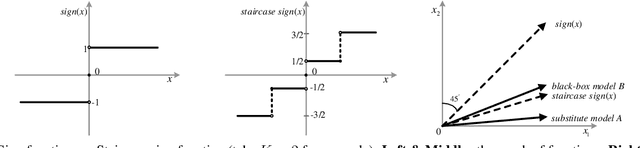
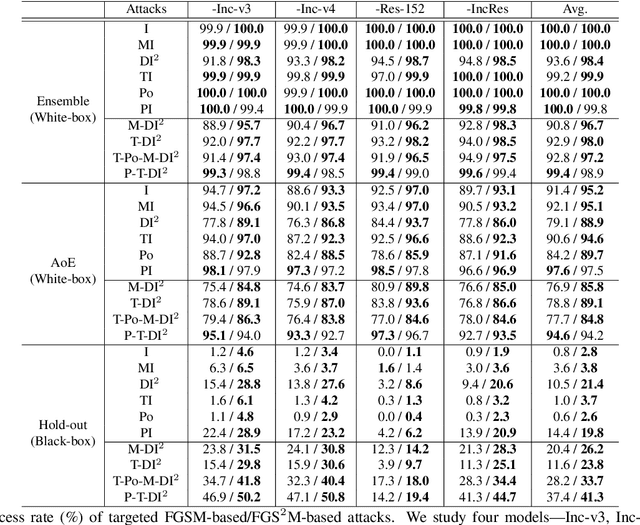
Crafting adversarial examples for the transfer-based attack is challenging and remains a research hot spot. Currently, such attack methods are based on the hypothesis that the substitute model and the victim's model learn similar decision boundaries, and they conventionally apply Sign Method (SM) to manipulate the gradient as the resultant perturbation. Although SM is efficient, it only extracts the sign of gradient units but ignores their value difference, which inevitably leads to a serious deviation. Therefore, we propose a novel Staircase Sign Method (S$^2$M) to alleviate this issue, thus boosting transfer-based attacks. Technically, our method heuristically divides the gradient sign into several segments according to the values of the gradient units, and then assigns each segment with a staircase weight for better crafting adversarial perturbation. As a result, our adversarial examples perform better in both white-box and black-box manner without being more visible. Since S$^2$M just manipulates the resultant gradient, our method can be generally integrated into any transfer-based attacks, and the computational overhead is negligible. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our proposed methods, which significantly improve the transferability (i.e., on average, \textbf{5.1\%} for normally trained models and \textbf{11.2\%} for adversarially trained defenses). Our code is available at: \url{https://github.com/qilong-zhang/Staircase-sign-method}.
Beyond Product Quantization: Deep Progressive Quantization for Image Retrieval
Jul 15, 2019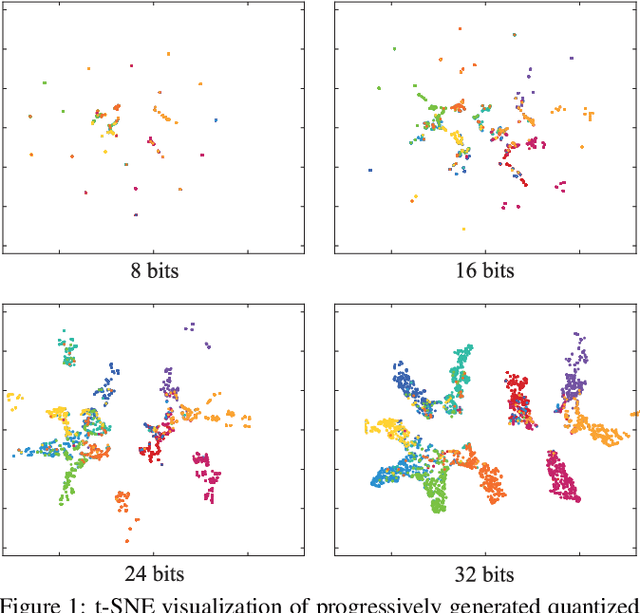
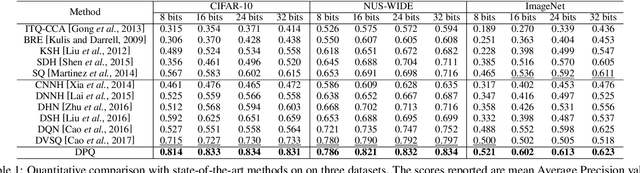
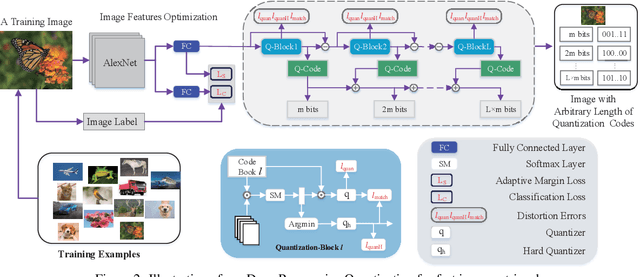

Product Quantization (PQ) has long been a mainstream for generating an exponentially large codebook at very low memory/time cost. Despite its success, PQ is still tricky for the decomposition of high-dimensional vector space, and the retraining of model is usually unavoidable when the code length changes. In this work, we propose a deep progressive quantization (DPQ) model, as an alternative to PQ, for large scale image retrieval. DPQ learns the quantization codes sequentially and approximates the original feature space progressively. Therefore, we can train the quantization codes with different code lengths simultaneously. Specifically, we first utilize the label information for guiding the learning of visual features, and then apply several quantization blocks to progressively approach the visual features. Each quantization block is designed to be a layer of a convolutional neural network, and the whole framework can be trained in an end-to-end manner. Experimental results on the benchmark datasets show that our model significantly outperforms the state-of-the-art for image retrieval. Our model is trained once for different code lengths and therefore requires less computation time. Additional ablation study demonstrates the effect of each component of our proposed model. Our code is released at https://github.com/cfm-uestc/DPQ.
Deep Recurrent Quantization for Generating Sequential Binary Codes
Jul 15, 2019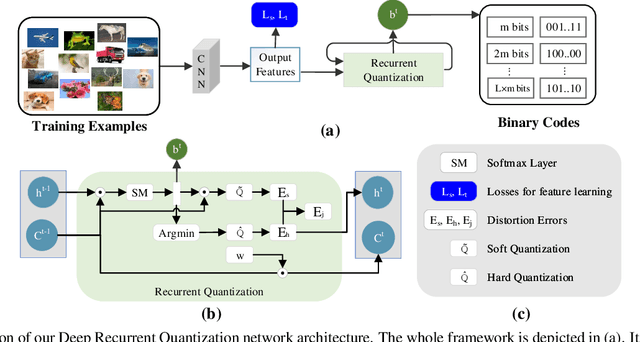
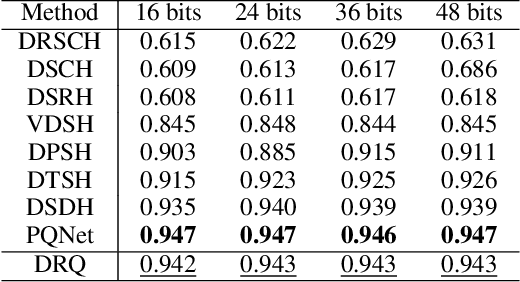
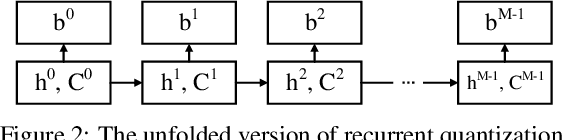
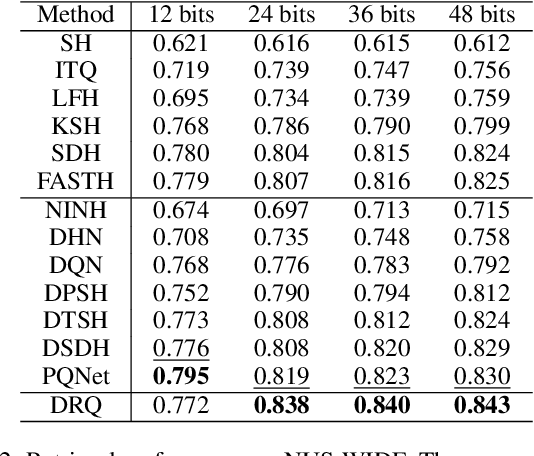
Quantization has been an effective technology in ANN (approximate nearest neighbour) search due to its high accuracy and fast search speed. To meet the requirement of different applications, there is always a trade-off between retrieval accuracy and speed, reflected by variable code lengths. However, to encode the dataset into different code lengths, existing methods need to train several models, where each model can only produce a specific code length. This incurs a considerable training time cost, and largely reduces the flexibility of quantization methods to be deployed in real applications. To address this issue, we propose a Deep Recurrent Quantization (DRQ) architecture which can generate sequential binary codes. To the end, when the model is trained, a sequence of binary codes can be generated and the code length can be easily controlled by adjusting the number of recurrent iterations. A shared codebook and a scalar factor is designed to be the learnable weights in the deep recurrent quantization block, and the whole framework can be trained in an end-to-end manner. As far as we know, this is the first quantization method that can be trained once and generate sequential binary codes. Experimental results on the benchmark datasets show that our model achieves comparable or even better performance compared with the state-of-the-art for image retrieval. But it requires significantly less number of parameters and training times. Our code is published online: https://github.com/cfm-uestc/DRQ.