 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoMotion: Unified Human Video and Motion Generation via Dual-Modality Diffusion Transformer
Dec 21, 2025Video generation models have advanced significantly, yet they still struggle to synthesize complex human movements due to the high degrees of freedom in human articulation. This limitation stems from the intrinsic constraints of pixel-only training objectives, which inherently bias models toward appearance fidelity at the expense of learning underlying kinematic principles. To address this, we introduce EchoMotion, a framework designed to model the joint distribution of appearance and human motion, thereby improving the quality of complex human action video generation. EchoMotion extends the DiT (Diffusion Transformer) framework with a dual-branch architecture that jointly processes tokens concatenated from different modalities. Furthermore, we propose MVS-RoPE (Motion-Video Syncronized RoPE), which offers unified 3D positional encoding for both video and motion tokens. By providing a synchronized coordinate system for the dual-modal latent sequence, MVS-RoPE establishes an inductive bias that fosters temporal alignment between the two modalities. We also propose a Motion-Video Two-Stage Training Strategy. This strategy enables the model to perform both the joint generation of complex human action videos and their corresponding motion sequences, as well as versatile cross-modal conditional generation tasks. To facilitate the training of a model with these capabilities, we construct HuMoVe, a large-scale dataset of approximately 80,000 high-quality, human-centric video-motion pairs. Our findings reveal that explicitly representing human motion is complementary to appearance, significantly boosting the coherence and plausibility of human-centric video generation.
PerlDiff: Controllable Street View Synthesis Using Perspective-Layout Diffusion Models
Jul 08, 2024



Controllable generation is considered a potentially vital approach to address the challenge of annotating 3D data, and the precision of such controllable generation becomes particularly imperative in the context of data production for autonomous driving. Existing methods focus on the integration of diverse generative information into controlling inputs, utilizing frameworks such as GLIGEN or ControlNet, to produce commendable outcomes in controllable generation. However, such approaches intrinsically restrict generation performance to the learning capacities of predefined network architectures. In this paper, we explore the integration of controlling information and introduce PerlDiff (Perspective-Layout Diffusion Models), a method for effective street view image generation that fully leverages perspective 3D geometric information. Our PerlDiff employs 3D geometric priors to guide the generation of street view images with precise object-level control within the network learning process, resulting in a more robust and controllable output. Moreover, it demonstrates superior controllability compared to alternative layout control methods. Empirical results justify that our PerlDiff markedly enhances the precision of generation on the NuScenes and KITTI datasets. Our codes and models are publicly available at https://github.com/LabShuHangGU/PerlDiff.
CT3D++: Improving 3D Object Detection with Keypoint-induced Channel-wise Transformer
Jun 12, 2024



The field of 3D object detection from point clouds is rapidly advancing in computer vision, aiming to accurately and efficiently detect and localize objects in three-dimensional space. Current 3D detectors commonly fall short in terms of flexibility and scalability, with ample room for advancements in performance. In this paper, our objective is to address these limitations by introducing two frameworks for 3D object detection with minimal hand-crafted design. Firstly, we propose CT3D, which sequentially performs raw-point-based embedding, a standard Transformer encoder, and a channel-wise decoder for point features within each proposal. Secondly, we present an enhanced network called CT3D++, which incorporates geometric and semantic fusion-based embedding to extract more valuable and comprehensive proposal-aware information. Additionally, CT3D ++ utilizes a point-to-key bidirectional encoder for more efficient feature encoding with reduced computational cost. By replacing the corresponding components of CT3D with these novel modules, CT3D++ achieves state-of-the-art performance on both the KITTI dataset and the large-scale Way\-mo Open Dataset. The source code for our frameworks will be made accessible at https://github.com/hlsheng1/CT3D-plusplus.
RoScenes: A Large-scale Multi-view 3D Dataset for Roadside Perception
May 17, 2024



We introduce RoScenes, the largest multi-view roadside perception dataset, which aims to shed light on the development of vision-centric Bird's Eye View (BEV) approaches for more challenging traffic scenes. The highlights of RoScenes include significantly large perception area, full scene coverage and crowded traffic. More specifically, our dataset achieves surprising 21.13M 3D annotations within 64,000 $m^2$. To relieve the expensive costs of roadside 3D labeling, we present a novel BEV-to-3D joint annotation pipeline to efficiently collect such a large volume of data. After that, we organize a comprehensive study for current BEV methods on RoScenes in terms of effectiveness and efficiency. Tested methods suffer from the vast perception area and variation of sensor layout across scenes, resulting in performance levels falling below expectations. To this end, we propose RoBEV that incorporates feature-guided position embedding for effective 2D-3D feature assignment. With its help, our method outperforms state-of-the-art by a large margin without extra computational overhead on validation set. Our dataset and devkit will be made available at https://github.com/xiaosu-zhu/RoScenes.
Rethinking IoU-based Optimization for Single-stage 3D Object Detection
Jul 20, 2022
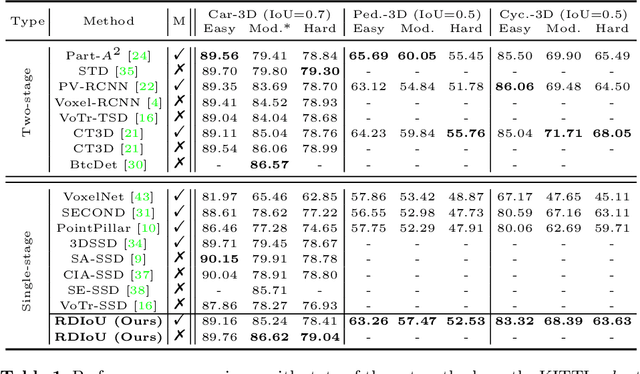


Since Intersection-over-Union (IoU) based optimization maintains the consistency of the final IoU prediction metric and losses, it has been widely used in both regression and classification branches of single-stage 2D object detectors. Recently, several 3D object detection methods adopt IoU-based optimization and directly replace the 2D IoU with 3D IoU. However, such a direct computation in 3D is very costly due to the complex implementation and inefficient backward operations. Moreover, 3D IoU-based optimization is sub-optimal as it is sensitive to rotation and thus can cause training instability and detection performance deterioration. In this paper, we propose a novel Rotation-Decoupled IoU (RDIoU) method that can mitigate the rotation-sensitivity issue, and produce more efficient optimization objectives compared with 3D IoU during the training stage. Specifically, our RDIoU simplifies the complex interactions of regression parameters by decoupling the rotation variable as an independent term, yet preserving the geometry of 3D IoU. By incorporating RDIoU into both the regression and classification branches, the network is encouraged to learn more precise bounding boxes and concurrently overcome the misalignment issue between classification and regression. Extensive experiments on the benchmark KITTI and Waymo Open Dataset validate that our RDIoU method can bring substantial improvement for the single-stage 3D object detection.
Improving 3D Object Detection with Channel-wise Transformer
Aug 23, 2021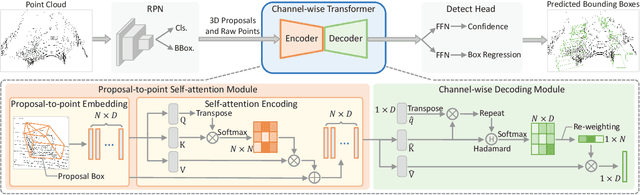

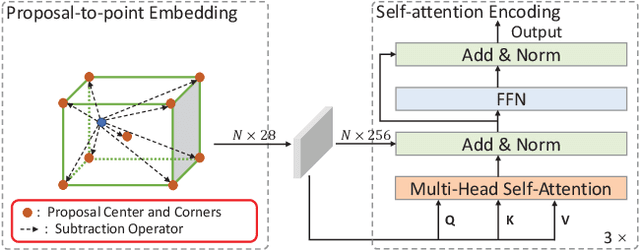
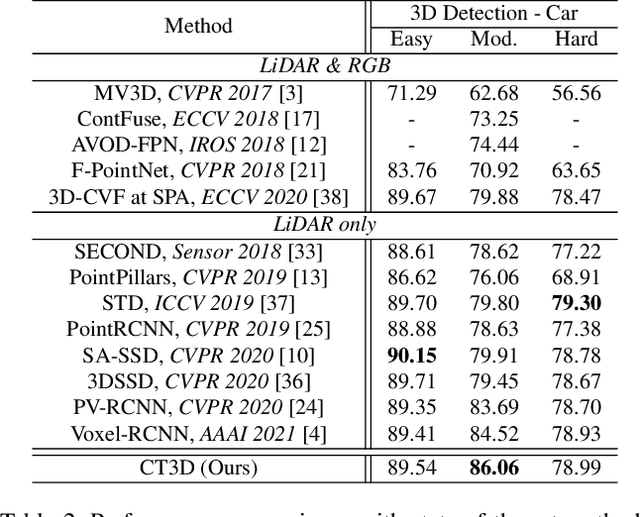
Though 3D object detection from point clouds has achieved rapid progress in recent years, the lack of flexible and high-performance proposal refinement remains a great hurdle for existing state-of-the-art two-stage detectors. Previous works on refining 3D proposals have relied on human-designed components such as keypoints sampling, set abstraction and multi-scale feature fusion to produce powerful 3D object representations. Such methods, however, have limited ability to capture rich contextual dependencies among points. In this paper, we leverage the high-quality region proposal network and a Channel-wise Transformer architecture to constitute our two-stage 3D object detection framework (CT3D) with minimal hand-crafted design. The proposed CT3D simultaneously performs proposal-aware embedding and channel-wise context aggregation for the point features within each proposal. Specifically, CT3D uses proposal's keypoints for spatial contextual modelling and learns attention propagation in the encoding module, mapping the proposal to point embeddings. Next, a new channel-wise decoding module enriches the query-key interaction via channel-wise re-weighting to effectively merge multi-level contexts, which contributes to more accurate object predictions. Extensive experiments demonstrate that our CT3D method has superior performance and excellent scalability. Remarkably, CT3D achieves the AP of 81.77% in the moderate car category on the KITTI test 3D detection benchmark, outperforms state-of-the-art 3D detectors.
Efficient Background Modeling Based on Sparse Representation and Outlier Iterative Removal
Jan 05, 2016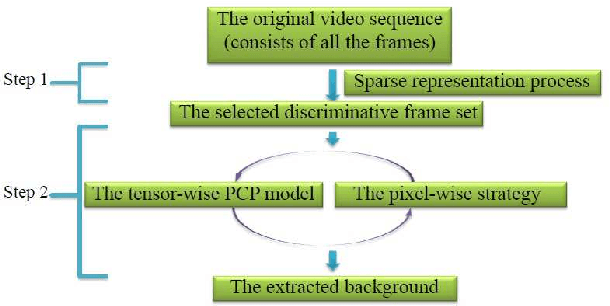


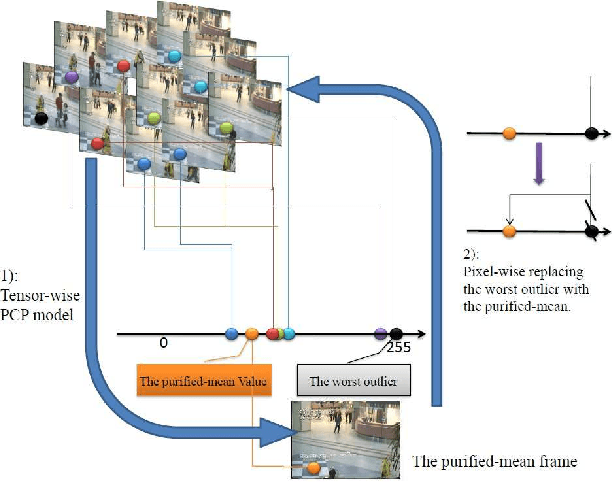
Background modeling is a critical component for various vision-based applications. Most traditional methods tend to be inefficient when solving large-scale problems. In this paper, we introduce sparse representation into the task of large scale stable background modeling, and reduce the video size by exploring its 'discriminative' frames. A cyclic iteration process is then proposed to extract the background from the discriminative frame set. The two parts combine to form our Sparse Outlier Iterative Removal (SOIR) algorithm. The algorithm operates in tensor space to obey the natural data structure of videos. Experimental results show that a few discriminative frames determine the performance of the background extraction. Further, SOIR can achieve high accuracy and high speed simultaneously when dealing with real video sequences. Thus, SOIR has an advantage in solving large-scale tasks.