 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-granularity Interactive Attention Framework for Residual Hierarchical Pronunciation Assessment
Jan 05, 2026Automatic pronunciation assessment plays a crucial role in computer-assisted pronunciation training systems. Due to the ability to perform multiple pronunciation tasks simultaneously, multi-aspect multi-granularity pronunciation assessment methods are gradually receiving more attention and achieving better performance than single-level modeling tasks. However, existing methods only consider unidirectional dependencies between adjacent granularity levels, lacking bidirectional interaction among phoneme, word, and utterance levels and thus insufficiently capturing the acoustic structural correlations. To address this issue, we propose a novel residual hierarchical interactive method, HIA for short, that enables bidirectional modeling across granularities. As the core of HIA, the Interactive Attention Module leverages an attention mechanism to achieve dynamic bidirectional interaction, effectively capturing linguistic features at each granularity while integrating correlations between different granularity levels. We also propose a residual hierarchical structure to alleviate the feature forgetting problem when modeling acoustic hierarchies. In addition, we use 1-D convolutional layers to enhance the extraction of local contextual cues at each granularity. Extensive experiments on the speechocean762 dataset show that our model is comprehensively ahead of the existing state-of-the-art methods.
Learning Real Facial Concepts for Independent Deepfake Detection
May 07, 2025Deepfake detection models often struggle with generalization to unseen datasets, manifesting as misclassifying real instances as fake in target domains. This is primarily due to an overreliance on forgery artifacts and a limited understanding of real faces. To address this challenge, we propose a novel approach RealID to enhance generalization by learning a comprehensive concept of real faces while assessing the probabilities of belonging to the real and fake classes independently. RealID comprises two key modules: the Real Concept Capture Module (RealC2) and the Independent Dual-Decision Classifier (IDC). With the assistance of a MultiReal Memory, RealC2 maintains various prototypes for real faces, allowing the model to capture a comprehensive concept of real class. Meanwhile, IDC redefines the classification strategy by making independent decisions based on the concept of the real class and the presence of forgery artifacts. Through the combined effect of the above modules, the influence of forgery-irrelevant patterns is alleviated, and extensive experiments on five widely used datasets demonstrate that RealID significantly outperforms existing state-of-the-art methods, achieving a 1.74% improvement in average accuracy.
DATA: Multi-Disentanglement based Contrastive Learning for Open-World Semi-Supervised Deepfake Attribution
May 07, 2025Deepfake attribution (DFA) aims to perform multiclassification on different facial manipulation techniques, thereby mitigating the detrimental effects of forgery content on the social order and personal reputations. However, previous methods focus only on method-specific clues, which easily lead to overfitting, while overlooking the crucial role of common forgery features. Additionally, they struggle to distinguish between uncertain novel classes in more practical open-world scenarios. To address these issues, in this paper we propose an innovative multi-DisentAnglement based conTrastive leArning framework, DATA, to enhance the generalization ability on novel classes for the open-world semi-supervised deepfake attribution (OSS-DFA) task. Specifically, since all generation techniques can be abstracted into a similar architecture, DATA defines the concept of 'Orthonormal Deepfake Basis' for the first time and utilizes it to disentangle method-specific features, thereby reducing the overfitting on forgery-irrelevant information. Furthermore, an augmented-memory mechanism is designed to assist in novel class discovery and contrastive learning, which aims to obtain clear class boundaries for the novel classes through instance-level disentanglements. Additionally, to enhance the standardization and discrimination of features, DATA uses bases contrastive loss and center contrastive loss as auxiliaries for the aforementioned modules. Extensive experimental evaluations show that DATA achieves state-of-the-art performance on the OSS-DFA benchmark, e.g., there are notable accuracy improvements in 2.55% / 5.7% under different settings, compared with the existing methods.
Breaking Fine-Grained Classification Barriers with Cost-Free Data in Few-Shot Class-Incremental Learning
Dec 29, 2024



Current fine-grained classification research mainly concentrates on fine-grained feature learning, but in real-world applications, the bigger issue often lies in the data. Fine-grained data annotation is challenging, and the features and semantics are highly diverse and frequently changing, making traditional methods less effective in real-world scenarios. Although some studies have provided potential solutions to this issue, most are limited to making use of limited supervised information. In this paper, we propose a novel learning paradigm to break barriers in fine-grained classification. It enables the model to learn beyond the standard training phase and benefit from cost-free data encountered during system operation. On this basis, an efficient EXPloring and EXPloiting strategy and method (EXP2) is designed. Thereinto, before the final classification results are obtained, representative inference data samples are explored according to class templates and exploited to optimize classifiers. Experimental results demonstrate the general effectiveness of EXP2.
EVC-MF: End-to-end Video Captioning Network with Multi-scale Features
Oct 22, 2024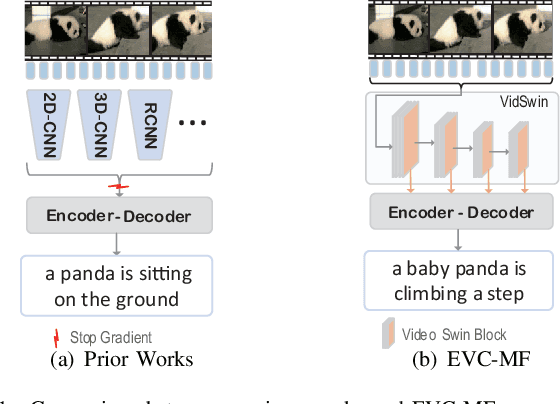



Conventional approaches for video captioning leverage a variety of offline-extracted features to generate captions. Despite the availability of various offline-feature-extractors that offer diverse information from different perspectives, they have several limitations due to fixed parameters. Concretely, these extractors are solely pre-trained on image/video comprehension tasks, making them less adaptable to video caption datasets. Additionally, most of these extractors only capture features prior to the classifier of the pre-training task, ignoring a significant amount of valuable shallow information. Furthermore, employing multiple offline-features may introduce redundant information. To address these issues, we propose an end-to-end encoder-decoder-based network (EVC-MF) for video captioning, which efficiently utilizes multi-scale visual and textual features to generate video descriptions. Specifically, EVC-MF consists of three modules. Firstly, instead of relying on multiple feature extractors, we directly feed video frames into a transformer-based network to obtain multi-scale visual features and update feature extractor parameters. Secondly, we fuse the multi-scale features and input them into a masked encoder to reduce redundancy and encourage learning useful features. Finally, we utilize an enhanced transformer-based decoder, which can efficiently leverage shallow textual information, to generate video descriptions. To evaluate our proposed model, we conduct extensive experiments on benchmark datasets. The results demonstrate that EVC-MF yields competitive performance compared with the state-of-theart methods.
Effective and Robust Adversarial Training against Data and Label Corruptions
May 07, 2024



Corruptions due to data perturbations and label noise are prevalent in the datasets from unreliable sources, which poses significant threats to model training. Despite existing efforts in developing robust models, current learning methods commonly overlook the possible co-existence of both corruptions, limiting the effectiveness and practicability of the model. In this paper, we develop an Effective and Robust Adversarial Training (ERAT) framework to simultaneously handle two types of corruption (i.e., data and label) without prior knowledge of their specifics. We propose a hybrid adversarial training surrounding multiple potential adversarial perturbations, alongside a semi-supervised learning based on class-rebalancing sample selection to enhance the resilience of the model for dual corruption. On the one hand, in the proposed adversarial training, the perturbation generation module learns multiple surrogate malicious data perturbations by taking a DNN model as the victim, while the model is trained to maintain semantic consistency between the original data and the hybrid perturbed data. It is expected to enable the model to cope with unpredictable perturbations in real-world data corruption. On the other hand, a class-rebalancing data selection strategy is designed to fairly differentiate clean labels from noisy labels. Semi-supervised learning is performed accordingly by discarding noisy labels. Extensive experiments demonstrate the superiority of the proposed ERAT framework.
Bias Mitigating Few-Shot Class-Incremental Learning
Feb 01, 2024Few-shot class-incremental learning (FSCIL) aims at recognizing novel classes continually with limited novel class samples. A mainstream baseline for FSCIL is first to train the whole model in the base session, then freeze the feature extractor in the incremental sessions. Despite achieving high overall accuracy, most methods exhibit notably low accuracy for incremental classes. Some recent methods somewhat alleviate the accuracy imbalance between base and incremental classes by fine-tuning the feature extractor in the incremental sessions, but they further cause the accuracy imbalance between past and current incremental classes. In this paper, we study the causes of such classification accuracy imbalance for FSCIL, and abstract them into a unified model bias problem. Based on the analyses, we propose a novel method to mitigate model bias of the FSCIL problem during training and inference processes, which includes mapping ability stimulation, separately dual-feature classification, and self-optimizing classifiers. Extensive experiments on three widely-used FSCIL benchmark datasets show that our method significantly mitigates the model bias problem and achieves state-of-the-art performance.
Generating Human-Centric Visual Cues for Human-Object Interaction Detection via Large Vision-Language Models
Nov 26, 2023Human-object interaction (HOI) detection aims at detecting human-object pairs and predicting their interactions. However, the complexity of human behavior and the diverse contexts in which these interactions occur make it challenging. Intuitively, human-centric visual cues, such as the involved participants, the body language, and the surrounding environment, play crucial roles in shaping these interactions. These cues are particularly vital in interpreting unseen interactions. In this paper, we propose three prompts with VLM to generate human-centric visual cues within an image from multiple perspectives of humans. To capitalize on these rich Human-Centric Visual Cues, we propose a novel approach named HCVC for HOI detection. Particularly, we develop a transformer-based multimodal fusion module with multitower architecture to integrate visual cue features into the instance and interaction decoders. Our extensive experiments and analysis validate the efficacy of leveraging the generated human-centric visual cues for HOI detection. Notably, the experimental results indicate the superiority of the proposed model over the existing state-of-the-art methods on two widely used datasets.
Federated Class-Incremental Learning with Prompting
Oct 13, 2023As Web technology continues to develop, it has become increasingly common to use data stored on different clients. At the same time, federated learning has received widespread attention due to its ability to protect data privacy when let models learn from data which is distributed across various clients. However, most existing works assume that the client's data are fixed. In real-world scenarios, such an assumption is most likely not true as data may be continuously generated and new classes may also appear. To this end, we focus on the practical and challenging federated class-incremental learning (FCIL) problem. For FCIL, the local and global models may suffer from catastrophic forgetting on old classes caused by the arrival of new classes and the data distributions of clients are non-independent and identically distributed (non-iid). In this paper, we propose a novel method called Federated Class-Incremental Learning with PrompTing (FCILPT). Given the privacy and limited memory, FCILPT does not use a rehearsal-based buffer to keep exemplars of old data. We choose to use prompts to ease the catastrophic forgetting of the old classes. Specifically, we encode the task-relevant and task-irrelevant knowledge into prompts, preserving the old and new knowledge of the local clients and solving the problem of catastrophic forgetting. We first sort the task information in the prompt pool in the local clients to align the task information on different clients before global aggregation. It ensures that the same task's knowledge are fully integrated, solving the problem of non-iid caused by the lack of classes among different clients in the same incremental task. Experiments on CIFAR-100, Mini-ImageNet, and Tiny-ImageNet demonstrate that FCILPT achieves significant accuracy improvements over the state-of-the-art methods.
FedVMR: A New Federated Learning method for Video Moment Retrieval
Oct 28, 2022



Despite the great success achieved, existing video moment retrieval (VMR) methods are developed under the assumption that data are centralizedly stored. However, in real-world applications, due to the inherent nature of data generation and privacy concerns, data are often distributed on different silos, bringing huge challenges to effective large-scale training. In this work, we try to overcome above limitation by leveraging the recent success of federated learning. As the first that is explored in VMR field, the new task is defined as video moment retrieval with distributed data. Then, a novel federated learning method named FedVMR is proposed to facilitate large-scale and secure training of VMR models in decentralized environment. Experiments on benchmark datasets demonstrate its effectiveness. This work is the very first attempt to enable safe and efficient VMR training in decentralized scene, which is hoped to pave the way for further study in the related research field.