 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuScene: Training and Benchmarking Code Generation to Simulate Physical Scenarios
Feb 11, 2026Large language models (LLMs) have been extensively studied for tasks like math competitions, complex coding, and scientific reasoning, yet their ability to accurately represent and simulate physical scenarios via code remains underexplored. We propose SimuScene, the first systematic study that trains and evaluates LLMs on simulating physical scenarios across five physics domains and 52 physical concepts. We build an automatic pipeline to collect data, with human verification to ensure quality. The final dataset contains 7,659 physical scenarios with 334 human-verified examples as the test set. We evaluated 10 contemporary LLMs and found that even the strongest model achieves only a 21.5% pass rate, demonstrating the difficulty of the task. Finally, we introduce a reinforcement learning pipeline with visual rewards that uses a vision-language model as a judge to train textual models. Experiments show that training with our data improves physical simulation via code while substantially enhancing general code generation performance.
Accordion-Thinking: Self-Regulated Step Summaries for Efficient and Readable LLM Reasoning
Feb 03, 2026Scaling test-time compute via long Chain-ofThought unlocks remarkable gains in reasoning capabilities, yet it faces practical limits due to the linear growth of KV cache and quadratic attention complexity. In this paper, we introduce Accordion-Thinking, an end-to-end framework where LLMs learn to self-regulate the granularity of the reasoning steps through dynamic summarization. This mechanism enables a Fold inference mode, where the model periodically summarizes its thought process and discards former thoughts to reduce dependency on historical tokens. We apply reinforcement learning to incentivize this capability further, uncovering a critical insight: the accuracy gap between the highly efficient Fold mode and the exhaustive Unfold mode progressively narrows and eventually vanishes over the course of training. This phenomenon demonstrates that the model learns to encode essential reasoning information into compact summaries, achieving effective compression of the reasoning context. Our Accordion-Thinker demonstrates that with learned self-compression, LLMs can tackle complex reasoning tasks with minimal dependency token overhead without compromising solution quality, and it achieves a 3x throughput while maintaining accuracy on a 48GB GPU memory configuration, while the structured step summaries provide a human-readable account of the reasoning process.
Bridging the Knowledge-Action Gap by Evaluating LLMs in Dynamic Dental Clinical Scenarios
Jan 19, 2026The transition of Large Language Models (LLMs) from passive knowledge retrievers to autonomous clinical agents demands a shift in evaluation-from static accuracy to dynamic behavioral reliability. To explore this boundary in dentistry, a domain where high-quality AI advice uniquely empowers patient-participatory decision-making, we present the Standardized Clinical Management & Performance Evaluation (SCMPE) benchmark, which comprehensively assesses performance from knowledge-oriented evaluations (static objective tasks) to workflow-based simulations (multi-turn simulated patient interactions). Our analysis reveals that while models demonstrate high proficiency in static objective tasks, their performance precipitates in dynamic clinical dialogues, identifying that the primary bottleneck lies not in knowledge retention, but in the critical challenges of active information gathering and dynamic state tracking. Mapping "Guideline Adherence" versus "Decision Quality" reveals a prevalent "High Efficacy, Low Safety" risk in general models. Furthermore, we quantify the impact of Retrieval-Augmented Generation (RAG). While RAG mitigates hallucinations in static tasks, its efficacy in dynamic workflows is limited and heterogeneous, sometimes causing degradation. This underscores that external knowledge alone cannot bridge the reasoning gap without domain-adaptive pre-training. This study empirically charts the capability boundaries of dental LLMs, providing a roadmap for bridging the gap between standardized knowledge and safe, autonomous clinical practice.
CARE What Fails: Contrastive Anchored-REflection for Verifiable Multimodal
Dec 22, 2025Group-relative reinforcement learning with verifiable rewards (RLVR) often wastes the most informative data it already has the failures. When all rollouts are wrong, gradients stall; when one happens to be correct, the update usually ignores why the others are close-but-wrong, and credit can be misassigned to spurious chains. We present CARE (Contrastive Anchored REflection), a failure-centric post-training framework for multimodal reasoning that turns errors into supervision. CARE combines: (i) an anchored-contrastive objective that forms a compact subgroup around the best rollout and a set of semantically proximate hard negatives, performs within-subgroup z-score normalization with negative-only scaling, and includes an all-negative rescue to prevent zero-signal batches; and (ii) Reflection-Guided Resampling (RGR), a one-shot structured self-repair that rewrites a representative failure and re-scores it with the same verifier, converting near-misses into usable positives without any test-time reflection. CARE improves accuracy and training smoothness while explicitly increasing the share of learning signal that comes from failures. On Qwen2.5-VL-7B, CARE lifts macro-averaged accuracy by 4.6 points over GRPO across six verifiable visual-reasoning benchmarks; with Qwen3-VL-8B it reaches competitive or state-of-the-art results on MathVista and MMMU-Pro under an identical evaluation protocol.
PhyBlock: A Progressive Benchmark for Physical Understanding and Planning via 3D Block Assembly
Jun 10, 2025While vision-language models (VLMs) have demonstrated promising capabilities in reasoning and planning for embodied agents, their ability to comprehend physical phenomena, particularly within structured 3D environments, remains severely limited. To close this gap, we introduce PhyBlock, a progressive benchmark designed to assess VLMs on physical understanding and planning through robotic 3D block assembly tasks. PhyBlock integrates a novel four-level cognitive hierarchy assembly task alongside targeted Visual Question Answering (VQA) samples, collectively aimed at evaluating progressive spatial reasoning and fundamental physical comprehension, including object properties, spatial relationships, and holistic scene understanding. PhyBlock includes 2600 block tasks (400 assembly tasks, 2200 VQA tasks) and evaluates models across three key dimensions: partial completion, failure diagnosis, and planning robustness. We benchmark 21 state-of-the-art VLMs, highlighting their strengths and limitations in physically grounded, multi-step planning. Our empirical findings indicate that the performance of VLMs exhibits pronounced limitations in high-level planning and reasoning capabilities, leading to a notable decline in performance for the growing complexity of the tasks. Error analysis reveals persistent difficulties in spatial orientation and dependency reasoning. Surprisingly, chain-of-thought prompting offers minimal improvements, suggesting spatial tasks heavily rely on intuitive model comprehension. We position PhyBlock as a unified testbed to advance embodied reasoning, bridging vision-language understanding and real-world physical problem-solving.
EACO: Enhancing Alignment in Multimodal LLMs via Critical Observation
Dec 06, 2024



Multimodal large language models (MLLMs) have achieved remarkable progress on various visual question answering and reasoning tasks leveraging instruction fine-tuning specific datasets. They can also learn from preference data annotated by human to enhance their reasoning ability and mitigate hallucinations. Most of preference data is generated from the model itself. However, existing methods require high-quality critical labels, which are costly and rely on human or proprietary models like GPT-4V. In this work, we propose Enhancing Alignment in MLLMs via Critical Observation (EACO), which aligns MLLMs by self-generated preference data using only 5k images economically. Our approach begins with collecting and refining a Scoring Evaluation Instruction-tuning dataset to train a critical evaluation model, termed the Critic. This Critic observes model responses across multiple dimensions, selecting preferred and non-preferred outputs for refined Direct Preference Optimization (DPO) tuning. To further enhance model performance, we employ an additional supervised fine-tuning stage after preference tuning. EACO reduces the overall hallucinations by 65.6% on HallusionBench and improves the reasoning ability by 21.8% on MME-Cognition. EACO achieves an 8.5% improvement over LLaVA-v1.6-Mistral-7B across multiple benchmarks. Remarkably, EACO also shows the potential critical ability in open-source MLLMs, demonstrating that EACO is a viable path to boost the competence of MLLMs.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
Prototype-Based Layered Federated Cross-Modal Hashing
Oct 27, 2022

Recently, deep cross-modal hashing has gained increasing attention. However, in many practical cases, data are distributed and cannot be collected due to privacy concerns, which greatly reduces the cross-modal hashing performance on each client. And due to the problems of statistical heterogeneity, model heterogeneity, and forcing each client to accept the same parameters, applying federated learning to cross-modal hash learning becomes very tricky. In this paper, we propose a novel method called prototype-based layered federated cross-modal hashing. Specifically, the prototype is introduced to learn the similarity between instances and classes on server, reducing the impact of statistical heterogeneity (non-IID) on different clients. And we monitor the distance between local and global prototypes to further improve the performance. To realize personalized federated learning, a hypernetwork is deployed on server to dynamically update different layers' weights of local model. Experimental results on benchmark datasets show that our method outperforms state-of-the-art methods.
Three-Stream Joint Network for Zero-Shot Sketch-Based Image Retrieval
Apr 12, 2022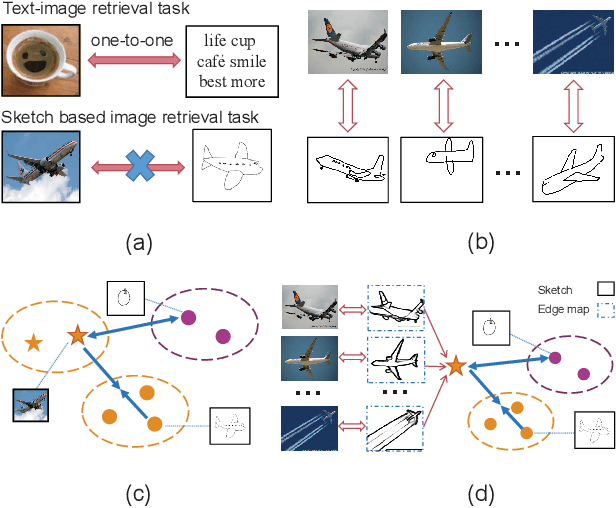
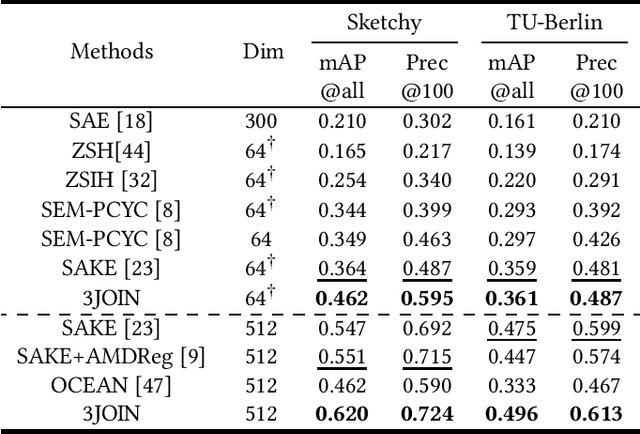
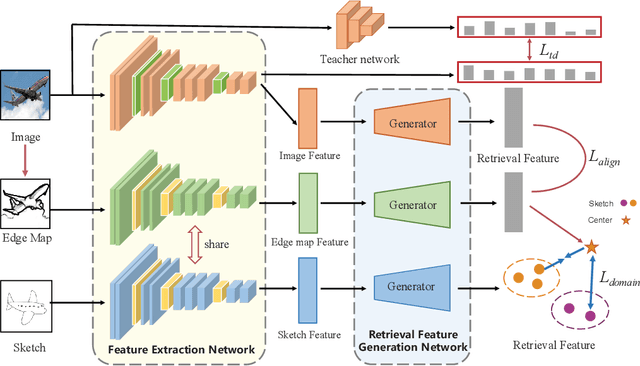
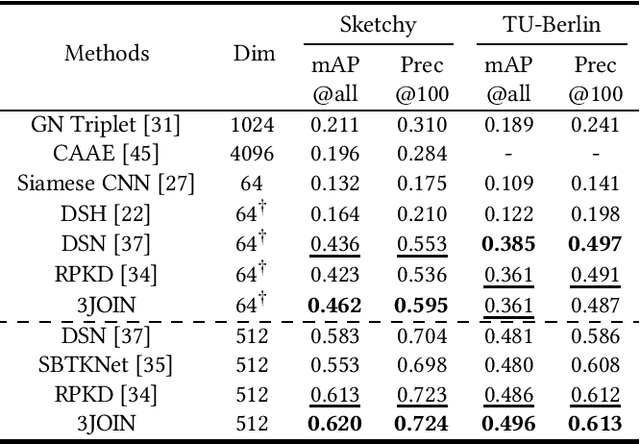
The Zero-Shot Sketch-based Image Retrieval (ZS-SBIR) is a challenging task because of the large domain gap between sketches and natural images as well as the semantic inconsistency between seen and unseen categories. Previous literature bridges seen and unseen categories by semantic embedding, which requires prior knowledge of the exact class names and additional extraction efforts. And most works reduce domain gap by mapping sketches and natural images into a common high-level space using constructed sketch-image pairs, which ignore the unpaired information between images and sketches. To address these issues, in this paper, we propose a novel Three-Stream Joint Training Network (3JOIN) for the ZS-SBIR task. To narrow the domain differences between sketches and images, we extract edge maps for natural images and treat them as a bridge between images and sketches, which have similar content to images and similar style to sketches. For exploiting a sufficient combination of sketches, natural images, and edge maps, a novel three-stream joint training network is proposed. In addition, we use a teacher network to extract the implicit semantics of the samples without the aid of other semantics and transfer the learned knowledge to unseen classes. Extensive experiments conducted on two real-world datasets demonstrate the superiority of our proposed method.
ViT-FOD: A Vision Transformer based Fine-grained Object Discriminator
Mar 24, 2022


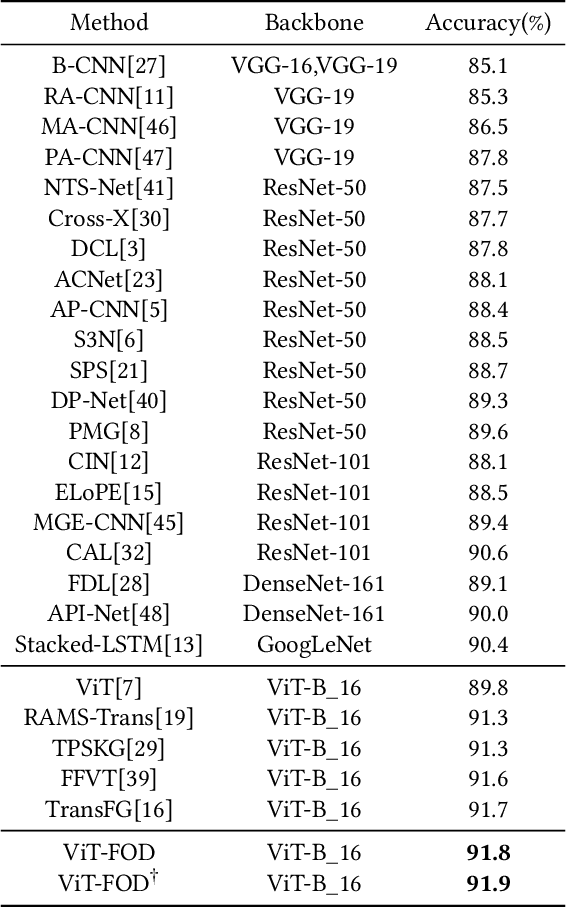
Recently, several Vision Transformer (ViT) based methods have been proposed for Fine-Grained Visual Classification (FGVC).These methods significantly surpass existing CNN-based ones, demonstrating the effectiveness of ViT in FGVC tasks.However, there are some limitations when applying ViT directly to FGVC.First, ViT needs to split images into patches and calculate the attention of every pair, which may result in heavy redundant calculation and unsatisfying performance when handling fine-grained images with complex background and small objects.Second, a standard ViT only utilizes the class token in the final layer for classification, which is not enough to extract comprehensive fine-grained information. To address these issues, we propose a novel ViT based fine-grained object discriminator for FGVC tasks, ViT-FOD for short. Specifically, besides a ViT backbone, it further introduces three novel components, i.e, Attention Patch Combination (APC), Critical Regions Filter (CRF), and Complementary Tokens Integration (CTI). Thereinto, APC pieces informative patches from two images to generate a new image so that the redundant calculation can be reduced. CRF emphasizes tokens corresponding to discriminative regions to generate a new class token for subtle feature learning. To extract comprehensive information, CTI integrates complementary information captured by class tokens in different ViT layers. We conduct comprehensive experiments on widely used datasets and the results demonstrate that ViT-FOD is able to achieve state-of-the-art performance.