 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVerifier-M1: Multimodal Meta-Verifier with Explicit Structured Recalibration
May 27, 2026Visual outcomes are increasingly central to multimodal large language models, making reliable and fine-grained verification essential for scaling generalist foundation models. In this work, we investigate multimodal meta-verification, which leverages verifier-generated rationales rather than decision-only signals, and explore how to effectively incorporate meta-verification feedback into multimodal verifier training. We identify two key findings. First, symbolic verifier outputs (e.g., bounding boxes) outperform textual explanations as meta-verification rationales, enabling efficient rule-based reinforcement learning rewards while avoiding reliance on model-based rewards from auxiliary judge models. Second, decoupling reinforcement learning objectives for binary judgment and meta-verification substantially outperforms joint reward optimization, due to intrinsic differences in output structure and learning dynamics. Based on these insights, we train OmniVerifier-M1, a generalist visual verifier leveraging symbolic meta-verification and decoupled reinforcement learning. OmniVerifier-M1 provides robust verification and fine-grained error localization, and further enables M1-TTS, a verifier-driven agentic generation system achieving dynamic region-level self-correction. This approach paves the way for more reliable, interpretable, and fine-grained multimodal verification, supporting safer and more controllable foundation model deployment.
AutoSurrogate: An LLM-Driven Multi-Agent Framework for Autonomous Construction of Deep Learning Surrogate Models in Subsurface Flow
Apr 13, 2026High-fidelity numerical simulation of subsurface flow is computationally intensive, especially for many-query tasks such as uncertainty quantification and data assimilation. Deep learning (DL) surrogates can significantly accelerate forward simulations, yet constructing them requires substantial machine learning (ML) expertise - from architecture design to hyperparameter tuning - that most domain scientists do not possess. Furthermore, the process is predominantly manual and relies heavily on heuristic choices. This expertise gap remains a key barrier to the broader adoption of DL surrogate techniques. For this reason, we present AutoSurrogate, a large-language-model-driven multi-agent framework that enables practitioners without ML expertise to build high-quality surrogates for subsurface flow problems through natural-language instructions. Given simulation data and optional preferences, four specialized agents collaboratively execute data profiling, architecture selection from a model zoo, Bayesian hyperparameter optimization, model training, and quality assessment against user-specified thresholds. The system also handles common failure modes autonomously, including restarting training with adjusted configurations when numerical instabilities occur and switching to alternative architectures when predictive accuracy falls short of targets. In our setting, a single natural-language sentence can be sufficient to produce a deployment-ready surrogate model, with minimum human intervention required at any intermediate stage. We demonstrate the utility of AutoSurrogate on a 3D geological carbon storage modeling task, mapping permeability fields to pressure and CO$_2$ saturation fields over 31 timesteps. Without any manual tuning, AutoSurrogate is able to outperform expert-designed baselines and domain-agnostic AutoML methods, demonstrating strong potential for practical deployment.
Do Images Speak Louder than Words? Investigating the Effect of Textual Misinformation in VLMs
Jan 27, 2026Vision-Language Models (VLMs) have shown strong multimodal reasoning capabilities on Visual-Question-Answering (VQA) benchmarks. However, their robustness against textual misinformation remains under-explored. While existing research has studied the effect of misinformation in text-only domains, it is not clear how VLMs arbitrate between contradictory information from different modalities. To bridge the gap, we first propose the CONTEXT-VQA (i.e., Conflicting Text) dataset, consisting of image-question pairs together with systematically generated persuasive prompts that deliberately conflict with visual evidence. Then, a thorough evaluation framework is designed and executed to benchmark the susceptibility of various models to these conflicting multimodal inputs. Comprehensive experiments over 11 state-of-the-art VLMs reveal that these models are indeed vulnerable to misleading textual prompts, often overriding clear visual evidence in favor of the conflicting text, and show an average performance drop of over 48.2% after only one round of persuasive conversation. Our findings highlight a critical limitation in current VLMs and underscore the need for improved robustness against textual manipulation.
Veri-Sure: A Contract-Aware Multi-Agent Framework with Temporal Tracing and Formal Verification for Correct RTL Code Generation
Jan 27, 2026In the rapidly evolving field of Electronic Design Automation (EDA), the deployment of Large Language Models (LLMs) for Register-Transfer Level (RTL) design has emerged as a promising direction. However, silicon-grade correctness remains bottlenecked by: (i) limited test coverage and reliability of simulation-centric evaluation, (ii) regressions and repair hallucinations introduced by iterative debugging, and (iii) semantic drift as intent is reinterpreted across agent handoffs. In this work, we propose Veri-Sure, a multi-agent framework that establishes a design contract to align agents' intent and uses a patching mechanism guided by static dependency slicing to perform precise, localized repairs. By integrating a multi-branch verification pipeline that combines trace-driven temporal analysis with formal verification consisting of assertion-based checking and boolean equivalence proofs, Veri-Sure enables functional correctness beyond pure simulations. We also introduce VerilogEval-v2-EXT, extending the original benchmark with 53 more industrial-grade design tasks and stratified difficulty levels, and show that Veri-Sure achieves state-of-the-art verified-correct RTL code generation performance, surpassing standalone LLMs and prior agentic systems.
Sliding Window Attention Adaptation
Dec 16, 2025The self-attention mechanism in Transformer-based Large Language Models (LLMs) scales quadratically with input length, making long-context inference expensive. Sliding window attention (SWA) reduces this cost to linear complexity, but naively enabling complete SWA at inference-time for models pretrained with full attention (FA) causes severe long-context performance degradation due to training-inference mismatch. This makes us wonder: Can FA-pretrained LLMs be well adapted to SWA without pretraining? We investigate this by proposing Sliding Window Attention Adaptation (SWAA), a set of practical recipes that combine five methods for better adaptation: (1) applying SWA only during prefilling; (2) preserving "sink" tokens; (3) interleaving FA/SWA layers; (4) chain-of-thought (CoT); and (5) fine-tuning. Our experiments show that SWA adaptation is feasible while non-trivial: no single method suffices, yet specific synergistic combinations effectively recover the original long-context performance. We further analyze the performance-efficiency trade-offs of different SWAA configurations and provide recommended recipes for diverse scenarios, which can greatly and fundamentally accelerate LLM long-context inference speed by up to 100%. Our code is available at https://github.com/yuyijiong/sliding-window-attention-adaptation
Cross Modal Fine-Grained Alignment via Granularity-Aware and Region-Uncertain Modeling
Nov 19, 2025Fine-grained image-text alignment is a pivotal challenge in multimodal learning, underpinning key applications such as visual question answering, image captioning, and vision-language navigation. Unlike global alignment, fine-grained alignment requires precise correspondence between localized visual regions and textual tokens, often hindered by noisy attention mechanisms and oversimplified modeling of cross-modal relationships. In this work, we identify two fundamental limitations of existing approaches: the lack of robust intra-modal mechanisms to assess the significance of visual and textual tokens, leading to poor generalization in complex scenes; and the absence of fine-grained uncertainty modeling, which fails to capture the one-to-many and many-to-one nature of region-word correspondences. To address these issues, we propose a unified approach that incorporates significance-aware and granularity-aware modeling and region-level uncertainty modeling. Our method leverages modality-specific biases to identify salient features without relying on brittle cross-modal attention, and represents region features as a mixture of Gaussian distributions to capture fine-grained uncertainty. Extensive experiments on Flickr30K and MS-COCO demonstrate that our approach achieves state-of-the-art performance across various backbone architectures, significantly enhancing the robustness and interpretability of fine-grained image-text alignment.
Exposing Privacy Risks in Graph Retrieval-Augmented Generation
Aug 24, 2025Retrieval-Augmented Generation (RAG) is a powerful technique for enhancing Large Language Models (LLMs) with external, up-to-date knowledge. Graph RAG has emerged as an advanced paradigm that leverages graph-based knowledge structures to provide more coherent and contextually rich answers. However, the move from plain document retrieval to structured graph traversal introduces new, under-explored privacy risks. This paper investigates the data extraction vulnerabilities of the Graph RAG systems. We design and execute tailored data extraction attacks to probe their susceptibility to leaking both raw text and structured data, such as entities and their relationships. Our findings reveal a critical trade-off: while Graph RAG systems may reduce raw text leakage, they are significantly more vulnerable to the extraction of structured entity and relationship information. We also explore potential defense mechanisms to mitigate these novel attack surfaces. This work provides a foundational analysis of the unique privacy challenges in Graph RAG and offers insights for building more secure systems.
Divide, Optimize, Merge: Fine-Grained LLM Agent Optimization at Scale
May 06, 2025LLM-based optimization has shown remarkable potential in enhancing agentic systems. However, the conventional approach of prompting LLM optimizer with the whole training trajectories on training dataset in a single pass becomes untenable as datasets grow, leading to context window overflow and degraded pattern recognition. To address these challenges, we propose Fine-Grained Optimization (FGO), a scalable framework that divides large optimization tasks into manageable subsets, performs targeted optimizations, and systematically combines optimized components through progressive merging. Evaluation across ALFWorld, LogisticsQA, and GAIA benchmarks demonstrate that FGO outperforms existing approaches by 1.6-8.6% while reducing average prompt token consumption by 56.3%. Our framework provides a practical solution for scaling up LLM-based optimization of increasingly sophisticated agent systems. Further analysis demonstrates that FGO achieves the most consistent performance gain in all training dataset sizes, showcasing its scalability and efficiency.
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
Apr 30, 2025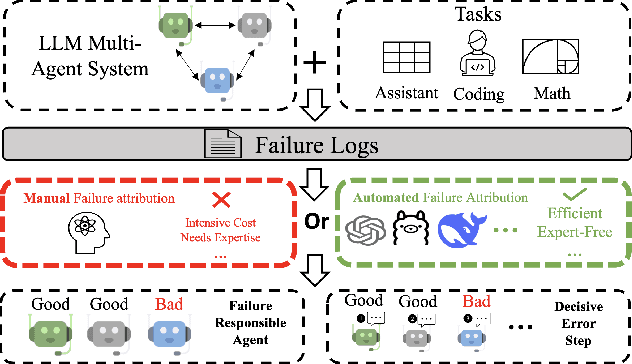
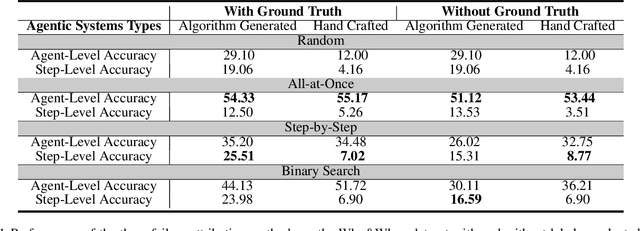
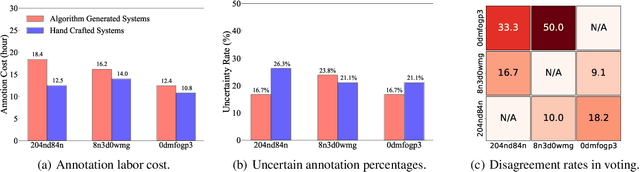

Failure attribution in LLM multi-agent systems-identifying the agent and step responsible for task failures-provides crucial clues for systems debugging but remains underexplored and labor-intensive. In this paper, we propose and formulate a new research area: automated failure attribution for LLM multi-agent systems. To support this initiative, we introduce the Who&When dataset, comprising extensive failure logs from 127 LLM multi-agent systems with fine-grained annotations linking failures to specific agents and decisive error steps. Using the Who&When, we develop and evaluate three automated failure attribution methods, summarizing their corresponding pros and cons. The best method achieves 53.5% accuracy in identifying failure-responsible agents but only 14.2% in pinpointing failure steps, with some methods performing below random. Even SOTA reasoning models, such as OpenAI o1 and DeepSeek R1, fail to achieve practical usability. These results highlight the task's complexity and the need for further research in this area. Code and dataset are available at https://github.com/mingyin1/Agents_Failure_Attribution
Identifying Trustworthiness Challenges in Deep Learning Models for Continental-Scale Water Quality Prediction
Mar 13, 2025



Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning models, particularly Long Short-Term Memory (LSTM) networks, offer transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges including fairness, uncertainty, interpretability, robustness, generalizability, and reproducibility. In this work, we present the first comprehensive evaluation of trustworthiness in a continental-scale multi-task LSTM model predicting 20 water quality variables (encompassing physical/chemical processes, geochemical weathering, and nutrient cycling) across 482 U.S. basins. Our investigation uncovers systematic patterns of model performance disparities linked to basin characteristics, the inherent complexity of biogeochemical processes, and variable predictability, emphasizing critical performance fairness concerns. We further propose methodological frameworks for quantitatively evaluating critical aspects of trustworthiness, including uncertainty, interpretability, and robustness, identifying key limitations that could challenge reliable real-world deployment. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management.