 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Trustworthiness Challenges in Deep Learning Models for Continental-Scale Water Quality Prediction
Mar 13, 2025



Water quality is foundational to environmental sustainability, ecosystem resilience, and public health. Deep learning models, particularly Long Short-Term Memory (LSTM) networks, offer transformative potential for large-scale water quality prediction and scientific insights generation. However, their widespread adoption in high-stakes decision-making, such as pollution mitigation and equitable resource allocation, is prevented by unresolved trustworthiness challenges including fairness, uncertainty, interpretability, robustness, generalizability, and reproducibility. In this work, we present the first comprehensive evaluation of trustworthiness in a continental-scale multi-task LSTM model predicting 20 water quality variables (encompassing physical/chemical processes, geochemical weathering, and nutrient cycling) across 482 U.S. basins. Our investigation uncovers systematic patterns of model performance disparities linked to basin characteristics, the inherent complexity of biogeochemical processes, and variable predictability, emphasizing critical performance fairness concerns. We further propose methodological frameworks for quantitatively evaluating critical aspects of trustworthiness, including uncertainty, interpretability, and robustness, identifying key limitations that could challenge reliable real-world deployment. This work serves as a timely call to action for advancing trustworthy data-driven methods for water resources management and provides a pathway to offering critical insights for researchers, decision-makers, and practitioners seeking to leverage artificial intelligence (AI) responsibly in environmental management.
Differentiable modeling to unify machine learning and physical models and advance Geosciences
Jan 10, 2023



Process-Based Modeling (PBM) and Machine Learning (ML) are often perceived as distinct paradigms in the geosciences. Here we present differentiable geoscientific modeling as a powerful pathway toward dissolving the perceived barrier between them and ushering in a paradigm shift. For decades, PBM offered benefits in interpretability and physical consistency but struggled to efficiently leverage large datasets. ML methods, especially deep networks, presented strong predictive skills yet lacked the ability to answer specific scientific questions. While various methods have been proposed for ML-physics integration, an important underlying theme -- differentiable modeling -- is not sufficiently recognized. Here we outline the concepts, applicability, and significance of differentiable geoscientific modeling (DG). "Differentiable" refers to accurately and efficiently calculating gradients with respect to model variables, critically enabling the learning of high-dimensional unknown relationships. DG refers to a range of methods connecting varying amounts of prior knowledge to neural networks and training them together, capturing a different scope than physics-guided machine learning and emphasizing first principles. Preliminary evidence suggests DG offers better interpretability and causality than ML, improved generalizability and extrapolation capability, and strong potential for knowledge discovery, while approaching the performance of purely data-driven ML. DG models require less training data while scaling favorably in performance and efficiency with increasing amounts of data. With DG, geoscientists may be better able to frame and investigate questions, test hypotheses, and discover unrecognized linkages.
The data synergy effects of time-series deep learning models in hydrology
Jan 06, 2021
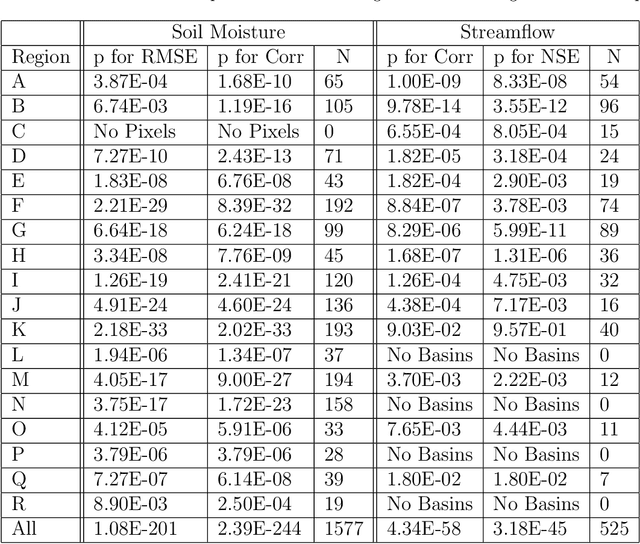
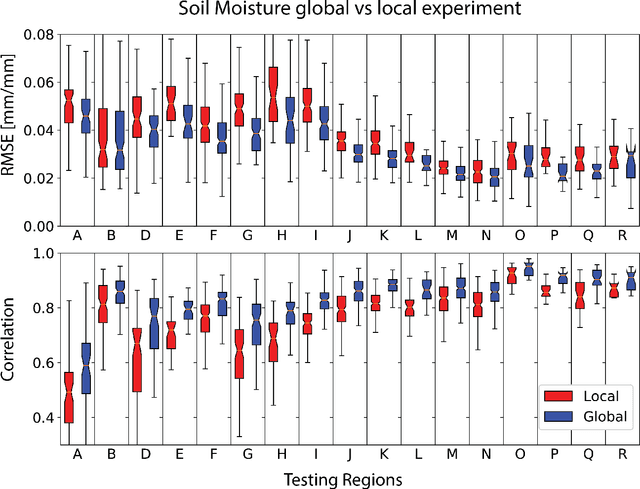
When fitting statistical models to variables in geoscientific disciplines such as hydrology, it is a customary practice to regionalize - to divide a large spatial domain into multiple regions and study each region separately - instead of fitting a single model on the entire data (also known as unification). Traditional wisdom in these fields suggests that models built for each region separately will have higher performance because of homogeneity within each region. However, by partitioning the training data, each model has access to fewer data points and cannot learn from commonalities between regions. Here, through two hydrologic examples (soil moisture and streamflow), we argue that unification can often significantly outperform regionalization in the era of big data and deep learning (DL). Common DL architectures, even without bespoke customization, can automatically build models that benefit from regional commonality while accurately learning region-specific differences. We highlight an effect we call data synergy, where the results of the DL models improved when data were pooled together from characteristically different regions. In fact, the performance of the DL models benefited from more diverse rather than more homogeneous training data. We hypothesize that DL models automatically adjust their internal representations to identify commonalities while also providing sufficient discriminatory information to the model. The results here advocate for pooling together larger datasets, and suggest the academic community should place greater emphasis on data sharing and compilation.
Enhancing streamflow forecast and extracting insights using long-short term memory networks with data integration at continental scales
Jan 02, 2020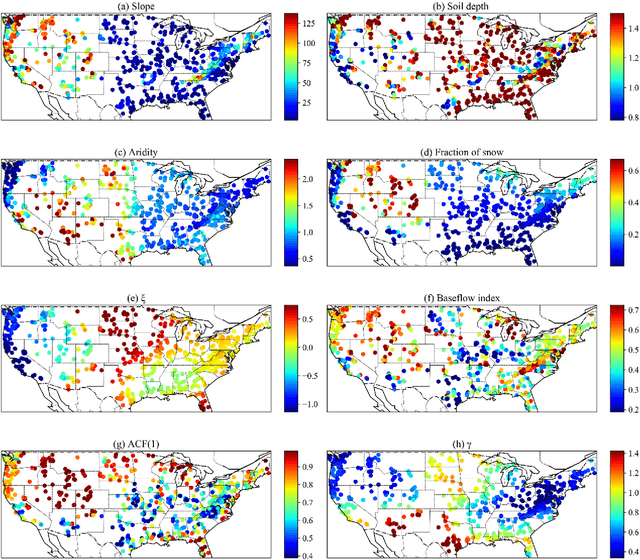
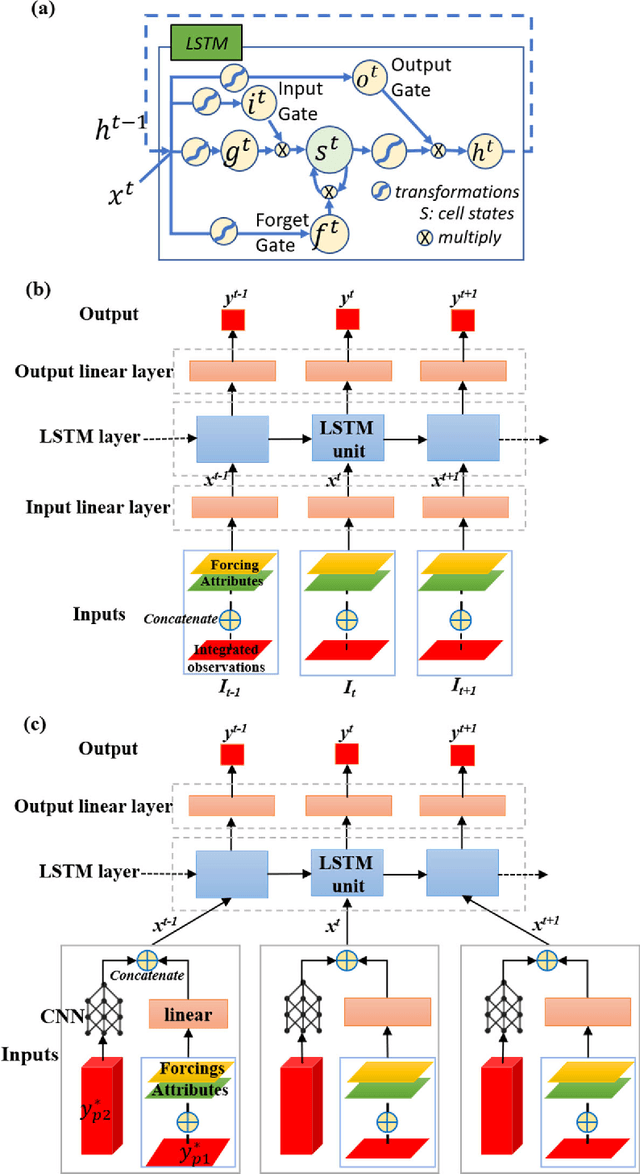
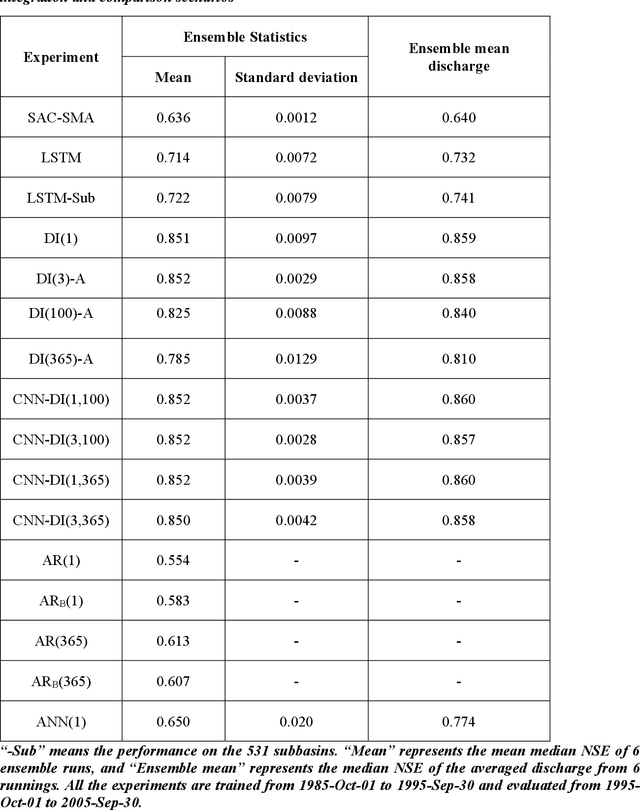
Recent observations with varied schedules and types (moving average, snapshot, or regularly spaced) can help to improve streamflow forecast but it is difficult to effectively integrate them. Based on a long short-term memory (LSTM) streamflow model, we tested different formulations in a flexible method we call data integration (DI) to integrate recently discharge measurements to improve forecast. DI accepts lagged inputs either directly or through a convolutional neural network (CNN) unit. DI can ubiquitously elevate streamflow forecast performance to unseen levels, reaching a continental-scale median Nash-Sutcliffe coefficient of 0.86. Integrating moving-average discharge, discharge from a few days ago, or even average discharge of the last calendar month could all improve daily forecast. It turned out, directly using lagged observations as inputs was comparable in performance to using the CNN unit. Importantly, we obtained valuable insights regarding hydrologic processes impacting LSTM and DI performance. Before applying DI, the original LSTM worked well in mountainous regions and snow-dominated regions, but less so in regions with low discharge volumes (due to either low precipitation or high precipitation-energy synchronicity) and large inter-annual storage variability. DI was most beneficial in regions with high flow autocorrelation: it greatly reduced baseflow bias in groundwater-dominated western basins; it also improved the peaks for basins with dynamical surface water storage, e.g., the Prairie Potholes or Great Lakes regions. However, even DI cannot help high-aridity basins with one-day flash peaks. There is much promise with a deep-learning-based forecast paradigm due to its performance, automation, efficiency, and flexibility.
Evaluating aleatoric and epistemic uncertainties of time series deep learning models for soil moisture predictions
Jun 10, 2019
Soil moisture is an important variable that determines floods, vegetation health, agriculture productivity, and land surface feedbacks to the atmosphere, etc. Accurately modeling soil moisture has important implications in both weather and climate models. The recently available satellite-based observations give us a unique opportunity to build data-driven models to predict soil moisture instead of using land surface models, but previously there was no uncertainty estimate. We tested Monte Carlo dropout (MCD) with an aleatoric term for our long short-term memory models for this problem, and asked if the uncertainty terms behave as they were argued to. We show that the method successfully captures the predictive error after tuning a hyperparameter on a representative training dataset. We show the MCD uncertainty estimate, as previously argued, does detect dissimilarity.
Prolongation of SMAP to Spatio-temporally Seamless Coverage of Continental US Using a Deep Learning Neural Network
Sep 11, 2017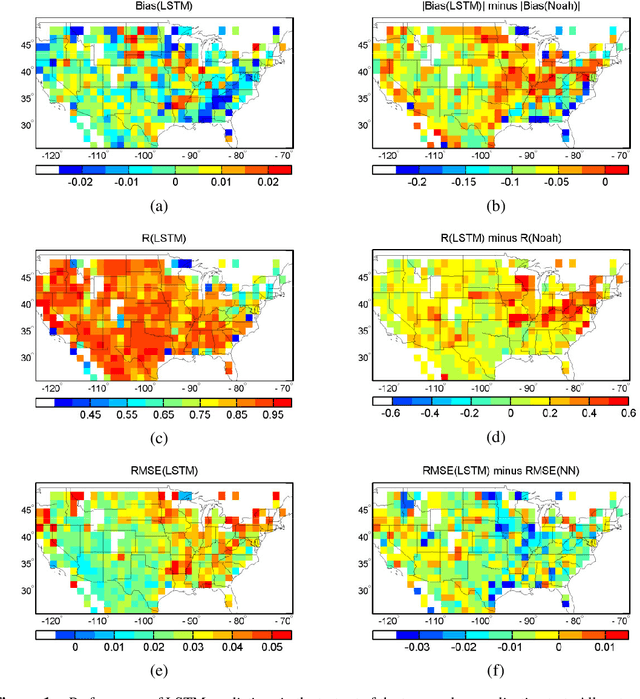
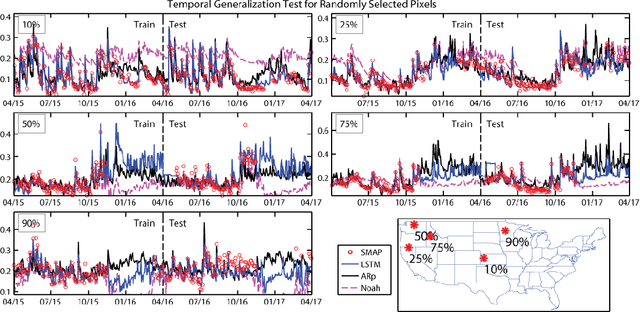
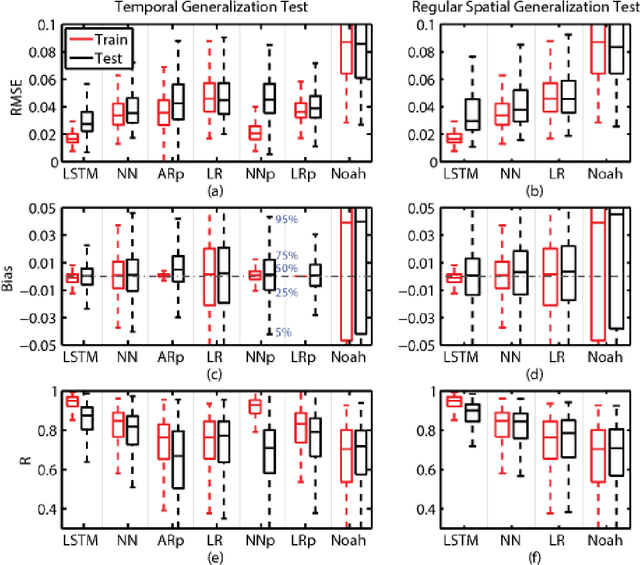
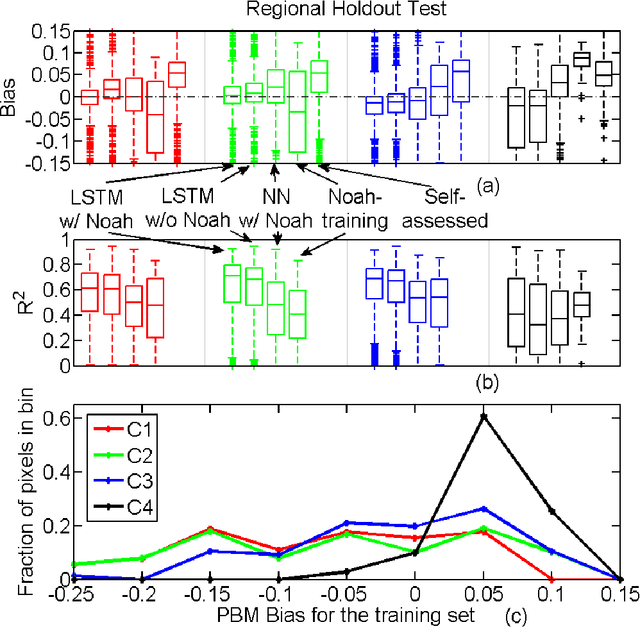
The Soil Moisture Active Passive (SMAP) mission has delivered valuable sensing of surface soil moisture since 2015. However, it has a short time span and irregular revisit schedule. Utilizing a state-of-the-art time-series deep learning neural network, Long Short-Term Memory (LSTM), we created a system that predicts SMAP level-3 soil moisture data with atmospheric forcing, model-simulated moisture, and static physiographic attributes as inputs. The system removes most of the bias with model simulations and improves predicted moisture climatology, achieving small test root-mean-squared error (<0.035) and high correlation coefficient >0.87 for over 75\% of Continental United States, including the forested Southeast. As the first application of LSTM in hydrology, we show the proposed network avoids overfitting and is robust for both temporal and spatial extrapolation tests. LSTM generalizes well across regions with distinct climates and physiography. With high fidelity to SMAP, LSTM shows great potential for hindcasting, data assimilation, and weather forecasting.