 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe data synergy effects of time-series deep learning models in hydrology
Paper and Code
Jan 06, 2021
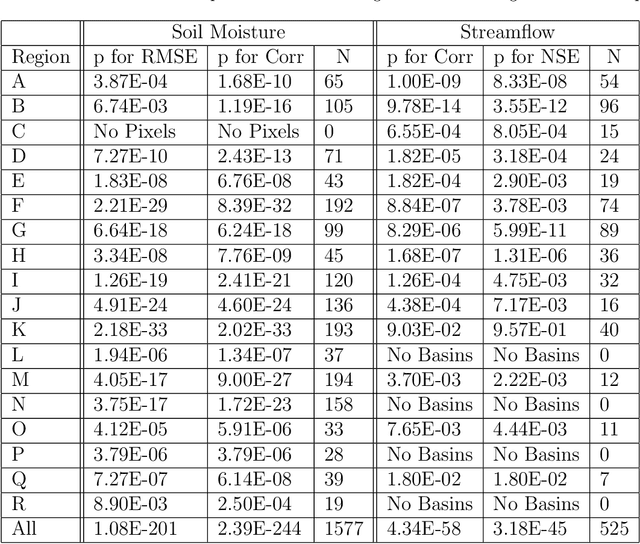
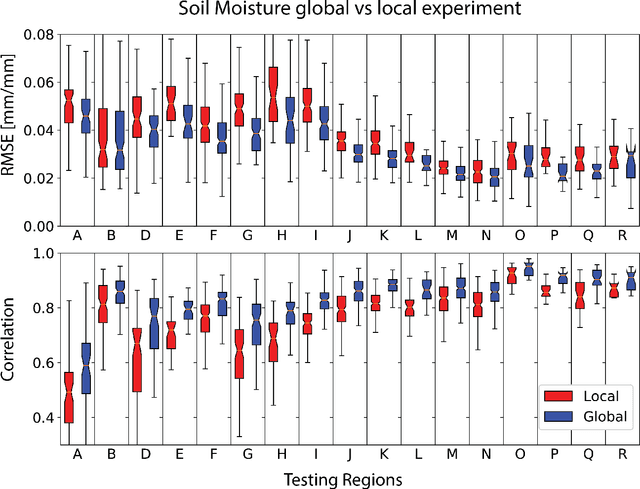
When fitting statistical models to variables in geoscientific disciplines such as hydrology, it is a customary practice to regionalize - to divide a large spatial domain into multiple regions and study each region separately - instead of fitting a single model on the entire data (also known as unification). Traditional wisdom in these fields suggests that models built for each region separately will have higher performance because of homogeneity within each region. However, by partitioning the training data, each model has access to fewer data points and cannot learn from commonalities between regions. Here, through two hydrologic examples (soil moisture and streamflow), we argue that unification can often significantly outperform regionalization in the era of big data and deep learning (DL). Common DL architectures, even without bespoke customization, can automatically build models that benefit from regional commonality while accurately learning region-specific differences. We highlight an effect we call data synergy, where the results of the DL models improved when data were pooled together from characteristically different regions. In fact, the performance of the DL models benefited from more diverse rather than more homogeneous training data. We hypothesize that DL models automatically adjust their internal representations to identify commonalities while also providing sufficient discriminatory information to the model. The results here advocate for pooling together larger datasets, and suggest the academic community should place greater emphasis on data sharing and compilation.