 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinct hydrologic response patterns and trends worldwide revealed by physics-embedded learning
Apr 14, 2025To track rapid changes within our water sector, Global Water Models (GWMs) need to realistically represent hydrologic systems' response patterns - such as baseflow fraction - but are hindered by their limited ability to learn from data. Here we introduce a high-resolution physics-embedded big-data-trained model as a breakthrough in reliably capturing characteristic hydrologic response patterns ('signatures') and their shifts. By realistically representing the long-term water balance, the model revealed widespread shifts - up to ~20% over 20 years - in fundamental green-blue-water partitioning and baseflow ratios worldwide. Shifts in these response patterns, previously considered static, contributed to increasing flood risks in northern mid-latitudes, heightening water supply stresses in southern subtropical regions, and declining freshwater inputs to many European estuaries, all with ecological implications. With more accurate simulations at monthly and daily scales than current operational systems, this next-generation model resolves large, nonlinear seasonal runoff responses to rainfall ('elasticity') and streamflow flashiness in semi-arid and arid regions. These metrics highlight regions with management challenges due to large water supply variability and high climate sensitivity, but also provide tools to forecast seasonal water availability. This capability newly enables global-scale models to deliver reliable and locally relevant insights for water management.
Update hydrological states or meteorological forcings? Comparing data assimilation methods for differentiable hydrologic models
Feb 23, 2025Data assimilation (DA) enables hydrologic models to update their internal states using near-real-time observations for more accurate forecasts. With deep neural networks like long short-term memory (LSTM), using either lagged observations as inputs (called "data integration") or variational DA has shown success in improving forecasts. However, it is unclear which methods are performant or optimal for physics-informed machine learning ("differentiable") models, which represent only a small amount of physically-meaningful states while using deep networks to supply parameters or missing processes. Here we developed variational DA methods for differentiable models, including optimizing adjusters for just precipitation data, just model internal hydrological states, or both. Our results demonstrated that differentiable streamflow models using the CAMELS dataset can benefit strongly and equivalently from variational DA as LSTM, with one-day lead time median Nash-Sutcliffe efficiency (NSE) elevated from 0.75 to 0.82. The resulting forecast matched or outperformed LSTM with DA in the eastern, northwestern, and central Great Plains regions of the conterminous United States. Both precipitation and state adjusters were needed to achieve these results, with the latter being substantially more effective on its own, and the former adding moderate benefits for high flows. Our DA framework does not need systematic training data and could serve as a practical DA scheme for whole river networks.
Differentiable modeling to unify machine learning and physical models and advance Geosciences
Jan 10, 2023



Process-Based Modeling (PBM) and Machine Learning (ML) are often perceived as distinct paradigms in the geosciences. Here we present differentiable geoscientific modeling as a powerful pathway toward dissolving the perceived barrier between them and ushering in a paradigm shift. For decades, PBM offered benefits in interpretability and physical consistency but struggled to efficiently leverage large datasets. ML methods, especially deep networks, presented strong predictive skills yet lacked the ability to answer specific scientific questions. While various methods have been proposed for ML-physics integration, an important underlying theme -- differentiable modeling -- is not sufficiently recognized. Here we outline the concepts, applicability, and significance of differentiable geoscientific modeling (DG). "Differentiable" refers to accurately and efficiently calculating gradients with respect to model variables, critically enabling the learning of high-dimensional unknown relationships. DG refers to a range of methods connecting varying amounts of prior knowledge to neural networks and training them together, capturing a different scope than physics-guided machine learning and emphasizing first principles. Preliminary evidence suggests DG offers better interpretability and causality than ML, improved generalizability and extrapolation capability, and strong potential for knowledge discovery, while approaching the performance of purely data-driven ML. DG models require less training data while scaling favorably in performance and efficiency with increasing amounts of data. With DG, geoscientists may be better able to frame and investigate questions, test hypotheses, and discover unrecognized linkages.
Differentiable, learnable, regionalized process-based models with physical outputs can approach state-of-the-art hydrologic prediction accuracy
Mar 28, 2022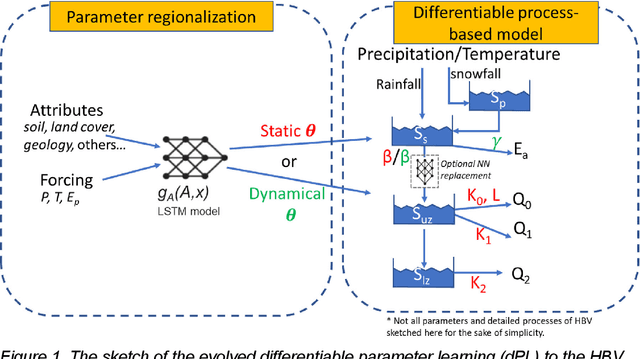
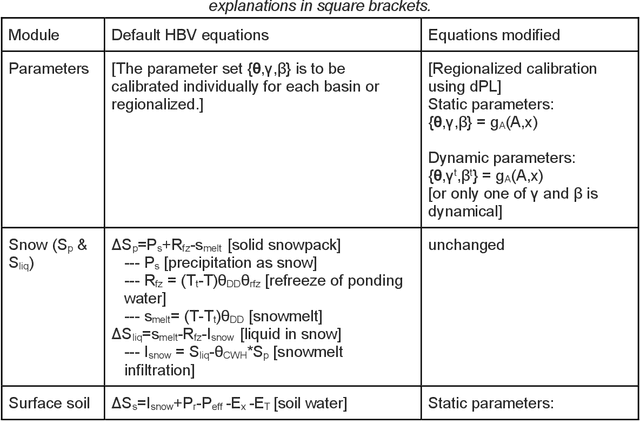

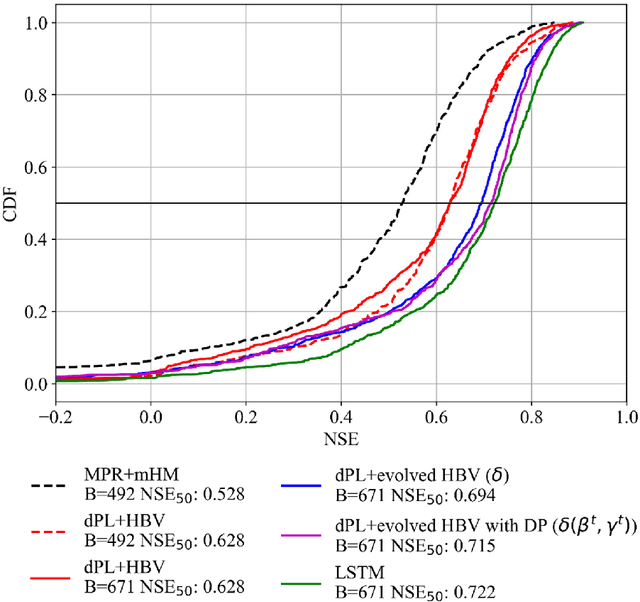
Predictions of hydrologic variables across the entire water cycle have significant value for water resource management as well as downstream applications such as ecosystem and water quality modeling. Recently, purely data-driven deep learning models like long short-term memory (LSTM) showed seemingly-insurmountable performance in modeling rainfall-runoff and other geoscientific variables, yet they cannot predict unobserved physical variables and remain challenging to interpret. Here we show that differentiable, learnable, process-based models (called {\delta} models here) can approach the performance level of LSTM for the intensively-observed variable (streamflow) with regionalized parameterization. We use a simple hydrologic model HBV as the backbone and use embedded neural networks, which can only be trained in a differentiable programming framework, to parameterize, replace, or enhance the process-based model modules. Without using an ensemble or post-processor, {\delta} models can obtain a median Nash Sutcliffe efficiency of 0.715 for 671 basins across the USA for a particular forcing data, compared to 0.72 from a state-of-the-art LSTM model with the same setup. Meanwhile, the resulting learnable process-based models can be evaluated (and later, to be trained) by multiple sources of observations, e.g., groundwater storage, evapotranspiration, surface runoff, and baseflow. Both simulated evapotranspiration and fraction of discharge from baseflow agreed decently with alternative estimates. The general framework can work with models with various process complexity and opens up the path for learning physics from big data.
Continental-scale streamflow modeling of basins with reservoirs: a demonstration of effectiveness and a delineation of challenges
Jan 12, 2021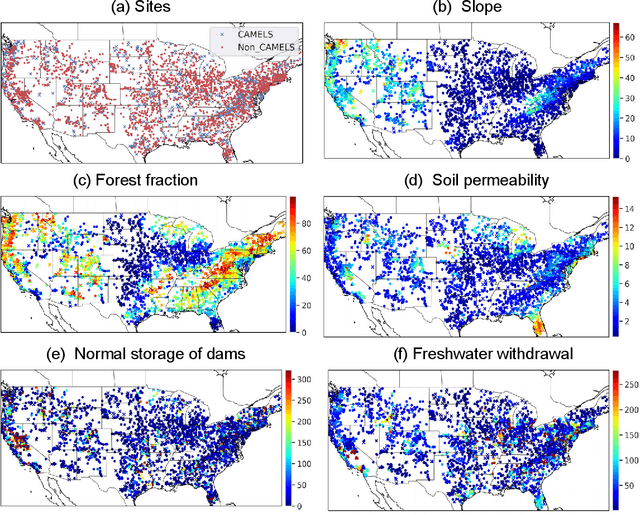


A large fraction of major waterways have dams influencing streamflow, which must be accounted for in large-scale hydrologic modeling. However, daily streamflow prediction for basins with dams is challenging for various modeling approaches, especially at large scales. Here we took a divide-and-conquer approach to examine which types of basins could be well represented by a long short-term memory (LSTM) deep learning model using only readily-available information. We analyzed data from 3557 basins (83% dammed) over the contiguous United States and noted strong impacts of reservoir purposes, capacity-to-runoff ratio (dor), and diversion on streamflow on streamflow modeling. Surprisingly, while the LSTM model trained on a widely-used reference-basin dataset performed poorly for more non-reference basins, the model trained on the whole dataset presented a median test Nash-Sutcliffe efficiency coefficient (NSE) of 0.74, reaching benchmark-level performance. The zero-dor, small-dor, and large-dor basins were found to have distinct behaviors, so migrating models between categories yielded catastrophic results. However, training with pooled data from different sets yielded optimal median NSEs of 0.73, 0.78, and 0.71 for these groups, respectively, showing noticeable advantages over existing models. These results support a coherent, mixed modeling strategy where smaller dams are modeled as part of rainfall-runoff processes, but dammed basins must not be treated as reference ones and must be included in the training set; then, large-dor reservoirs can be represented explicitly and future work should examine modeling reservoirs for fire protection and irrigation, followed by those for hydroelectric power generation, and flood control, etc.
The data synergy effects of time-series deep learning models in hydrology
Jan 06, 2021
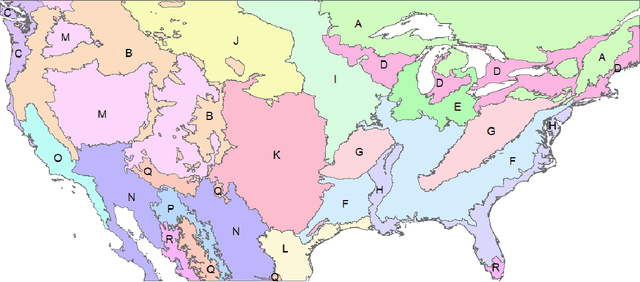
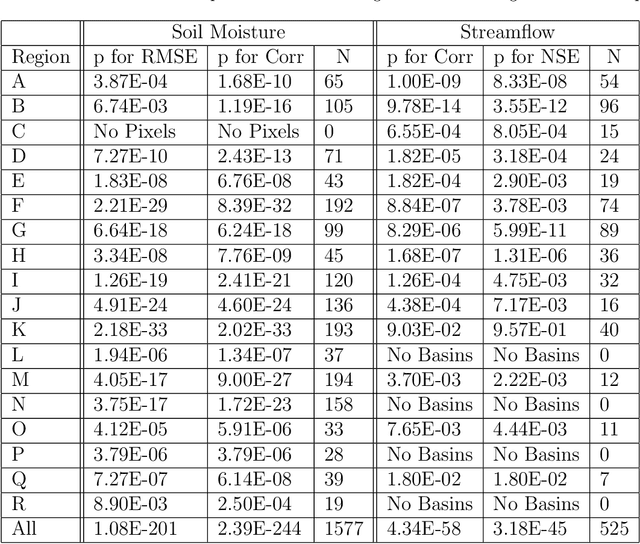
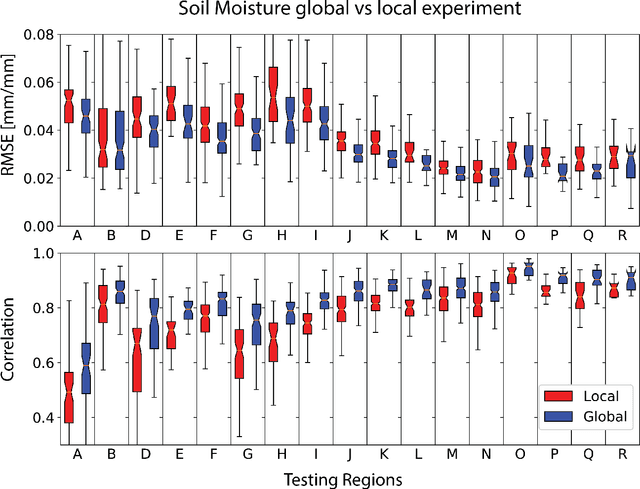
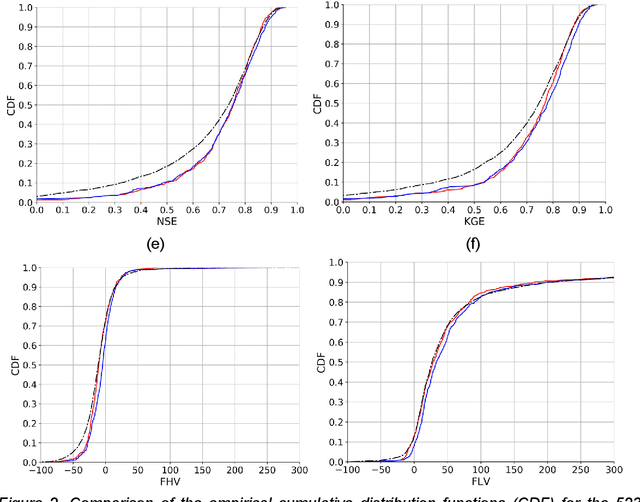
When fitting statistical models to variables in geoscientific disciplines such as hydrology, it is a customary practice to regionalize - to divide a large spatial domain into multiple regions and study each region separately - instead of fitting a single model on the entire data (also known as unification). Traditional wisdom in these fields suggests that models built for each region separately will have higher performance because of homogeneity within each region. However, by partitioning the training data, each model has access to fewer data points and cannot learn from commonalities between regions. Here, through two hydrologic examples (soil moisture and streamflow), we argue that unification can often significantly outperform regionalization in the era of big data and deep learning (DL). Common DL architectures, even without bespoke customization, can automatically build models that benefit from regional commonality while accurately learning region-specific differences. We highlight an effect we call data synergy, where the results of the DL models improved when data were pooled together from characteristically different regions. In fact, the performance of the DL models benefited from more diverse rather than more homogeneous training data. We hypothesize that DL models automatically adjust their internal representations to identify commonalities while also providing sufficient discriminatory information to the model. The results here advocate for pooling together larger datasets, and suggest the academic community should place greater emphasis on data sharing and compilation.
Prediction in ungauged regions with sparse flow duration curves and input-selection ensemble modeling
Nov 26, 2020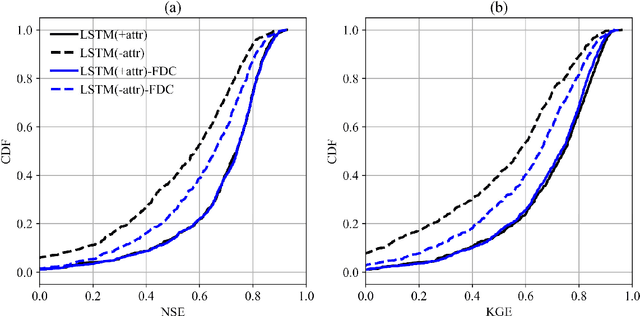
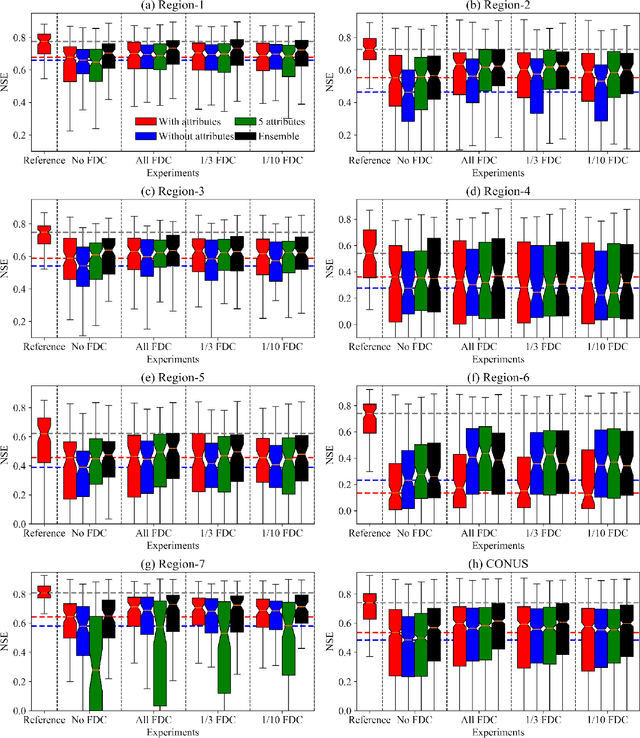

While long short-term memory (LSTM) models have demonstrated stellar performance with streamflow predictions, there are major risks in applying these models in contiguous regions with no gauges, or predictions in ungauged regions (PUR) problems. However, softer data such as the flow duration curve (FDC) may be already available from nearby stations, or may become available. Here we demonstrate that sparse FDC data can be migrated and assimilated by an LSTM-based network, via an encoder. A stringent region-based holdout test showed a median Kling-Gupta efficiency (KGE) of 0.62 for a US dataset, substantially higher than previous state-of-the-art global-scale ungauged basin tests. The baseline model without FDC was already competitive (median KGE 0.56), but integrating FDCs had substantial value. Because of the inaccurate representation of inputs, the baseline models might sometimes produce catastrophic results. However, model generalizability was further meaningfully improved by compiling an ensemble based on models with different input selections.
From parameter calibration to parameter learning: Revolutionizing large-scale geoscientific modeling with big data
Sep 12, 2020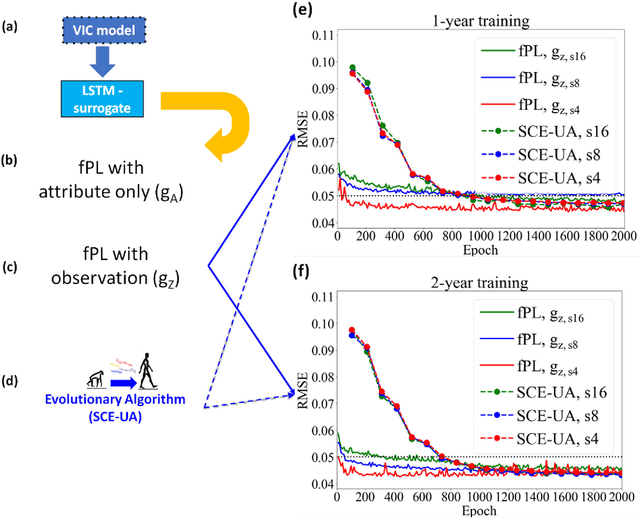
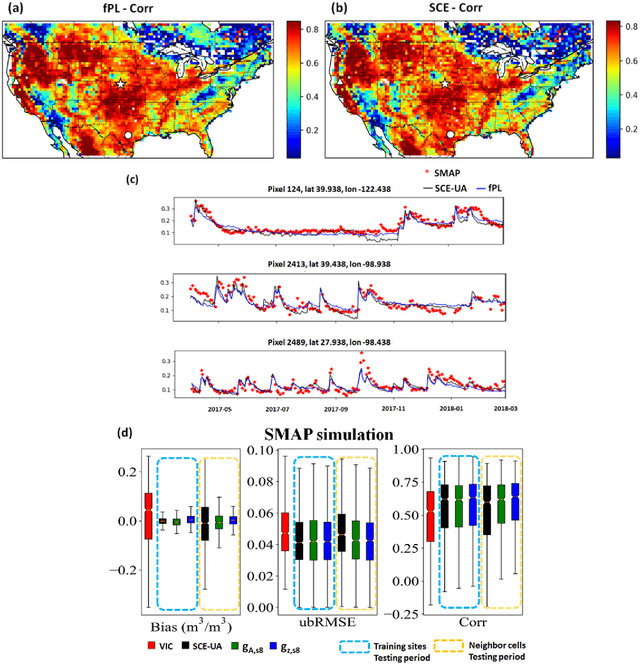
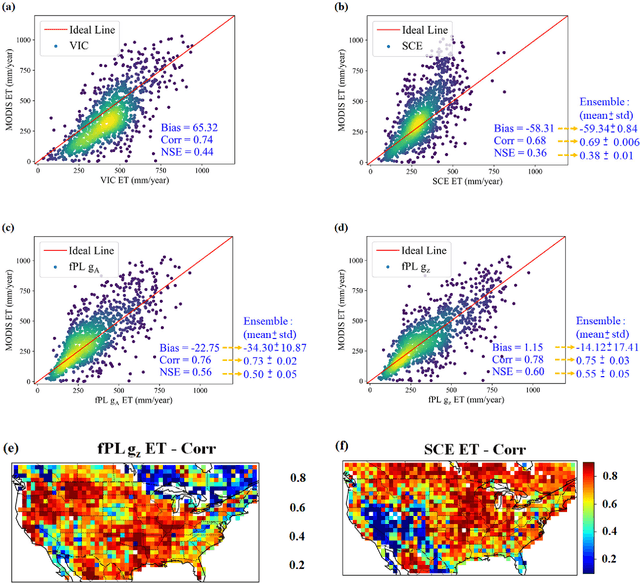
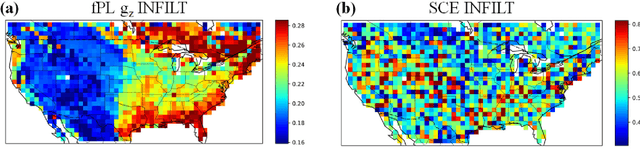
The behaviors and skills of models in many geoscientific domains strongly depend on spatially varying parameters that lack direct observations and must be determined by calibration. Calibration, which solves inverse problems, is a classical but inefficient and stochasticity-ridden approach to reconcile models and observations. Using a widely applied hydrologic model and soil moisture observations as a case study, here we propose a novel, forward-mapping parameter learning (fPL) framework. Whereas evolutionary algorithm (EA)-based calibration solves inversion problems one by one, fPL solves a pattern recognition problem and learns a more robust, universal mapping. fPL can save orders-of-magnitude computational time compared to EA-based calibration, while, surprisingly, producing equivalent ending skill metrics. With more training data, fPL learned across sites and showed super-convergence, scaling much more favorably. Moreover, a more important benefit emerged: fPL produced spatially-coherent parameters in better agreement with physical processes. As a result, it demonstrated better results for out-of-training-set locations and uncalibrated variables. Compared to purely data-driven models, fPL can output unobserved variables, in this case simulated evapotranspiration, which agrees better with satellite-based estimates than the comparison EA. The deep-learning-powered fPL frameworks can be uniformly applied to myriad other geoscientific models. We contend that a paradigm shift from inverse parameter calibration to parameter learning will greatly propel various geoscientific domains.