 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentiable Framework for Global Circulation Model Precipitation Bias Correction
Apr 24, 2026Systematic biases in Global Circulation Model (GCM) outputs limit their direct applicability in regional planning, necessitating bias correction. Correcting precipitation is particularly challenging due to its non-Gaussian distribution, intermittent nature, and non-linear extremes. However, traditional statistical methods cannot learn from big data and easily address systematic biases in the GCMs, and while machine learning does provide this flexibility, their black-box type functionality hinders us from understanding these biases completely which also further prevents generalization across different GCMs and locations, especially for precipitation. In this study, we propose a differentiable bias adjustment framework called δCLIMBA (or dCLIMBA), that learns a spatiotemporally adaptive parametric bias adjustment procedure between historical CMIP6 model outputs and reference reanalysis datasets (Livneh). Results demonstrate that the proposed method accurately corrects both the magnitude and distribution of extreme storm events, with particularly strong performance in capturing extremes. The quantile distribution of precipitation is well reproduced across diverse U.S. cities, and spatial patterns perform comparably to the widely used LOCA2 statistical downscaling technique. In addition, the framework showed future trend preservation unlike pure quantile based methods and LOCA2; and results from bias correction over unseen regions showed that the marginal biases were attenuated. This work presents a modular, computationally efficient and extensible bias correction approach that is physically informed, scalable, and compatible with both historical and future applications. Its flexibility makes it suitable for integration into Earth system post-processing pipelines and impact workflows.
Distinct hydrologic response patterns and trends worldwide revealed by physics-embedded learning
Apr 14, 2025To track rapid changes within our water sector, Global Water Models (GWMs) need to realistically represent hydrologic systems' response patterns - such as baseflow fraction - but are hindered by their limited ability to learn from data. Here we introduce a high-resolution physics-embedded big-data-trained model as a breakthrough in reliably capturing characteristic hydrologic response patterns ('signatures') and their shifts. By realistically representing the long-term water balance, the model revealed widespread shifts - up to ~20% over 20 years - in fundamental green-blue-water partitioning and baseflow ratios worldwide. Shifts in these response patterns, previously considered static, contributed to increasing flood risks in northern mid-latitudes, heightening water supply stresses in southern subtropical regions, and declining freshwater inputs to many European estuaries, all with ecological implications. With more accurate simulations at monthly and daily scales than current operational systems, this next-generation model resolves large, nonlinear seasonal runoff responses to rainfall ('elasticity') and streamflow flashiness in semi-arid and arid regions. These metrics highlight regions with management challenges due to large water supply variability and high climate sensitivity, but also provide tools to forecast seasonal water availability. This capability newly enables global-scale models to deliver reliable and locally relevant insights for water management.
Update hydrological states or meteorological forcings? Comparing data assimilation methods for differentiable hydrologic models
Feb 23, 2025

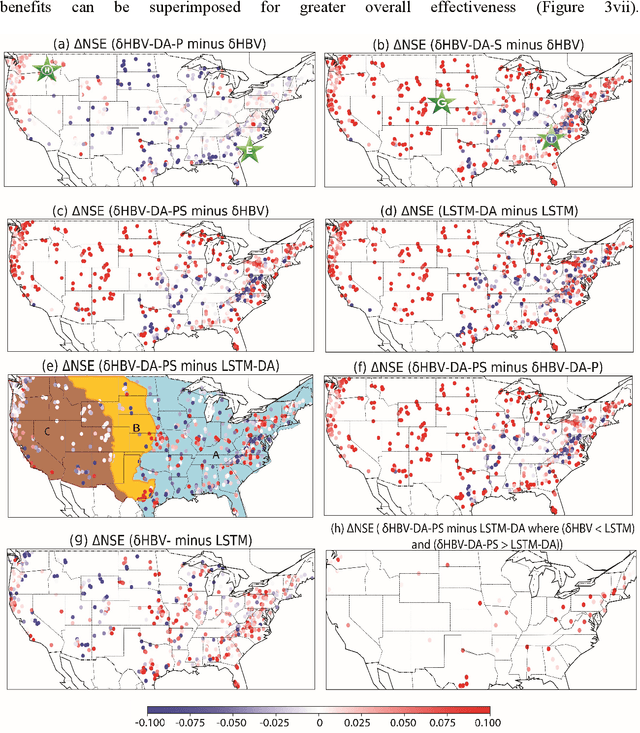

Data assimilation (DA) enables hydrologic models to update their internal states using near-real-time observations for more accurate forecasts. With deep neural networks like long short-term memory (LSTM), using either lagged observations as inputs (called "data integration") or variational DA has shown success in improving forecasts. However, it is unclear which methods are performant or optimal for physics-informed machine learning ("differentiable") models, which represent only a small amount of physically-meaningful states while using deep networks to supply parameters or missing processes. Here we developed variational DA methods for differentiable models, including optimizing adjusters for just precipitation data, just model internal hydrological states, or both. Our results demonstrated that differentiable streamflow models using the CAMELS dataset can benefit strongly and equivalently from variational DA as LSTM, with one-day lead time median Nash-Sutcliffe efficiency (NSE) elevated from 0.75 to 0.82. The resulting forecast matched or outperformed LSTM with DA in the eastern, northwestern, and central Great Plains regions of the conterminous United States. Both precipitation and state adjusters were needed to achieve these results, with the latter being substantially more effective on its own, and the former adding moderate benefits for high flows. Our DA framework does not need systematic training data and could serve as a practical DA scheme for whole river networks.
SAMIC: Segment Anything with In-Context Spatial Prompt Engineering
Dec 16, 2024Few-shot segmentation is the problem of learning to identify specific types of objects (e.g., airplanes) in images from a small set of labeled reference images. The current state of the art is driven by resource-intensive construction of models for every new domain-specific application. Such models must be trained on enormous labeled datasets of unrelated objects (e.g., cars, trains, animals) so that their ``knowledge'' can be transferred to new types of objects. In this paper, we show how to leverage existing vision foundation models (VFMs) to reduce the incremental cost of creating few-shot segmentation models for new domains. Specifically, we introduce SAMIC, a small network that learns how to prompt VFMs in order to segment new types of objects in domain-specific applications. SAMIC enables any task to be approached as a few-shot learning problem. At 2.6 million parameters, it is 94% smaller than the leading models (e.g., having ResNet 101 backbone with 45+ million parameters). Even using 1/5th of the training data provided by one-shot benchmarks, SAMIC is competitive with, or sets the state of the art, on a variety of few-shot and semantic segmentation datasets including COCO-$20^i$, Pascal-$5^i$, PerSeg, FSS-1000, and NWPU VHR-10.
Estimating Uncertainty in Landslide Segmentation Models
Nov 18, 2023Landslides are a recurring, widespread hazard. Preparation and mitigation efforts can be aided by a high-quality, large-scale dataset that covers global at-risk areas. Such a dataset currently does not exist and is impossible to construct manually. Recent automated efforts focus on deep learning models for landslide segmentation (pixel labeling) from satellite imagery. However, it is also important to characterize the uncertainty or confidence levels of such segmentations. Accurate and robust uncertainty estimates can enable low-cost (in terms of manual labor) oversight of auto-generated landslide databases to resolve errors, identify hard negative examples, and increase the size of labeled training data. In this paper, we evaluate several methods for assessing pixel-level uncertainty of the segmentation. Three methods that do not require architectural changes were compared, including Pre-Threshold activations, Monte-Carlo Dropout and Test-Time Augmentation -- a method that measures the robustness of predictions in the face of data augmentation. Experimentally, the quality of the latter method was consistently higher than the others across a variety of models and metrics in our dataset.
Probing the limit of hydrologic predictability with the Transformer network
Jun 21, 2023

For a number of years since its introduction to hydrology, recurrent neural networks like long short-term memory (LSTM) have proven remarkably difficult to surpass in terms of daily hydrograph metrics on known, comparable benchmarks. Outside of hydrology, Transformers have now become the model of choice for sequential prediction tasks, making it a curious architecture to investigate. Here, we first show that a vanilla Transformer architecture is not competitive against LSTM on the widely benchmarked CAMELS dataset, and lagged especially for the high-flow metrics due to short-term processes. However, a recurrence-free variant of Transformer can obtain mixed comparisons with LSTM, producing the same Kling-Gupta efficiency coefficient (KGE), along with other metrics. The lack of advantages for the Transformer is linked to the Markovian nature of the hydrologic prediction problem. Similar to LSTM, the Transformer can also merge multiple forcing dataset to improve model performance. While the Transformer results are not higher than current state-of-the-art, we still learned some valuable lessons: (1) the vanilla Transformer architecture is not suitable for hydrologic modeling; (2) the proposed recurrence-free modification can improve Transformer performance so future work can continue to test more of such modifications; and (3) the prediction limits on the dataset should be close to the current state-of-the-art model. As a non-recurrent model, the Transformer may bear scale advantages for learning from bigger datasets and storing knowledge. This work serves as a reference point for future modifications of the model.
Differentiable modeling to unify machine learning and physical models and advance Geosciences
Jan 10, 2023



Process-Based Modeling (PBM) and Machine Learning (ML) are often perceived as distinct paradigms in the geosciences. Here we present differentiable geoscientific modeling as a powerful pathway toward dissolving the perceived barrier between them and ushering in a paradigm shift. For decades, PBM offered benefits in interpretability and physical consistency but struggled to efficiently leverage large datasets. ML methods, especially deep networks, presented strong predictive skills yet lacked the ability to answer specific scientific questions. While various methods have been proposed for ML-physics integration, an important underlying theme -- differentiable modeling -- is not sufficiently recognized. Here we outline the concepts, applicability, and significance of differentiable geoscientific modeling (DG). "Differentiable" refers to accurately and efficiently calculating gradients with respect to model variables, critically enabling the learning of high-dimensional unknown relationships. DG refers to a range of methods connecting varying amounts of prior knowledge to neural networks and training them together, capturing a different scope than physics-guided machine learning and emphasizing first principles. Preliminary evidence suggests DG offers better interpretability and causality than ML, improved generalizability and extrapolation capability, and strong potential for knowledge discovery, while approaching the performance of purely data-driven ML. DG models require less training data while scaling favorably in performance and efficiency with increasing amounts of data. With DG, geoscientists may be better able to frame and investigate questions, test hypotheses, and discover unrecognized linkages.
ThreshNet: Segmentation Refinement Inspired by Region-Specific Thresholding
Nov 20, 2022We present ThreshNet, a post-processing method to refine the output of neural networks designed for binary segmentation tasks. ThreshNet uses the confidence map produced by a base network along with global and local patch information to significantly improve the performance of even state-of-the-art methods. Binary segmentation models typically convert confidence maps into predictions by thresholding the confidence scores at 0.5 (or some other fixed number). However, we observe that the best threshold is image-dependent and often even region-specific -- different parts of the image benefit from using different thresholds. Thus ThreshNet takes a trained segmentation model and learns to correct its predictions by using a memory-efficient post-processing architecture that incorporates region-specific thresholds as part of the training mechanism. Our experiments show that ThreshNet consistently improves over current the state-of-the-art methods in binary segmentation and saliency detection, typically by 3 to 5% in mIoU and mBA.
Differentiable, learnable, regionalized process-based models with physical outputs can approach state-of-the-art hydrologic prediction accuracy
Mar 28, 2022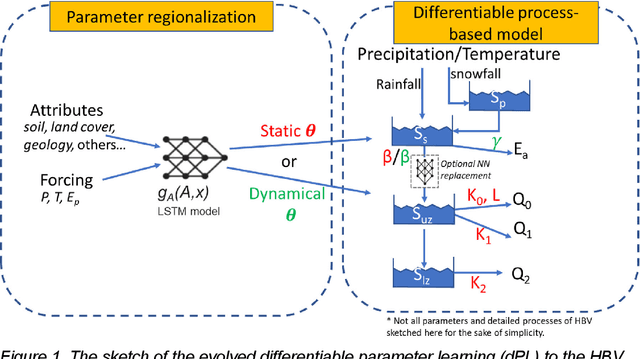
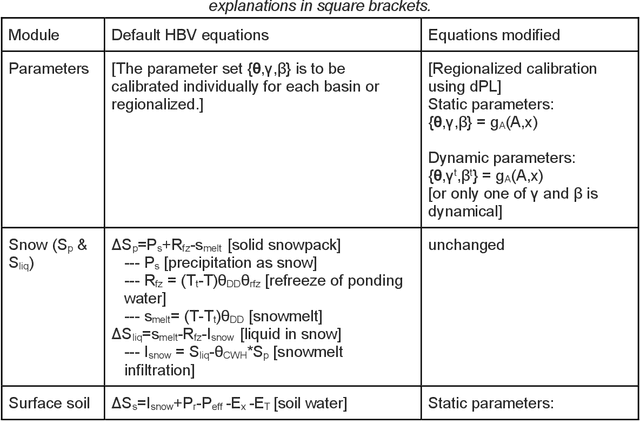

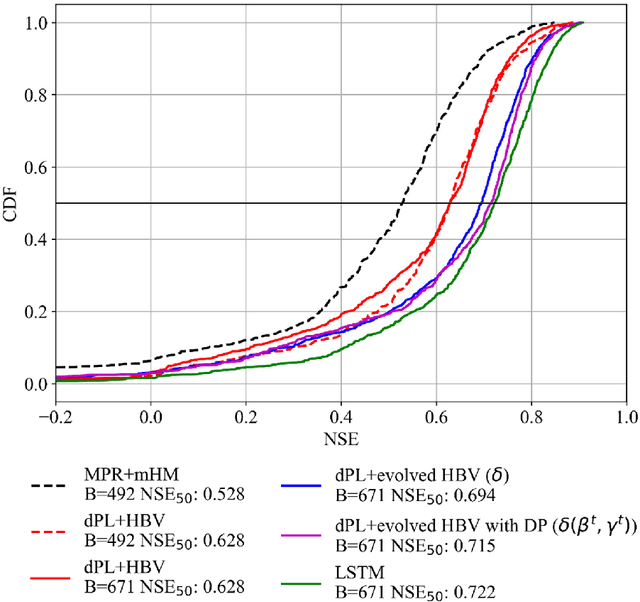
Predictions of hydrologic variables across the entire water cycle have significant value for water resource management as well as downstream applications such as ecosystem and water quality modeling. Recently, purely data-driven deep learning models like long short-term memory (LSTM) showed seemingly-insurmountable performance in modeling rainfall-runoff and other geoscientific variables, yet they cannot predict unobserved physical variables and remain challenging to interpret. Here we show that differentiable, learnable, process-based models (called {\delta} models here) can approach the performance level of LSTM for the intensively-observed variable (streamflow) with regionalized parameterization. We use a simple hydrologic model HBV as the backbone and use embedded neural networks, which can only be trained in a differentiable programming framework, to parameterize, replace, or enhance the process-based model modules. Without using an ensemble or post-processor, {\delta} models can obtain a median Nash Sutcliffe efficiency of 0.715 for 671 basins across the USA for a particular forcing data, compared to 0.72 from a state-of-the-art LSTM model with the same setup. Meanwhile, the resulting learnable process-based models can be evaluated (and later, to be trained) by multiple sources of observations, e.g., groundwater storage, evapotranspiration, surface runoff, and baseflow. Both simulated evapotranspiration and fraction of discharge from baseflow agreed decently with alternative estimates. The general framework can work with models with various process complexity and opens up the path for learning physics from big data.
Bathymetry Inversion using a Deep-Learning-Based Surrogate for Shallow Water Equations Solvers
Mar 05, 2022

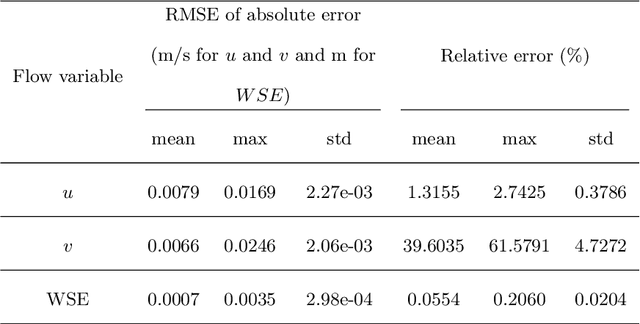
River bathymetry is critical for many aspects of water resources management. We propose and demonstrate a bathymetry inversion method using a deep-learning-based surrogate for shallow water equations solvers. The surrogate uses the convolutional autoencoder with a shared-encoder, separate-decoder architecture. It encodes the input bathymetry and decodes to separate outputs for flow-field variables. A gradient-based optimizer is used to perform bathymetry inversion with the trained surrogate. Two physically-based constraints on both bed elevation value and slope have to be added as inversion loss regularizations to obtain usable inversion results. Using the "L-curve" criterion, a heuristic approach was proposed to determine the regularization parameters. Both the surrogate model and the inversion algorithm show good performance. We found the bathymetry inversion process has two distinctive stages, which resembles the sculptural process of initial broad-brush calving and final detailing. The inversion loss due to flow prediction error reaches its minimum in the first stage and remains almost constant afterward. The bed elevation value and slope regularizations play the dominant role in the second stage in selecting the most probable solution. We also found the surrogate architecture (whether with both velocity and water surface elevation or velocity only as outputs) does not show significant impact on inversion result.