 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024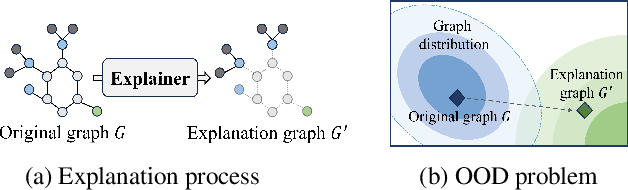
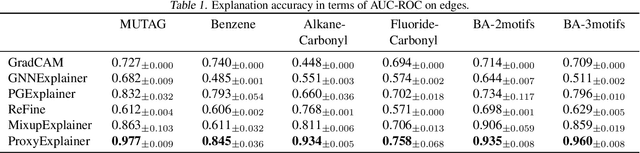
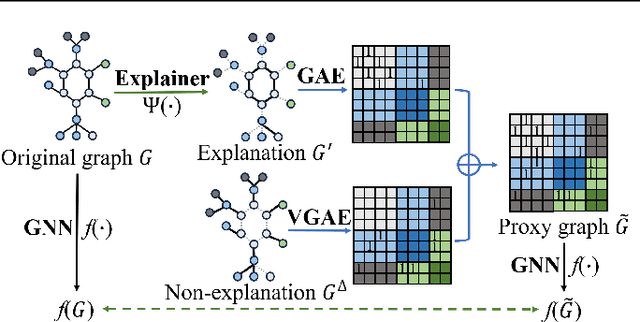

Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.
Random Walk on Multiple Networks
Jul 04, 2023Random Walk is a basic algorithm to explore the structure of networks, which can be used in many tasks, such as local community detection and network embedding. Existing random walk methods are based on single networks that contain limited information. In contrast, real data often contain entities with different types or/and from different sources, which are comprehensive and can be better modeled by multiple networks. To take advantage of rich information in multiple networks and make better inferences on entities, in this study, we propose random walk on multiple networks, RWM. RWM is flexible and supports both multiplex networks and general multiple networks, which may form many-to-many node mappings between networks. RWM sends a random walker on each network to obtain the local proximity (i.e., node visiting probabilities) w.r.t. the starting nodes. Walkers with similar visiting probabilities reinforce each other. We theoretically analyze the convergence properties of RWM. Two approximation methods with theoretical performance guarantees are proposed for efficient computation. We apply RWM in link prediction, network embedding, and local community detection. Comprehensive experiments conducted on both synthetic and real-world datasets demonstrate the effectiveness and efficiency of RWM.
Probing the limit of hydrologic predictability with the Transformer network
Jun 21, 2023For a number of years since its introduction to hydrology, recurrent neural networks like long short-term memory (LSTM) have proven remarkably difficult to surpass in terms of daily hydrograph metrics on known, comparable benchmarks. Outside of hydrology, Transformers have now become the model of choice for sequential prediction tasks, making it a curious architecture to investigate. Here, we first show that a vanilla Transformer architecture is not competitive against LSTM on the widely benchmarked CAMELS dataset, and lagged especially for the high-flow metrics due to short-term processes. However, a recurrence-free variant of Transformer can obtain mixed comparisons with LSTM, producing the same Kling-Gupta efficiency coefficient (KGE), along with other metrics. The lack of advantages for the Transformer is linked to the Markovian nature of the hydrologic prediction problem. Similar to LSTM, the Transformer can also merge multiple forcing dataset to improve model performance. While the Transformer results are not higher than current state-of-the-art, we still learned some valuable lessons: (1) the vanilla Transformer architecture is not suitable for hydrologic modeling; (2) the proposed recurrence-free modification can improve Transformer performance so future work can continue to test more of such modifications; and (3) the prediction limits on the dataset should be close to the current state-of-the-art model. As a non-recurrent model, the Transformer may bear scale advantages for learning from bigger datasets and storing knowledge. This work serves as a reference point for future modifications of the model.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022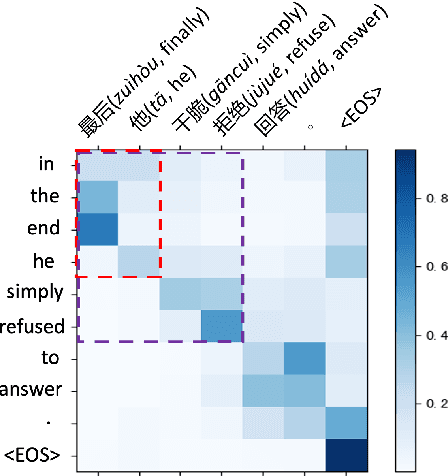
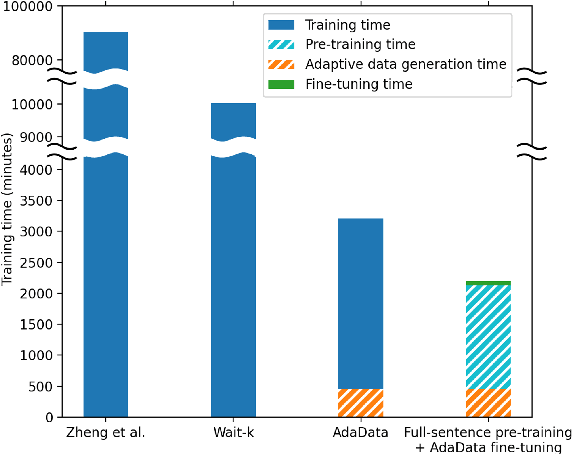
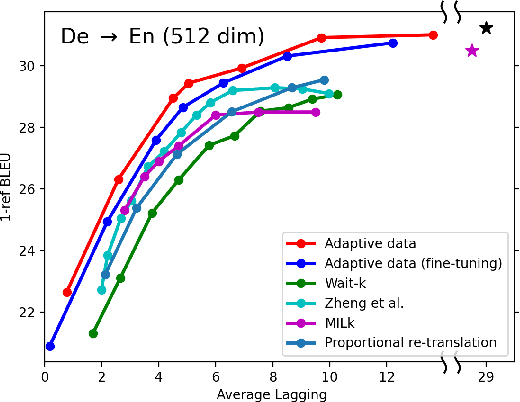
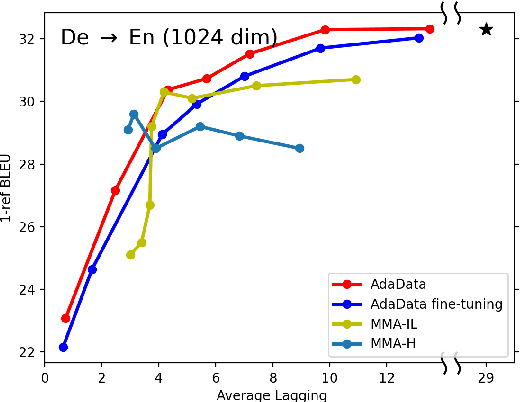
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
Attentive Social Recommendation: Towards User And Item Diversities
Nov 15, 2020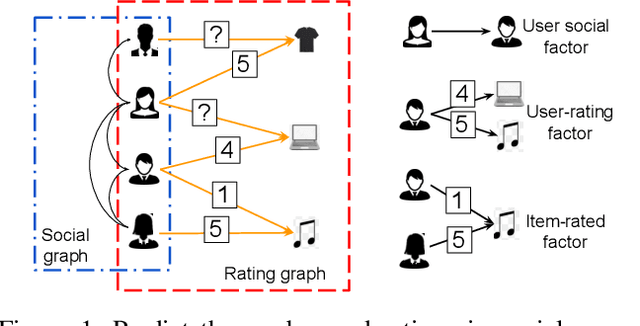

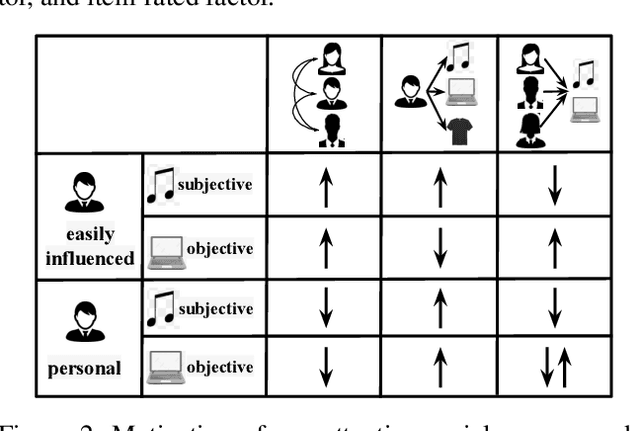

Social recommendation system is to predict unobserved user-item rating values by taking advantage of user-user social relation and user-item ratings. However, user/item diversities in social recommendations are not well utilized in the literature. Especially, inter-factor (social and rating factors) relations and distinct rating values need taking into more consideration. In this paper, we propose an attentive social recommendation system (ASR) to address this issue from two aspects. First, in ASR, Rec-conv graph network layers are proposed to extract the social factor, user-rating and item-rated factors and then automatically assign contribution weights to aggregate these factors into the user/item embedding vectors. Second, a disentangling strategy is applied for diverse rating values. Extensive experiments on benchmarks demonstrate the effectiveness and advantages of our ASR.