 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE-PD: Explainable AI on Subjective and Clinical Objective Measurements of Parkinson's Disease for Precision Decision-Making
Jan 30, 2026Parkinson's disease (PD) is a chronic and complex neurodegenerative disorder influenced by genetic, clinical, and lifestyle factors. Predicting this disease early is challenging because it depends on traditional diagnostic methods that face issues of subjectivity, which commonly delay diagnosis. Several objective analyses are currently in practice to help overcome the challenges of subjectivity; however, a proper explanation of these analyses is still lacking. While machine learning (ML) has demonstrated potential in supporting PD diagnosis, existing approaches often rely on subjective reports only and lack interpretability for individualized risk estimation. This study proposes SCOPE-PD, an explainable AI-based prediction framework, by integrating subjective and objective assessments to provide personalized health decisions. Subjective and objective clinical assessment data are collected from the Parkinson's Progression Markers Initiative (PPMI) study to construct a multimodal prediction framework. Several ML techniques are applied to these data, and the best ML model is selected to interpret the results. Model interpretability is examined using SHAP-based analysis. The Random Forest algorithm achieves the highest accuracy of 98.66 percent using combined features from both subjective and objective test data. Tremor, bradykinesia, and facial expression are identified as the top three contributing features from the MDS-UPDRS test in the prediction of PD.
Interpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024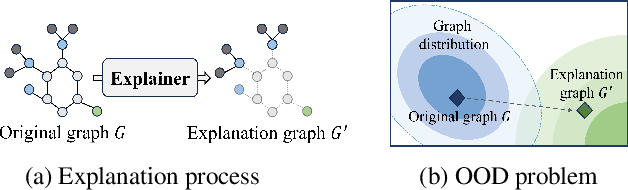
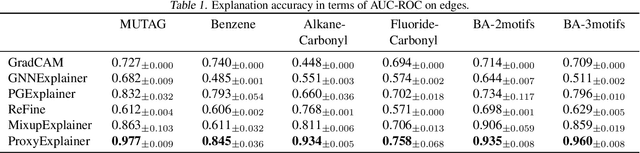
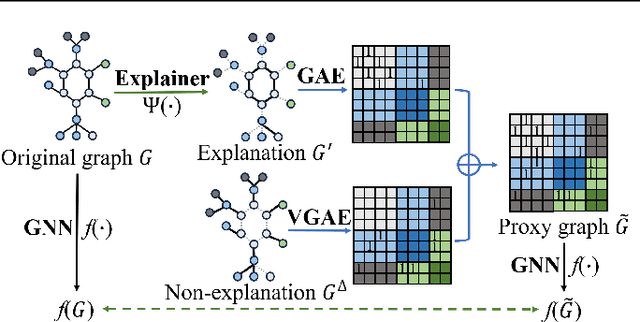

Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.