 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoSearch: Complexity-Aware Routing and Plan-Level Repair for Text-to-SQL
Jun 16, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in translating natural language to SQL, yet existing methods still falter on complex queries requiring multi-step, data-aware reasoning. We introduce DecoSearch, a training-free framework that addresses this by routing each query to the appropriate level of reasoning effort. A lightweight Schema Selector first prunes the full database schema to the relevant tables and columns. An LLM Judger then decides whether the question requires decomposition: straightforward questions follow a direct generation path and complex ones are escalated to a Directed Acyclic Graph (DAG) of atomic sub-questions, each solved by a targeted SQL generation step. A RAG component grounds the decomposer with semantically similar training examples, and a Topology Refiner restructures the reasoning plan when execution failures signal a flawed decomposition rather than a fixable SQL error. DecoSearch achieves 70.53% execution accuracy on BIRD and 88.31% on Spider with a DeepSeek backbone, surpassing all training-free baselines while consuming an order of magnitude fewer tokens than competing methods. It also functions as a model-agnostic wrapper, consistently improving fine-tuned SQL generation backbones without any modification to the pipeline.
BLaDA: Bridging Language to Functional Dexterous Actions within 3DGS Fields
Apr 09, 2026In unstructured environments, functional dexterous grasping calls for the tight integration of semantic understanding, precise 3D functional localization, and physically interpretable execution. Modular hierarchical methods are more controllable and interpretable than end-to-end VLA approaches, but existing ones still rely on predefined affordance labels and lack the tight semantic--pose coupling needed for functional dexterous manipulation. To address this, we propose BLaDA (Bridging Language to Dexterous Actions in 3DGS fields), an interpretable zero-shot framework that grounds open-vocabulary instructions as perceptual and control constraints for functional dexterous manipulation. BLaDA establishes an interpretable reasoning chain by first parsing natural language into a structured sextuple of manipulation constraints via a Knowledge-guided Language Parsing (KLP) module. To achieve pose-consistent spatial reasoning, we introduce the Triangular Functional Point Localization (TriLocation) module, which utilizes 3D Gaussian Splatting as a continuous scene representation and identifies functional regions under triangular geometric constraints. Finally, the 3D Keypoint Grasp Matrix Transformation Execution (KGT3D+) module decodes these semantic-geometric constraints into physically plausible wrist poses and finger-level commands. Extensive experiments on complex benchmarks demonstrate that BLaDA significantly outperforms existing methods in both affordance grounding precision and the success rate of functional manipulation across diverse categories and tasks. Code will be publicly available at https://github.com/PopeyePxx/BLaDA.
LUMOS: Democratizing SciML Workflows with L0-Regularized Learning for Unified Feature and Parameter Adaptation
Feb 26, 2026The rapid growth of scientific machine learning (SciML) has accelerated discovery across diverse domains, yet designing effective SciML models remains a challenging task. In practice, building such models often requires substantial prior knowledge and manual expertise, particularly in determining which input features to use and how large the model should be. We introduce LUMOS, an end-to-end framework based on L0-regularized learning that unifies feature selection and model pruning to democratize SciML model design. By employing semi-stochastic gating and reparameterization techniques, LUMOS dynamically selects informative features and prunes redundant parameters during training, reducing the reliance on manual tuning while maintaining predictive accuracy. We evaluate LUMOS across 13 diverse SciML workloads, including cosmology and molecular sciences, and demonstrate its effectiveness and generalizability. Experiments on 13 SciML models show that LUMOS achieves 71.45% parameter reduction and a 6.4x inference speedup on average. Furthermore, Distributed Data Parallel (DDP) training on up to eight GPUs confirms the scalability of
KORAL: Knowledge Graph Guided LLM Reasoning for SSD Operational Analysis
Feb 10, 2026Solid State Drives (SSDs) are critical to datacenters, consumer platforms, and mission-critical systems. Yet diagnosing their performance and reliability is difficult because data are fragmented and time-disjoint, and existing methods demand large datasets and expert input while offering only limited insights. Degradation arises not only from shifting workloads and evolving architectures but also from environmental factors such as temperature, humidity, and vibration. We present KORAL, a knowledge driven reasoning framework that integrates Large Language Models (LLMs) with a structured Knowledge Graph (KG) to generate insights into SSD operations. Unlike traditional approaches that require extensive expert input and large datasets, KORAL generates a Data KG from fragmented telemetry and integrates a Literature KG that already organizes knowledge from literature, reports, and traces. This turns unstructured sources into a queryable graph and telemetry into structured knowledge, and both the Graphs guide the LLM to deliver evidence-based, explainable analysis aligned with the domain vocabulary and constraints. Evaluation using real production traces shows that the KORAL delivers expert-level diagnosis and recommendations, supported by grounded explanations that improve reasoning transparency, guide operator decisions, reduce manual effort, and provide actionable insights to improve service quality. To our knowledge, this is the first end-to-end system that combines LLMs and KGs for full-spectrum SSD reasoning including Descriptive, Predictive, Prescriptive, and What-if analysis. We release the generated SSD-specific KG to advance reproducible research in knowledge-based storage system analysis. GitHub Repository: https://github.com/Damrl-lab/KORAL
CURENet: Combining Unified Representations for Efficient Chronic Disease Prediction
Nov 14, 2025Electronic health records (EHRs) are designed to synthesize diverse data types, including unstructured clinical notes, structured lab tests, and time-series visit data. Physicians draw on these multimodal and temporal sources of EHR data to form a comprehensive view of a patient's health, which is crucial for informed therapeutic decision-making. Yet, most predictive models fail to fully capture the interactions, redundancies, and temporal patterns across multiple data modalities, often focusing on a single data type or overlooking these complexities. In this paper, we present CURENet, a multimodal model (Combining Unified Representations for Efficient chronic disease prediction) that integrates unstructured clinical notes, lab tests, and patients' time-series data by utilizing large language models (LLMs) for clinical text processing and textual lab tests, as well as transformer encoders for longitudinal sequential visits. CURENet has been capable of capturing the intricate interaction between different forms of clinical data and creating a more reliable predictive model for chronic illnesses. We evaluated CURENet using the public MIMIC-III and private FEMH datasets, where it achieved over 94\% accuracy in predicting the top 10 chronic conditions in a multi-label framework. Our findings highlight the potential of multimodal EHR integration to enhance clinical decision-making and improve patient outcomes.
Feature-Function Curvature Analysis: A Geometric Framework for Explaining Differentiable Models
Oct 31, 2025Explainable AI (XAI) is critical for building trust in complex machine learning models, yet mainstream attribution methods often provide an incomplete, static picture of a model's final state. By collapsing a feature's role into a single score, they are confounded by non-linearity and interactions. To address this, we introduce Feature-Function Curvature Analysis (FFCA), a novel framework that analyzes the geometry of a model's learned function. FFCA produces a 4-dimensional signature for each feature, quantifying its: (1) Impact, (2) Volatility, (3) Non-linearity, and (4) Interaction. Crucially, we extend this framework into Dynamic Archetype Analysis, which tracks the evolution of these signatures throughout the training process. This temporal view moves beyond explaining what a model learned to revealing how it learns. We provide the first direct, empirical evidence of hierarchical learning, showing that models consistently learn simple linear effects before complex interactions. Furthermore, this dynamic analysis provides novel, practical diagnostics for identifying insufficient model capacity and predicting the onset of overfitting. Our comprehensive experiments demonstrate that FFCA, through its static and dynamic components, provides the essential geometric context that transforms model explanation from simple quantification to a nuanced, trustworthy analysis of the entire learning process.
LM$^2$otifs : An Explainable Framework for Machine-Generated Texts Detection
May 18, 2025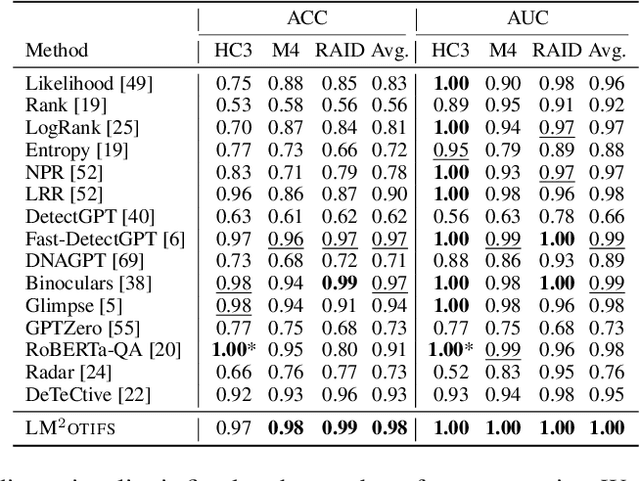
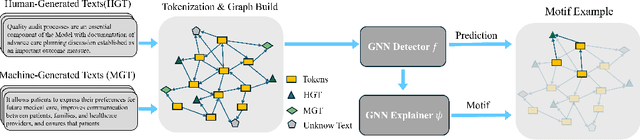
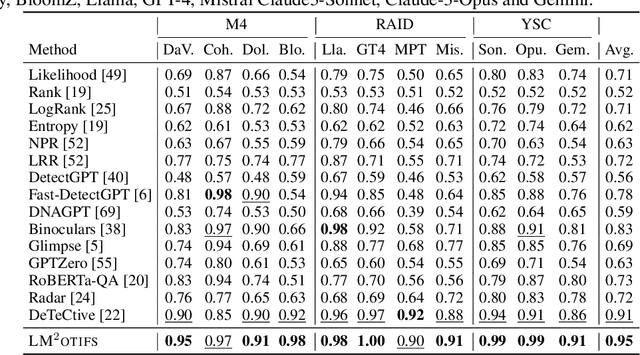
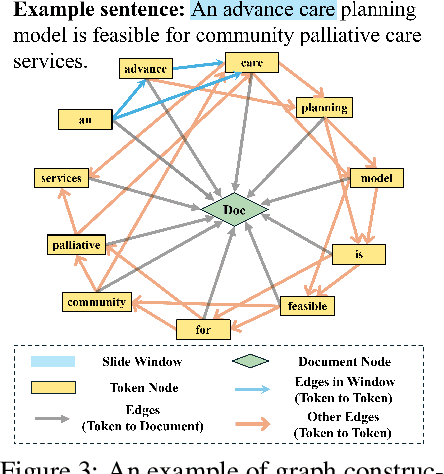
The impressive ability of large language models to generate natural text across various tasks has led to critical challenges in authorship authentication. Although numerous detection methods have been developed to differentiate between machine-generated texts (MGT) and human-generated texts (HGT), the explainability of these methods remains a significant gap. Traditional explainability techniques often fall short in capturing the complex word relationships that distinguish HGT from MGT. To address this limitation, we present LM$^2$otifs, a novel explainable framework for MGT detection. Inspired by probabilistic graphical models, we provide a theoretical rationale for the effectiveness. LM$^2$otifs utilizes eXplainable Graph Neural Networks to achieve both accurate detection and interpretability. The LM$^2$otifs pipeline operates in three key stages: first, it transforms text into graphs based on word co-occurrence to represent lexical dependencies; second, graph neural networks are used for prediction; and third, a post-hoc explainability method extracts interpretable motifs, offering multi-level explanations from individual words to sentence structures. Extensive experiments on multiple benchmark datasets demonstrate the comparable performance of LM$^2$otifs. The empirical evaluation of the extracted explainable motifs confirms their effectiveness in differentiating HGT and MGT. Furthermore, qualitative analysis reveals distinct and visible linguistic fingerprints characteristic of MGT.
Multi-Keypoint Affordance Representation for Functional Dexterous Grasping
Feb 27, 2025



Functional dexterous grasping requires precise hand-object interaction, going beyond simple gripping. Existing affordance-based methods primarily predict coarse interaction regions and cannot directly constrain the grasping posture, leading to a disconnection between visual perception and manipulation. To address this issue, we propose a multi-keypoint affordance representation for functional dexterous grasping, which directly encodes task-driven grasp configurations by localizing functional contact points. Our method introduces Contact-guided Multi-Keypoint Affordance (CMKA), leveraging human grasping experience images for weak supervision combined with Large Vision Models for fine affordance feature extraction, achieving generalization while avoiding manual keypoint annotations. Additionally, we present a Keypoint-based Grasp matrix Transformation (KGT) method, ensuring spatial consistency between hand keypoints and object contact points, thus providing a direct link between visual perception and dexterous grasping actions. Experiments on public real-world FAH datasets, IsaacGym simulation, and challenging robotic tasks demonstrate that our method significantly improves affordance localization accuracy, grasp consistency, and generalization to unseen tools and tasks, bridging the gap between visual affordance learning and dexterous robotic manipulation. The source code and demo videos will be publicly available at https://github.com/PopeyePxx/MKA.
NeuroTree: Hierarchical Functional Brain Pathway Decoding for Mental Health Disorders
Feb 26, 2025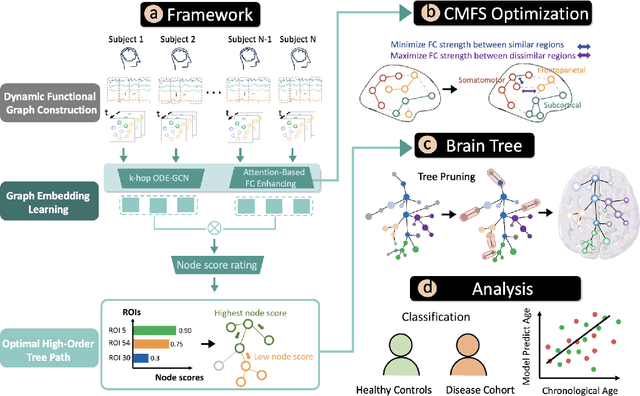
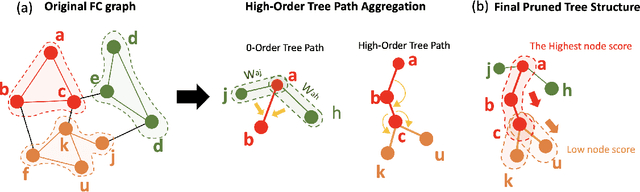
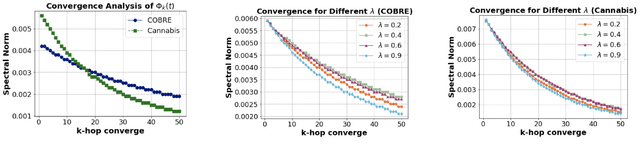
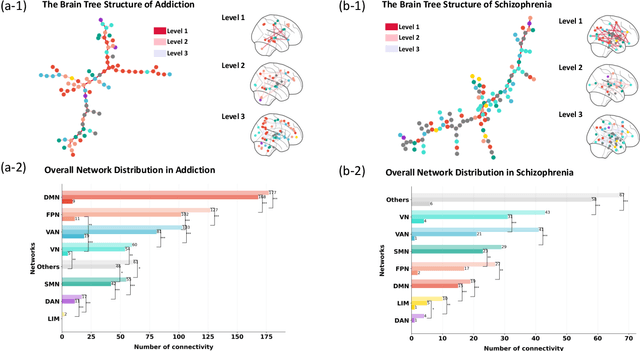
Analyzing functional brain networks using functional magnetic resonance imaging (fMRI) is crucial for understanding psychiatric disorders and addictive behaviors. While existing fMRI-based graph convolutional networks (GCNs) show considerable promise for feature extraction, they often fall short in characterizing complex relationships between brain regions and demographic factors and accounting for interpretable variables linked to psychiatric conditions. We propose NeuroTree to overcome these limitations, integrating a k-hop AGE-GCN with neural ordinary differential equations (ODEs). This framework leverages an attention mechanism to optimize functional connectivity (FC), thereby enhancing dynamic FC feature learning for brain disease classification. Furthermore, NeuroTree effectively decodes fMRI network features into tree structures, which improves the capture of high-order brain regional pathway features and enables the identification of hierarchical neural behavioral patterns essential for understanding disease-related brain subnetworks. Our empirical evaluations demonstrate that NeuroTree achieves state-of-the-art performance across two distinct mental disorder datasets and provides valuable insights into age-related deterioration patterns. These findings underscore the model's efficacy in predicting psychiatric disorders and elucidating their underlying neural mechanisms.
Harnessing Vision Models for Time Series Analysis: A Survey
Feb 13, 2025



Time series analysis has witnessed the inspiring development from traditional autoregressive models, deep learning models, to recent Transformers and Large Language Models (LLMs). Efforts in leveraging vision models for time series analysis have also been made along the way but are less visible to the community due to the predominant research on sequence modeling in this domain. However, the discrepancy between continuous time series and the discrete token space of LLMs, and the challenges in explicitly modeling the correlations of variates in multivariate time series have shifted some research attentions to the equally successful Large Vision Models (LVMs) and Vision Language Models (VLMs). To fill the blank in the existing literature, this survey discusses the advantages of vision models over LLMs in time series analysis. It provides a comprehensive and in-depth overview of the existing methods, with dual views of detailed taxonomy that answer the key research questions including how to encode time series as images and how to model the imaged time series for various tasks. Additionally, we address the challenges in the pre- and post-processing steps involved in this framework and outline future directions to further advance time series analysis with vision models.