 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURENet: Combining Unified Representations for Efficient Chronic Disease Prediction
Nov 14, 2025Electronic health records (EHRs) are designed to synthesize diverse data types, including unstructured clinical notes, structured lab tests, and time-series visit data. Physicians draw on these multimodal and temporal sources of EHR data to form a comprehensive view of a patient's health, which is crucial for informed therapeutic decision-making. Yet, most predictive models fail to fully capture the interactions, redundancies, and temporal patterns across multiple data modalities, often focusing on a single data type or overlooking these complexities. In this paper, we present CURENet, a multimodal model (Combining Unified Representations for Efficient chronic disease prediction) that integrates unstructured clinical notes, lab tests, and patients' time-series data by utilizing large language models (LLMs) for clinical text processing and textual lab tests, as well as transformer encoders for longitudinal sequential visits. CURENet has been capable of capturing the intricate interaction between different forms of clinical data and creating a more reliable predictive model for chronic illnesses. We evaluated CURENet using the public MIMIC-III and private FEMH datasets, where it achieved over 94\% accuracy in predicting the top 10 chronic conditions in a multi-label framework. Our findings highlight the potential of multimodal EHR integration to enhance clinical decision-making and improve patient outcomes.
No Black Boxes: Interpretable and Interactable Predictive Healthcare with Knowledge-Enhanced Agentic Causal Discovery
May 22, 2025Deep learning models trained on extensive Electronic Health Records (EHR) data have achieved high accuracy in diagnosis prediction, offering the potential to assist clinicians in decision-making and treatment planning. However, these models lack two crucial features that clinicians highly value: interpretability and interactivity. The ``black-box'' nature of these models makes it difficult for clinicians to understand the reasoning behind predictions, limiting their ability to make informed decisions. Additionally, the absence of interactive mechanisms prevents clinicians from incorporating their own knowledge and experience into the decision-making process. To address these limitations, we propose II-KEA, a knowledge-enhanced agent-driven causal discovery framework that integrates personalized knowledge databases and agentic LLMs. II-KEA enhances interpretability through explicit reasoning and causal analysis, while also improving interactivity by allowing clinicians to inject their knowledge and experience through customized knowledge bases and prompts. II-KEA is evaluated on both MIMIC-III and MIMIC-IV, demonstrating superior performance along with enhanced interpretability and interactivity, as evidenced by its strong results from extensive case studies.
Flexible and Explainable Graph Analysis for EEG-based Alzheimer's Disease Classification
Apr 02, 2025
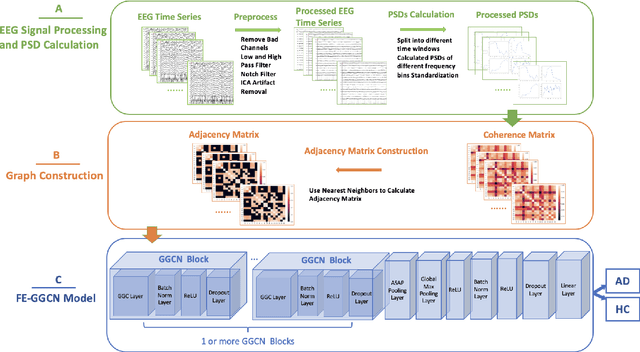
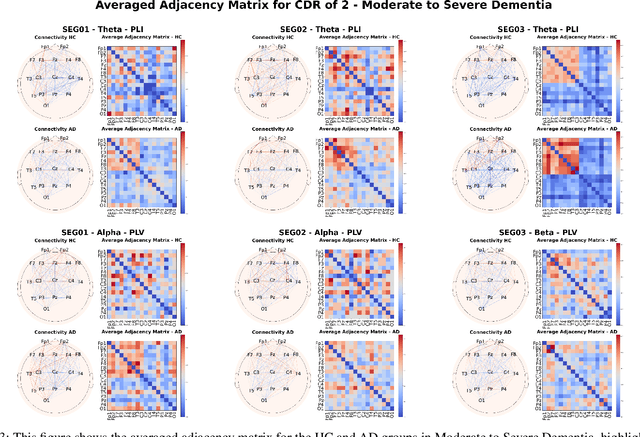
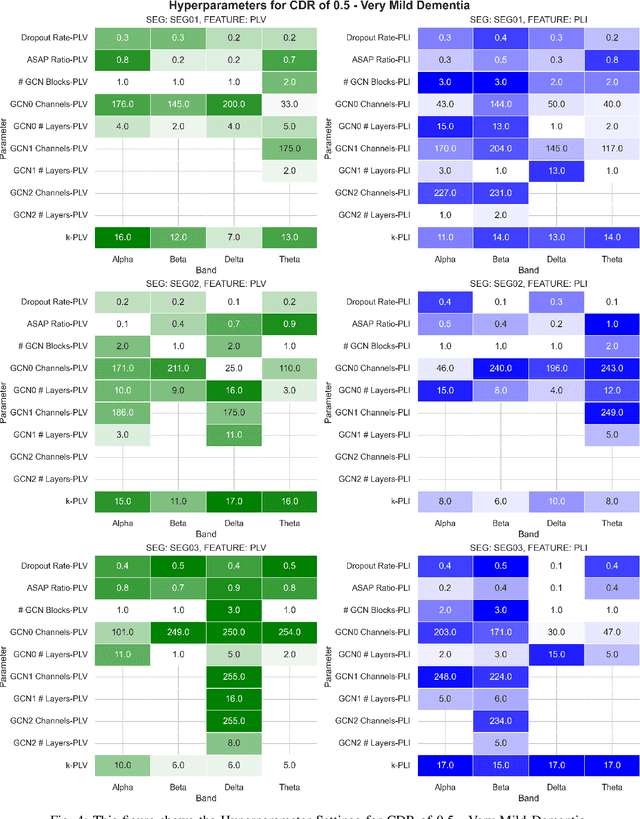
Alzheimer's Disease is a progressive neurological disorder that is one of the most common forms of dementia. It leads to a decline in memory, reasoning ability, and behavior, especially in older people. The cause of Alzheimer's Disease is still under exploration and there is no all-inclusive theory that can explain the pathologies in each individual patient. Nevertheless, early intervention has been found to be effective in managing symptoms and slowing down the disease's progression. Recent research has utilized electroencephalography (EEG) data to identify biomarkers that distinguish Alzheimer's Disease patients from healthy individuals. Prior studies have used various machine learning methods, including deep learning and graph neural networks, to examine electroencephalography-based signals for identifying Alzheimer's Disease patients. In our research, we proposed a Flexible and Explainable Gated Graph Convolutional Network (GGCN) with Multi-Objective Tree-Structured Parzen Estimator (MOTPE) hyperparameter tuning. This provides a flexible solution that efficiently identifies the optimal number of GGCN blocks to achieve the optimized precision, specificity, and recall outcomes, as well as the optimized area under the Receiver Operating Characteristic (AUC). Our findings demonstrated a high efficacy with an over 0.9 Receiver Operating Characteristic score, alongside precision, specificity, and recall scores in distinguishing health control with Alzheimer's Disease patients in Moderate to Severe Dementia using the power spectrum density (PSD) of electroencephalography signals across various frequency bands. Moreover, our research enhanced the interpretability of the embedded adjacency matrices, revealing connectivity differences in frontal and parietal brain regions between Alzheimer's patients and healthy individuals.
NeuroTree: Hierarchical Functional Brain Pathway Decoding for Mental Health Disorders
Feb 26, 2025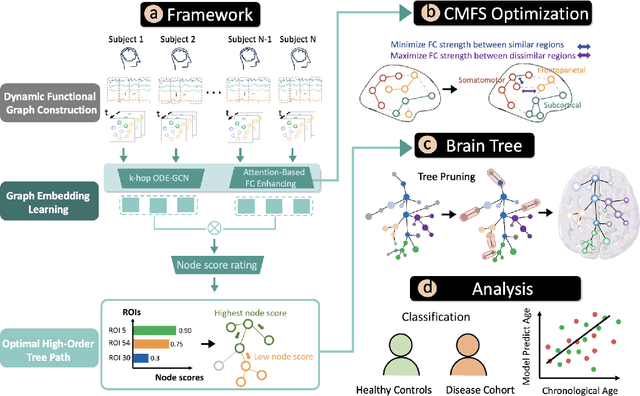
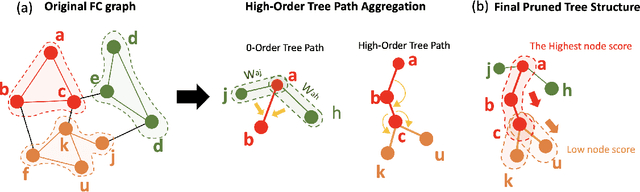
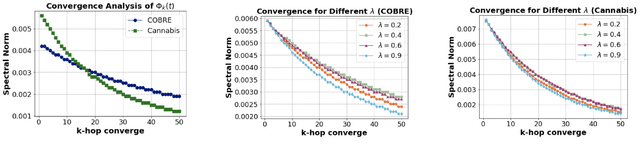
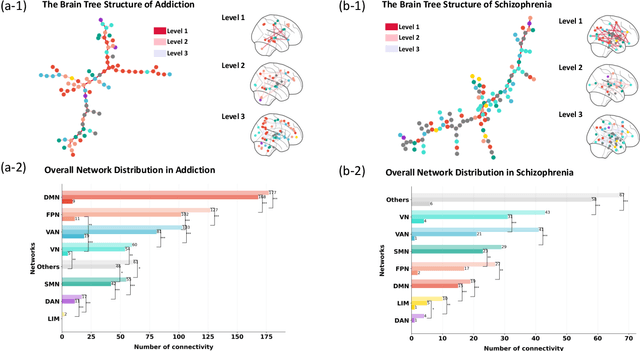
Analyzing functional brain networks using functional magnetic resonance imaging (fMRI) is crucial for understanding psychiatric disorders and addictive behaviors. While existing fMRI-based graph convolutional networks (GCNs) show considerable promise for feature extraction, they often fall short in characterizing complex relationships between brain regions and demographic factors and accounting for interpretable variables linked to psychiatric conditions. We propose NeuroTree to overcome these limitations, integrating a k-hop AGE-GCN with neural ordinary differential equations (ODEs). This framework leverages an attention mechanism to optimize functional connectivity (FC), thereby enhancing dynamic FC feature learning for brain disease classification. Furthermore, NeuroTree effectively decodes fMRI network features into tree structures, which improves the capture of high-order brain regional pathway features and enables the identification of hierarchical neural behavioral patterns essential for understanding disease-related brain subnetworks. Our empirical evaluations demonstrate that NeuroTree achieves state-of-the-art performance across two distinct mental disorder datasets and provides valuable insights into age-related deterioration patterns. These findings underscore the model's efficacy in predicting psychiatric disorders and elucidating their underlying neural mechanisms.
Multi-OphthaLingua: A Multilingual Benchmark for Assessing and Debiasing LLM Ophthalmological QA in LMICs
Dec 18, 2024



Current ophthalmology clinical workflows are plagued by over-referrals, long waits, and complex and heterogeneous medical records. Large language models (LLMs) present a promising solution to automate various procedures such as triaging, preliminary tests like visual acuity assessment, and report summaries. However, LLMs have demonstrated significantly varied performance across different languages in natural language question-answering tasks, potentially exacerbating healthcare disparities in Low and Middle-Income Countries (LMICs). This study introduces the first multilingual ophthalmological question-answering benchmark with manually curated questions parallel across languages, allowing for direct cross-lingual comparisons. Our evaluation of 6 popular LLMs across 7 different languages reveals substantial bias across different languages, highlighting risks for clinical deployment of LLMs in LMICs. Existing debiasing methods such as Translation Chain-of-Thought or Retrieval-augmented generation (RAG) by themselves fall short of closing this performance gap, often failing to improve performance across all languages and lacking specificity for the medical domain. To address this issue, We propose CLARA (Cross-Lingual Reflective Agentic system), a novel inference time de-biasing method leveraging retrieval augmented generation and self-verification. Our approach not only improves performance across all languages but also significantly reduces the multilingual bias gap, facilitating equitable LLM application across the globe.
Enhancing Multimodal Medical Image Classification using Cross-Graph Modal Contrastive Learning
Oct 23, 2024



The classification of medical images is a pivotal aspect of disease diagnosis, often enhanced by deep learning techniques. However, traditional approaches typically focus on unimodal medical image data, neglecting the integration of diverse non-image patient data. This paper proposes a novel Cross-Graph Modal Contrastive Learning (CGMCL) framework for multimodal medical image classification. The model effectively integrates both image and non-image data by constructing cross-modality graphs and leveraging contrastive learning to align multimodal features in a shared latent space. An inter-modality feature scaling module further optimizes the representation learning process by reducing the gap between heterogeneous modalities. The proposed approach is evaluated on two datasets: a Parkinson's disease (PD) dataset and a public melanoma dataset. Results demonstrate that CGMCL outperforms conventional unimodal methods in accuracy, interpretability, and early disease prediction. Additionally, the method shows superior performance in multi-class melanoma classification. The CGMCL framework provides valuable insights into medical image classification while offering improved disease interpretability and predictive capabilities.
MEDFuse: Multimodal EHR Data Fusion with Masked Lab-Test Modeling and Large Language Models
Jul 17, 2024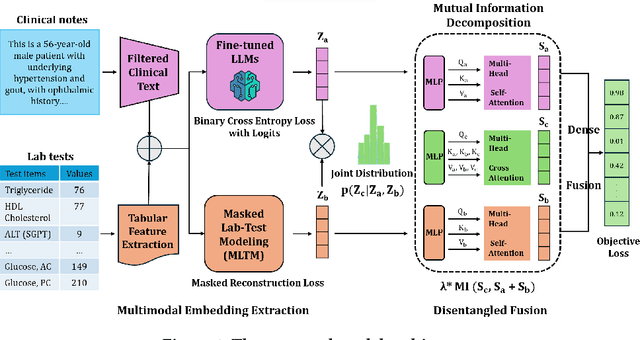
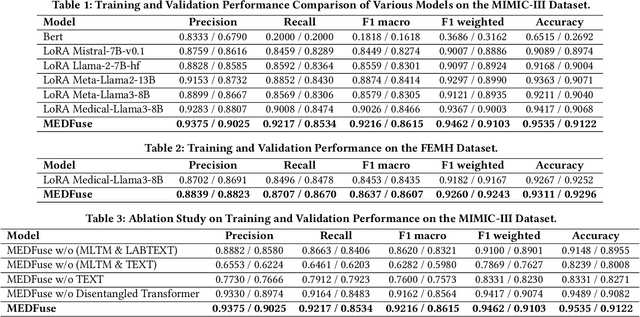
Electronic health records (EHRs) are multimodal by nature, consisting of structured tabular features like lab tests and unstructured clinical notes. In real-life clinical practice, doctors use complementary multimodal EHR data sources to get a clearer picture of patients' health and support clinical decision-making. However, most EHR predictive models do not reflect these procedures, as they either focus on a single modality or overlook the inter-modality interactions/redundancy. In this work, we propose MEDFuse, a Multimodal EHR Data Fusion framework that incorporates masked lab-test modeling and large language models (LLMs) to effectively integrate structured and unstructured medical data. MEDFuse leverages multimodal embeddings extracted from two sources: LLMs fine-tuned on free clinical text and masked tabular transformers trained on structured lab test results. We design a disentangled transformer module, optimized by a mutual information loss to 1) decouple modality-specific and modality-shared information and 2) extract useful joint representation from the noise and redundancy present in clinical notes. Through comprehensive validation on the public MIMIC-III dataset and the in-house FEMH dataset, MEDFuse demonstrates great potential in advancing clinical predictions, achieving over 90% F1 score in the 10-disease multi-label classification task.
EHR-Based Mobile and Web Platform for Chronic Disease Risk Prediction Using Large Language Multimodal Models
Jun 26, 2024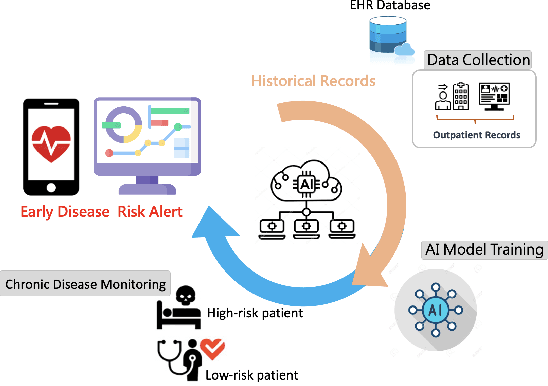
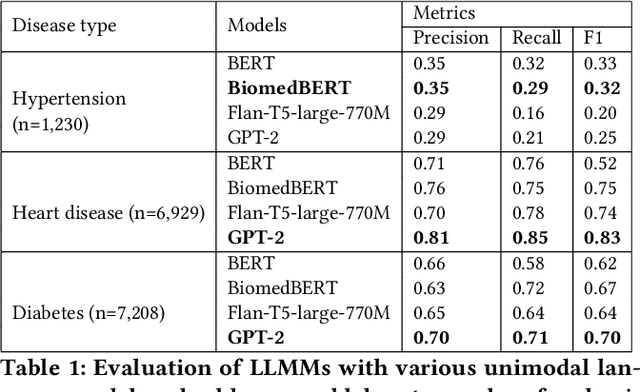
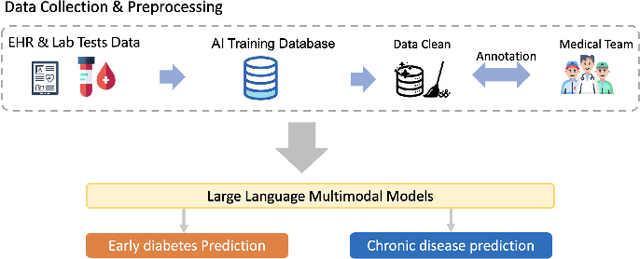
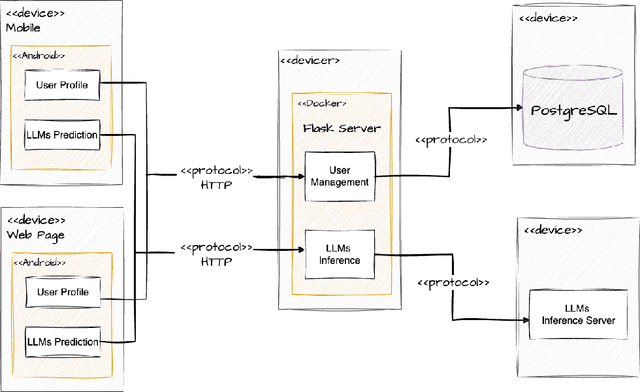
Traditional diagnosis of chronic diseases involves in-person consultations with physicians to identify the disease. However, there is a lack of research focused on predicting and developing application systems using clinical notes and blood test values. We collected five years of Electronic Health Records (EHRs) from Taiwan's hospital database between 2017 and 2021 as an AI database. Furthermore, we developed an EHR-based chronic disease prediction platform utilizing Large Language Multimodal Models (LLMMs), successfully integrating with frontend web and mobile applications for prediction. This prediction platform can also connect to the hospital's backend database, providing physicians with real-time risk assessment diagnostics. The demonstration link can be found at https://www.youtube.com/watch?v=oqmL9DEDFgA.
Identification of Craving Maps among Marijuana Users via Analysis of Functional Brain Networks with High-Order Attention Graph Neural Networks
Mar 04, 2024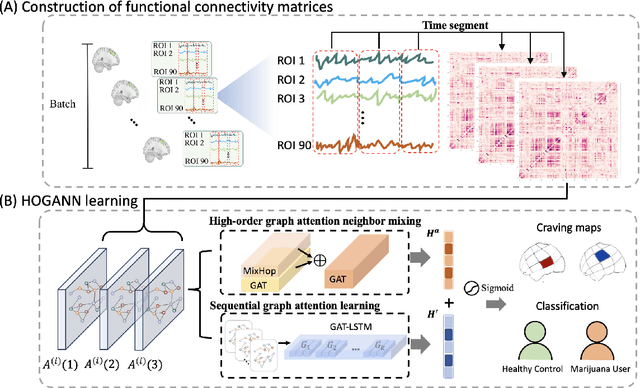
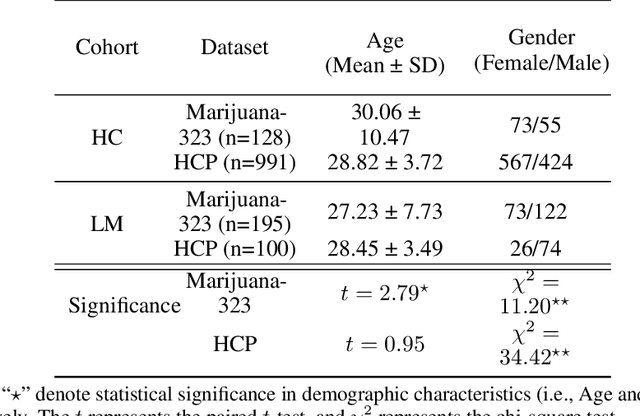
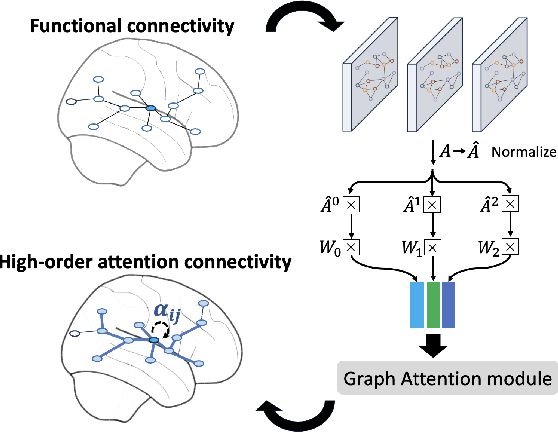
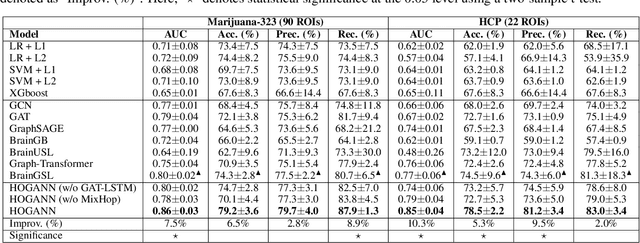
The consumption of high doses of marijuana can have significant psychological and social impacts. In this study, we propose an interpretable novel framework called the HOGAB (High-Order Graph Attention Neural Networks) model for addictive Marijuana classification and analysis of the localized network clusters that demonstrated abnormal brain activities among chronic marijuana users. The HOGAB integrates dynamic intrinsic functional networks with LSTM technology to capture temporal patterns in fMRI time series of marijuana users. We employed the high-order attention module in neighborhood nodes for information fusion and message passing, enhancing community clustering analysis for long-term marijuana users. Furthermore, we improve the overall classification ability of the model by incorporating attention mechanisms, achieving an AUC of 85.1% and an accuracy of 80.7% in classification, higher than the comparison algoirthms. Specifically, we identified the most relevant subnetworks and cognitive regions that are influenced by persistent marijuana usage, revealing that chronic marijuana consumption adversely affects cognitive control, particularly within the Dorsal Attention and Frontoparietal networks, which are essential for attentional, cognitive and higher cognitive functions. The results show that our proposed model is capable of accurately predicting craving bahavior and identifying brain maps associated with long-term cravings, and thus pinpointing brain regions that are important for analysis.
Large Language Multimodal Models for 5-Year Chronic Disease Cohort Prediction Using EHR Data
Mar 02, 2024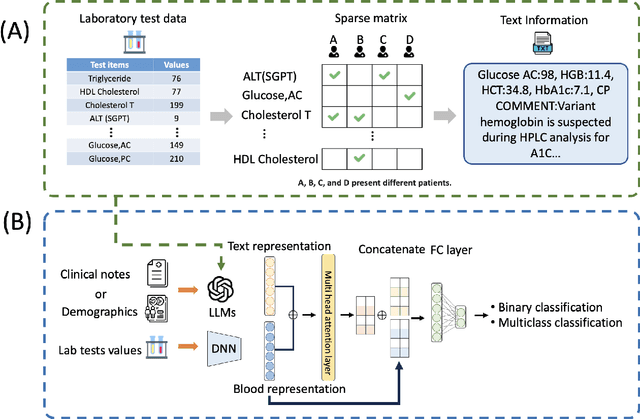
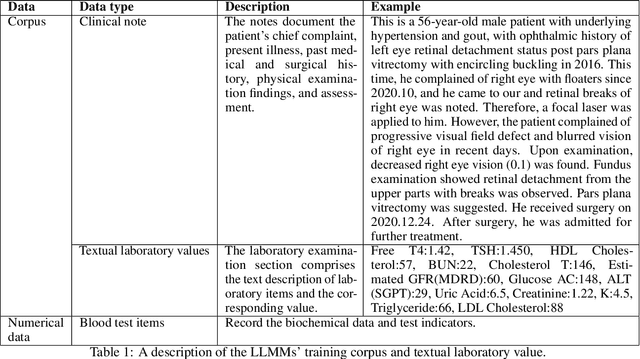

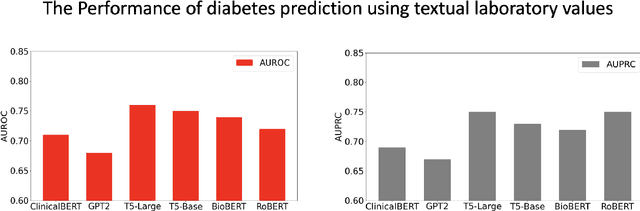
Chronic diseases such as diabetes are the leading causes of morbidity and mortality worldwide. Numerous research studies have been attempted with various deep learning models in diagnosis. However, most previous studies had certain limitations, including using publicly available datasets (e.g. MIMIC), and imbalanced data. In this study, we collected five-year electronic health records (EHRs) from the Taiwan hospital database, including 1,420,596 clinical notes, 387,392 laboratory test results, and more than 1,505 laboratory test items, focusing on research pre-training large language models. We proposed a novel Large Language Multimodal Models (LLMMs) framework incorporating multimodal data from clinical notes and laboratory test results for the prediction of chronic disease risk. Our method combined a text embedding encoder and multi-head attention layer to learn laboratory test values, utilizing a deep neural network (DNN) module to merge blood features with chronic disease semantics into a latent space. In our experiments, we observe that clinicalBERT and PubMed-BERT, when combined with attention fusion, can achieve an accuracy of 73% in multiclass chronic diseases and diabetes prediction. By transforming laboratory test values into textual descriptions and employing the Flan T-5 model, we achieved a 76% Area Under the ROC Curve (AUROC), demonstrating the effectiveness of leveraging numerical text data for training and inference in language models. This approach significantly improves the accuracy of early-stage diabetes prediction.