 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCS: Controllable and Constrained Sampling with Diffusion Models via Initial Noise Perturbation
Feb 07, 2025



Diffusion models have emerged as powerful tools for generative tasks, producing high-quality outputs across diverse domains. However, how the generated data responds to the initial noise perturbation in diffusion models remains under-explored, which hinders understanding the controllability of the sampling process. In this work, we first observe an interesting phenomenon: the relationship between the change of generation outputs and the scale of initial noise perturbation is highly linear through the diffusion ODE sampling. Then we provide both theoretical and empirical study to justify this linearity property of this input-output (noise-generation data) relationship. Inspired by these new insights, we propose a novel Controllable and Constrained Sampling method (CCS) together with a new controller algorithm for diffusion models to sample with desired statistical properties while preserving good sample quality. We perform extensive experiments to compare our proposed sampling approach with other methods on both sampling controllability and sampled data quality. Results show that our CCS method achieves more precisely controlled sampling while maintaining superior sample quality and diversity.
Multi-OphthaLingua: A Multilingual Benchmark for Assessing and Debiasing LLM Ophthalmological QA in LMICs
Dec 18, 2024



Current ophthalmology clinical workflows are plagued by over-referrals, long waits, and complex and heterogeneous medical records. Large language models (LLMs) present a promising solution to automate various procedures such as triaging, preliminary tests like visual acuity assessment, and report summaries. However, LLMs have demonstrated significantly varied performance across different languages in natural language question-answering tasks, potentially exacerbating healthcare disparities in Low and Middle-Income Countries (LMICs). This study introduces the first multilingual ophthalmological question-answering benchmark with manually curated questions parallel across languages, allowing for direct cross-lingual comparisons. Our evaluation of 6 popular LLMs across 7 different languages reveals substantial bias across different languages, highlighting risks for clinical deployment of LLMs in LMICs. Existing debiasing methods such as Translation Chain-of-Thought or Retrieval-augmented generation (RAG) by themselves fall short of closing this performance gap, often failing to improve performance across all languages and lacking specificity for the medical domain. To address this issue, We propose CLARA (Cross-Lingual Reflective Agentic system), a novel inference time de-biasing method leveraging retrieval augmented generation and self-verification. Our approach not only improves performance across all languages but also significantly reduces the multilingual bias gap, facilitating equitable LLM application across the globe.
Latent Space Disentanglement in Diffusion Transformers Enables Zero-shot Fine-grained Semantic Editing
Aug 23, 2024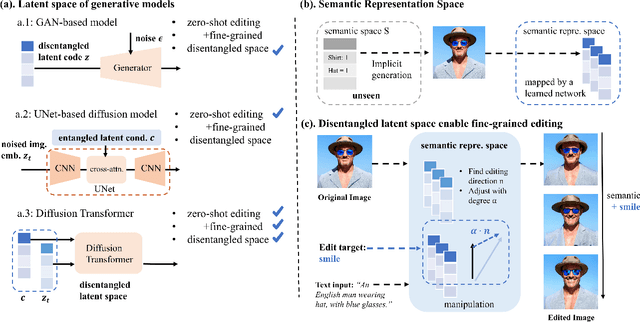

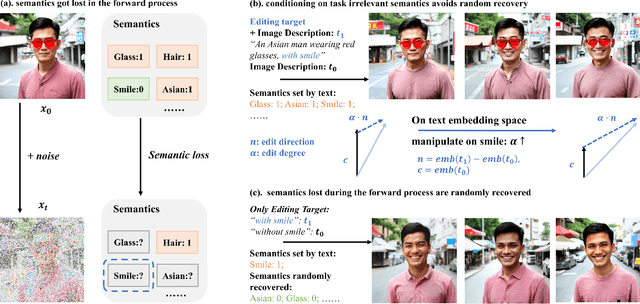

Diffusion Transformers (DiTs) have achieved remarkable success in diverse and high-quality text-to-image(T2I) generation. However, how text and image latents individually and jointly contribute to the semantics of generated images, remain largely unexplored. Through our investigation of DiT's latent space, we have uncovered key findings that unlock the potential for zero-shot fine-grained semantic editing: (1) Both the text and image spaces in DiTs are inherently decomposable. (2) These spaces collectively form a disentangled semantic representation space, enabling precise and fine-grained semantic control. (3) Effective image editing requires the combined use of both text and image latent spaces. Leveraging these insights, we propose a simple and effective Extract-Manipulate-Sample (EMS) framework for zero-shot fine-grained image editing. Our approach first utilizes a multi-modal Large Language Model to convert input images and editing targets into text descriptions. We then linearly manipulate text embeddings based on the desired editing degree and employ constrained score distillation sampling to manipulate image embeddings. We quantify the disentanglement degree of the latent space of diffusion models by proposing a new metric. To evaluate fine-grained editing performance, we introduce a comprehensive benchmark incorporating both human annotations, manual evaluation, and automatic metrics. We have conducted extensive experimental results and in-depth analysis to thoroughly uncover the semantic disentanglement properties of the diffusion transformer, as well as the effectiveness of our proposed method. Our annotated benchmark dataset is publicly available at https://anonymous.com/anonymous/EMS-Benchmark, facilitating reproducible research in this domain.