 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCS: Controllable and Constrained Sampling with Diffusion Models via Initial Noise Perturbation
Feb 07, 2025



Diffusion models have emerged as powerful tools for generative tasks, producing high-quality outputs across diverse domains. However, how the generated data responds to the initial noise perturbation in diffusion models remains under-explored, which hinders understanding the controllability of the sampling process. In this work, we first observe an interesting phenomenon: the relationship between the change of generation outputs and the scale of initial noise perturbation is highly linear through the diffusion ODE sampling. Then we provide both theoretical and empirical study to justify this linearity property of this input-output (noise-generation data) relationship. Inspired by these new insights, we propose a novel Controllable and Constrained Sampling method (CCS) together with a new controller algorithm for diffusion models to sample with desired statistical properties while preserving good sample quality. We perform extensive experiments to compare our proposed sampling approach with other methods on both sampling controllability and sampled data quality. Results show that our CCS method achieves more precisely controlled sampling while maintaining superior sample quality and diversity.
DiffusionBlend: Learning 3D Image Prior through Position-aware Diffusion Score Blending for 3D Computed Tomography Reconstruction
Jun 14, 2024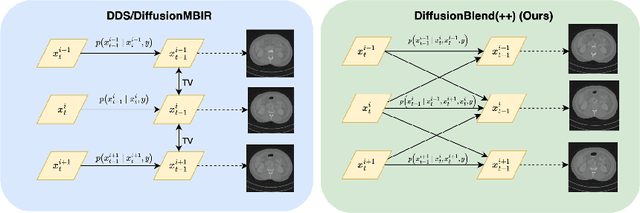
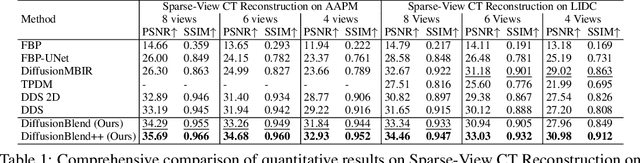
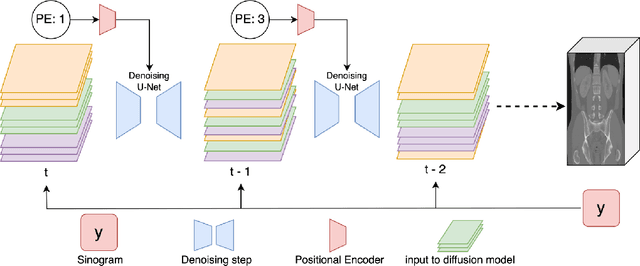
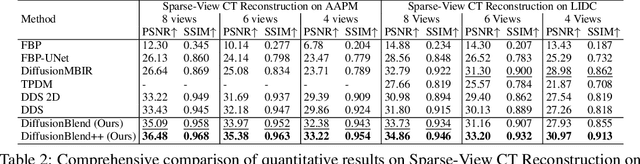
Diffusion models face significant challenges when employed for large-scale medical image reconstruction in real practice such as 3D Computed Tomography (CT). Due to the demanding memory, time, and data requirements, it is difficult to train a diffusion model directly on the entire volume of high-dimensional data to obtain an efficient 3D diffusion prior. Existing works utilizing diffusion priors on single 2D image slice with hand-crafted cross-slice regularization would sacrifice the z-axis consistency, which results in severe artifacts along the z-axis. In this work, we propose a novel framework that enables learning the 3D image prior through position-aware 3D-patch diffusion score blending for reconstructing large-scale 3D medical images. To the best of our knowledge, we are the first to utilize a 3D-patch diffusion prior for 3D medical image reconstruction. Extensive experiments on sparse view and limited angle CT reconstruction show that our DiffusionBlend method significantly outperforms previous methods and achieves state-of-the-art performance on real-world CT reconstruction problems with high-dimensional 3D image (i.e., $256 \times 256 \times 500$). Our algorithm also comes with better or comparable computational efficiency than previous state-of-the-art methods.
SatDiffMoE: A Mixture of Estimation Method for Satellite Image Super-resolution with Latent Diffusion Models
Jun 14, 2024



During the acquisition of satellite images, there is generally a trade-off between spatial resolution and temporal resolution (acquisition frequency) due to the onboard sensors of satellite imaging systems. High-resolution satellite images are very important for land crop monitoring, urban planning, wildfire management and a variety of applications. It is a significant yet challenging task to achieve high spatial-temporal resolution in satellite imaging. With the advent of diffusion models, we can now learn strong generative priors to generate realistic satellite images with high resolution, which can be utilized to promote the super-resolution task as well. In this work, we propose a novel diffusion-based fusion algorithm called \textbf{SatDiffMoE} that can take an arbitrary number of sequential low-resolution satellite images at the same location as inputs, and fuse them into one high-resolution reconstructed image with more fine details, by leveraging and fusing the complementary information from different time points. Our algorithm is highly flexible and allows training and inference on arbitrary number of low-resolution images. Experimental results show that our proposed SatDiffMoE method not only achieves superior performance for the satellite image super-resolution tasks on a variety of datasets, but also gets an improved computational efficiency with reduced model parameters, compared with previous methods.