 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCLR: Improving Conditional Modeling in Visual Generative Models via Inter-Class Likelihood-Ratio Maximization and Establishing the Equivalence between Classifier-Free Guidance and Alignment Objectives
Mar 23, 2026Diffusion models have achieved state-of-the-art performance in generative modeling, but their success often relies heavily on classifier-free guidance (CFG), an inference-time heuristic that modifies the sampling trajectory. From a theoretical perspective, diffusion models trained with standard denoising score matching (DSM) are expected to recover the target data distribution, raising the question of why inference-time guidance is necessary in practice. In this work, we ask whether the DSM training objective can be modified in a principled manner such that standard reverse-time sampling, without inference-time guidance, yields effects comparable to CFG. We identify insufficient inter-class separation as a key limitation of standard diffusion models. To address this, we propose MCLR, a principled alignment objective that explicitly maximizes inter-class likelihood-ratios during training. Models fine-tuned with MCLR exhibit CFG-like improvements under standard sampling, achieving comparable qualitative and quantitative gains without requiring inference-time guidance. Beyond empirical benefits, we provide a theoretical result showing that the CFG-guided score is exactly the optimal solution to a weighted MCLR objective. This establishes a formal equivalence between classifier-free guidance and alignment-based objectives, offering a mechanistic interpretation of CFG.
Comparing Implicit Neural Representations and B-Splines for Continuous Function Fitting from Sparse Samples
Feb 25, 2026Continuous signal representations are naturally suited for inverse problems, such as magnetic resonance imaging (MRI) and computed tomography, because the measurements depend on an underlying physically continuous signal. While classical methods rely on predefined analytical bases like B-splines, implicit neural representations (INRs) have emerged as a powerful alternative that use coordinate-based networks to parameterize continuous functions with implicitly defined bases. Despite their empirical success, direct comparisons of their intrinsic representation capabilities with conventional models remain limited. This preliminary empirical study compares a positional-encoded INR with a cubic B-spline model for continuous function fitting from sparse random samples, isolating the representation capacity difference by only using coefficient-domain Tikhonov regularization. Results demonstrate that, under oracle hyperparameter selection, the INR achieves a lower normalized root-mean-squared error, yielding sharper edge transitions and fewer oscillatory artifacts than the oracle-tuned B-spline model. Additionally, we show that a practical bilevel optimization framework for INR hyperparameter selection based on measurement data split effectively approximates oracle performance. These findings empirically support the superior representation capacity of INRs for sparse data fitting.
Scan-Adaptive Dynamic MRI Undersampling Using a Dictionary of Efficiently Learned Patterns
Feb 17, 2026Cardiac MRI is limited by long acquisition times, which can lead to patient discomfort and motion artifacts. We aim to accelerate Cartesian dynamic cardiac MRI by learning efficient, scan-adaptive undersampling patterns that preserve diagnostic image quality. We develop a learning-based framework for designing scan- or slice-adaptive Cartesian undersampling masks tailored to dynamic cardiac MRI. Undersampling patterns are optimized using fully sampled training dynamic time-series data. At inference time, a nearest-neighbor search in low-frequency $k$-space selects an optimized mask from a dictionary of learned patterns. Our learned sampling approach improves reconstruction quality across multiple acceleration factors on public and in-house cardiac MRI datasets, including PSNR gains of 2-3 dB, reduced NMSE, improved SSIM, and higher radiologist ratings. The proposed scan-adaptive sampling framework enables faster and higher-quality dynamic cardiac MRI by adapting $k$-space sampling to individual scans.
Local Patches Meet Global Context: Scalable 3D Diffusion Priors for Computed Tomography Reconstruction
Dec 20, 2025



Diffusion models learn strong image priors that can be leveraged to solve inverse problems like medical image reconstruction. However, for real-world applications such as 3D Computed Tomography (CT) imaging, directly training diffusion models on 3D data presents significant challenges due to the high computational demands of extensive GPU resources and large-scale datasets. Existing works mostly reuse 2D diffusion priors to address 3D inverse problems, but fail to fully realize and leverage the generative capacity of diffusion models for high-dimensional data. In this study, we propose a novel 3D patch-based diffusion model that can learn a fully 3D diffusion prior from limited data, enabling scalable generation of high-resolution 3D images. Our core idea is to learn the prior of 3D patches to achieve scalable efficiency, while coupling local and global information to guarantee high-quality 3D image generation, by modeling the joint distribution of position-aware 3D local patches and downsampled 3D volume as global context. Our approach not only enables high-quality 3D generation, but also offers an unprecedentedly efficient and accurate solution to high-resolution 3D inverse problems. Experiments on 3D CT reconstruction across multiple datasets show that our method outperforms state-of-the-art methods in both performance and efficiency, notably achieving high-resolution 3D reconstruction of $512 \times 512 \times 256$ ($\sim$20 mins).
ALPCAH: Subspace Learning for Sample-wise Heteroscedastic Data
May 12, 2025Principal component analysis (PCA) is a key tool in the field of data dimensionality reduction. However, some applications involve heterogeneous data that vary in quality due to noise characteristics associated with each data sample. Heteroscedastic methods aim to deal with such mixed data quality. This paper develops a subspace learning method, named ALPCAH, that can estimate the sample-wise noise variances and use this information to improve the estimate of the subspace basis associated with the low-rank structure of the data. Our method makes no distributional assumptions of the low-rank component and does not assume that the noise variances are known. Further, this method uses a soft rank constraint that does not require subspace dimension to be known. Additionally, this paper develops a matrix factorized version of ALPCAH, named LR-ALPCAH, that is much faster and more memory efficient at the cost of requiring subspace dimension to be known or estimated. Simulations and real data experiments show the effectiveness of accounting for data heteroscedasticity compared to existing algorithms. Code available at https://github.com/javiersc1/ALPCAH.
Smooth optimization algorithms for global and locally low-rank regularizers
May 09, 2025Many inverse problems and signal processing problems involve low-rank regularizers based on the nuclear norm. Commonly, proximal gradient methods (PGM) are adopted to solve this type of non-smooth problems as they can offer fast and guaranteed convergence. However, PGM methods cannot be simply applied in settings where low-rank models are imposed locally on overlapping patches; therefore, heuristic approaches have been proposed that lack convergence guarantees. In this work we propose to replace the nuclear norm with a smooth approximation in which a Huber-type function is applied to each singular value. By providing a theoretical framework based on singular value function theory, we show that important properties can be established for the proposed regularizer, such as: convexity, differentiability, and Lipschitz continuity of the gradient. Moreover, we provide a closed-form expression for the regularizer gradient, enabling the use of standard iterative gradient-based optimization algorithms (e.g., nonlinear conjugate gradient) that can easily address the case of overlapping patches and have well-known convergence guarantees. In addition, we provide a novel step-size selection strategy based on a quadratic majorizer of the line-search function that leverages the Huber characteristics of the proposed regularizer. Finally, we assess the proposed optimization framework by providing empirical results in dynamic magnetic resonance imaging (MRI) reconstruction in the context of locally low-rank models with overlapping patches.
Convergent Complex Quasi-Newton Proximal Methods for Gradient-Driven Denoisers in Compressed Sensing MRI Reconstruction
May 07, 2025


In compressed sensing (CS) MRI, model-based methods are pivotal to achieving accurate reconstruction. One of the main challenges in model-based methods is finding an effective prior to describe the statistical distribution of the target image. Plug-and-Play (PnP) and REgularization by Denoising (RED) are two general frameworks that use denoisers as the prior. While PnP/RED methods with convolutional neural networks (CNNs) based denoisers outperform classical hand-crafted priors in CS MRI, their convergence theory relies on assumptions that do not hold for practical CNNs. The recently developed gradient-driven denoisers offer a framework that bridges the gap between practical performance and theoretical guarantees. However, the numerical solvers for the associated minimization problem remain slow for CS MRI reconstruction. This paper proposes a complex quasi-Newton proximal method that achieves faster convergence than existing approaches. To address the complex domain in CS MRI, we propose a modified Hessian estimation method that guarantees Hermitian positive definiteness. Furthermore, we provide a rigorous convergence analysis of the proposed method for nonconvex settings. Numerical experiments on both Cartesian and non-Cartesian sampling trajectories demonstrate the effectiveness and efficiency of our approach.
Bilevel Optimized Implicit Neural Representation for Scan-Specific Accelerated MRI Reconstruction
Feb 28, 2025Deep Learning (DL) methods can reconstruct highly accelerated magnetic resonance imaging (MRI) scans, but they rely on application-specific large training datasets and often generalize poorly to out-of-distribution data. Self-supervised deep learning algorithms perform scan-specific reconstructions, but still require complicated hyperparameter tuning based on the acquisition and often offer limited acceleration. This work develops a bilevel-optimized implicit neural representation (INR) approach for scan-specific MRI reconstruction. The method automatically optimizes the hyperparameters for a given acquisition protocol, enabling a tailored reconstruction without training data. The proposed algorithm uses Gaussian process regression to optimize INR hyperparameters, accommodating various acquisitions. The INR includes a trainable positional encoder for high-dimensional feature embedding and a small multilayer perceptron for decoding. The bilevel optimization is computationally efficient, requiring only a few minutes per typical 2D Cartesian scan. On scanner hardware, the subsequent scan-specific reconstruction-using offline-optimized hyperparameters-is completed within seconds and achieves improved image quality compared to previous model-based and self-supervised learning methods.
On Adapting Randomized Nyström Preconditioners to Accelerate Variational Image Reconstruction
Nov 12, 2024
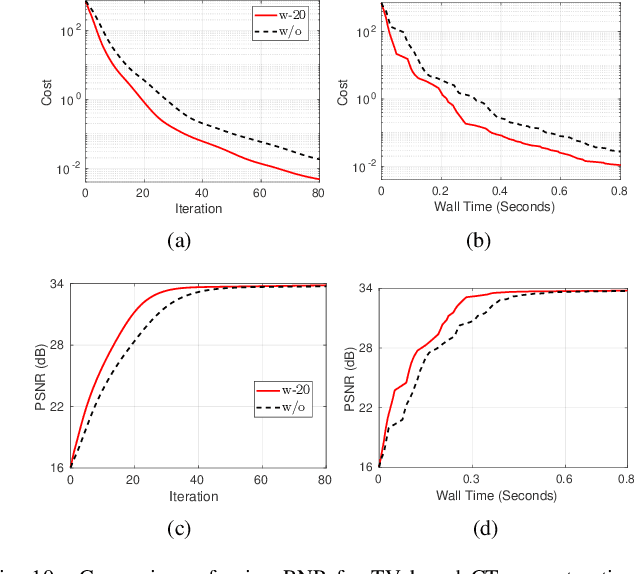
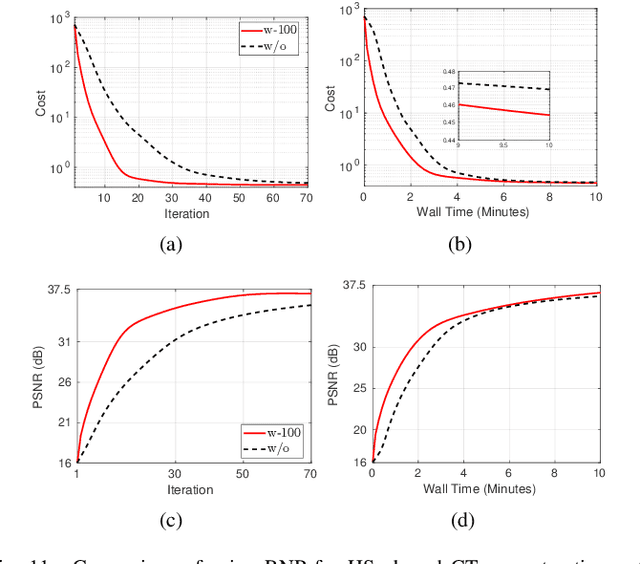
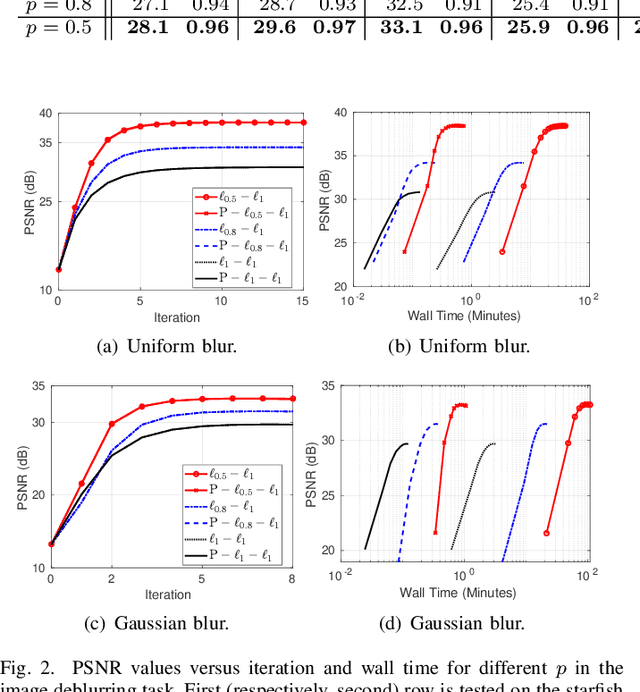
Model-based iterative reconstruction plays a key role in solving inverse problems. However, the associated minimization problems are generally large-scale, ill-posed, nonsmooth, and sometimes even nonconvex, which present challenges in designing efficient iterative solvers and often prevent their practical use. Preconditioning methods can significantly accelerate the convergence of iterative methods. In some applications, computing preconditioners on-the-fly is beneficial. Moreover, forward models in image reconstruction are typically represented as operators, and the corresponding explicit matrices are often unavailable, which brings additional challenges in designing preconditioners. Therefore, for practical use, computing and applying preconditioners should be computationally inexpensive. This paper adapts the randomized Nystr\"{o}m approximation to compute effective preconditioners that accelerate image reconstruction without requiring an explicit matrix for the forward model. We leverage modern GPU computational platforms to compute the preconditioner on-the-fly. Moreover, we propose efficient approaches for applying the preconditioner to problems with nonsmooth regularizers. Our numerical results on image deblurring, super-resolution with impulsive noise, and computed tomography reconstruction demonstrate the efficiency and effectiveness of the proposed preconditioner.
Patch-Based Diffusion Models Beat Whole-Image Models for Mismatched Distribution Inverse Problems
Oct 15, 2024



Diffusion models have achieved excellent success in solving inverse problems due to their ability to learn strong image priors, but existing approaches require a large training dataset of images that should come from the same distribution as the test dataset. When the training and test distributions are mismatched, artifacts and hallucinations can occur in reconstructed images due to the incorrect priors. In this work, we systematically study out of distribution (OOD) problems where a known training distribution is first provided. We first study the setting where only a single measurement obtained from the unknown test distribution is available. Next we study the setting where a very small sample of data belonging to the test distribution is available, and our goal is still to reconstruct an image from a measurement that came from the test distribution. In both settings, we use a patch-based diffusion prior that learns the image distribution solely from patches. Furthermore, in the first setting, we include a self-supervised loss that helps the network output maintain consistency with the measurement. Extensive experiments show that in both settings, the patch-based method can obtain high quality image reconstructions that can outperform whole-image models and can compete with methods that have access to large in-distribution training datasets. Furthermore, we show how whole-image models are prone to memorization and overfitting, leading to artifacts in the reconstructions, while a patch-based model can resolve these issues.