 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Brain Age Estimation with a Multimodal 3D CNN Approach Combining Structural MRI and AI-Synthesized Cerebral Blood Volume Data
Dec 01, 2024



The growing global aging population necessitates enhanced methods for assessing brain aging and related neurodegenerative changes. Brain Age Gap Estimation (BrainAGE) offers a neuroimaging biomarker for understanding these changes by predicting brain age from MRI scans. Current approaches primarily use T1-weighted magnetic resonance imaging (T1w MRI) data, capturing only structural brain information. To address the lack of functional data, we integrated AI-generated Cerebral Blood Volume (AICBV) with T1w MRI, combining both structural and functional metrics. We developed a deep learning model using a VGG-based architecture to predict brain age. Our model achieved a mean absolute error (MAE) of 3.95 years and a correlation of \(R^2 = 0.94\) on the test set (\(n = 288\)), outperforming existing models trained on similar data. We have further created gradient-based class activation maps (Grad-CAM) to visualize the regions of the brain that most influenced the model's predictions, providing interpretable insights into the structural and functional contributors to brain aging.
Advancing Efficient Brain Tumor Multi-Class Classification -- New Insights from the Vision Mamba Model in Transfer Learning
Oct 29, 2024



Early and accurate diagnosis of brain tumors is crucial for improving patient survival rates. However, the detection and classification of brain tumors are challenging due to their diverse types and complex morphological characteristics. This study investigates the application of pre-trained models for brain tumor classification, with a particular focus on deploying the Mamba model. We fine-tuned several mainstream transfer learning models and applied them to the multi-class classification of brain tumors. By comparing these models to those trained from scratch, we demonstrated the significant advantages of transfer learning, especially in the medical imaging field, where annotated data is often limited. Notably, we introduced the Vision Mamba (Vim), a novel network architecture, and applied it for the first time in brain tumor classification, achieving exceptional classification accuracy. Experimental results indicate that the Vim model achieved 100% classification accuracy on an independent test set, emphasizing its potential for tumor classification tasks. These findings underscore the effectiveness of transfer learning in brain tumor classification and reveal that, compared to existing state-of-the-art models, the Vim model is lightweight, efficient, and highly accurate, offering a new perspective for clinical applications. Furthermore, the framework proposed in this study for brain tumor classification, based on transfer learning and the Vision Mamba model, is broadly applicable to other medical imaging classification problems.
Shorter SPECT Scans Using Self-supervised Coordinate Learning to Synthesize Skipped Projection Views
Jun 27, 2024



Purpose: This study addresses the challenge of extended SPECT imaging duration under low-count conditions, as encountered in Lu-177 SPECT imaging, by developing a self-supervised learning approach to synthesize skipped SPECT projection views, thus shortening scan times in clinical settings. Methods: We employed a self-supervised coordinate-based learning technique, adapting the neural radiance field (NeRF) concept in computer vision to synthesize under-sampled SPECT projection views. For each single scan, we used self-supervised coordinate learning to estimate skipped SPECT projection views. The method was tested with various down-sampling factors (DFs=2, 4, 8) on both Lu-177 phantom SPECT/CT measurements and clinical SPECT/CT datasets, from 11 patients undergoing Lu-177 DOTATATE and 6 patients undergoing Lu-177 PSMA-617 radiopharmaceutical therapy. Results: For SPECT reconstructions, our method outperformed the use of linearly interpolated projections and partial projection views in relative contrast-to-noise-ratios (RCNR) averaged across different downsampling factors: 1) DOTATATE: 83% vs. 65% vs. 67% for lesions and 86% vs. 70% vs. 67% for kidney, 2) PSMA: 76% vs. 69% vs. 68% for lesions and 75% vs. 55% vs. 66% for organs, including kidneys, lacrimal glands, parotid glands, and submandibular glands. Conclusion: The proposed method enables reduction in acquisition time (by factors of 2, 4, or 8) while maintaining quantitative accuracy in clinical SPECT protocols by allowing for the collection of fewer projections. Importantly, the self-supervised nature of this NeRF-based approach eliminates the need for extensive training data, instead learning from each patient's projection data alone. The reduction in acquisition time is particularly relevant for imaging under low-count conditions and for protocols that require multiple-bed positions such as whole-body imaging.
Robotic Scene Segmentation with Memory Network for Runtime Surgical Context Inference
Aug 24, 2023Surgical context inference has recently garnered significant attention in robot-assisted surgery as it can facilitate workflow analysis, skill assessment, and error detection. However, runtime context inference is challenging since it requires timely and accurate detection of the interactions among the tools and objects in the surgical scene based on the segmentation of video data. On the other hand, existing state-of-the-art video segmentation methods are often biased against infrequent classes and fail to provide temporal consistency for segmented masks. This can negatively impact the context inference and accurate detection of critical states. In this study, we propose a solution to these challenges using a Space Time Correspondence Network (STCN). STCN is a memory network that performs binary segmentation and minimizes the effects of class imbalance. The use of a memory bank in STCN allows for the utilization of past image and segmentation information, thereby ensuring consistency of the masks. Our experiments using the publicly available JIGSAWS dataset demonstrate that STCN achieves superior segmentation performance for objects that are difficult to segment, such as needle and thread, and improves context inference compared to the state-of-the-art. We also demonstrate that segmentation and context inference can be performed at runtime without compromising performance.
Evaluating the Task Generalization of Temporal Convolutional Networks for Surgical Gesture and Motion Recognition using Kinematic Data
Jun 28, 2023



Fine-grained activity recognition enables explainable analysis of procedures for skill assessment, autonomy, and error detection in robot-assisted surgery. However, existing recognition models suffer from the limited availability of annotated datasets with both kinematic and video data and an inability to generalize to unseen subjects and tasks. Kinematic data from the surgical robot is particularly critical for safety monitoring and autonomy, as it is unaffected by common camera issues such as occlusions and lens contamination. We leverage an aggregated dataset of six dry-lab surgical tasks from a total of 28 subjects to train activity recognition models at the gesture and motion primitive (MP) levels and for separate robotic arms using only kinematic data. The models are evaluated using the LOUO (Leave-One-User-Out) and our proposed LOTO (Leave-One-Task-Out) cross validation methods to assess their ability to generalize to unseen users and tasks respectively. Gesture recognition models achieve higher accuracies and edit scores than MP recognition models. But, using MPs enables the training of models that can generalize better to unseen tasks. Also, higher MP recognition accuracy can be achieved by training separate models for the left and right robot arms. For task-generalization, MP recognition models perform best if trained on similar tasks and/or tasks from the same dataset.
AWFSD: Accelerated Wirtinger Flow with Score-based Diffusion Image Prior for Poisson-Gaussian Holographic Phase Retrieval
May 12, 2023



Phase retrieval (PR) is an essential problem in a number of coherent imaging systems. This work aims at resolving the holographic phase retrieval problem in real world scenarios where the measurements are corrupted by a mixture of Poisson and Gaussian (PG) noise that stems from optical imaging systems. To solve this problem, we develop a novel algorithm based on Accelerated Wirtinger Flow that uses Score-based Diffusion models as the generative prior (AWFSD). In particular, we frame the PR problem as an optimization task that involves both a data fidelity term and a regularization term. We derive the gradient of the PG log-likelihood function along with its corresponding Lipschitz constant, ensuring a more accurate data consistency term for practical measurements. We introduce a generative prior as part of our regularization approach by using a score-based diffusion model to capture (the gradient of) the image prior distribution. We provide theoretical analysis that establishes a critical-point convergence guarantee for the proposed AWFSD algorithm. Our simulation experiments demonstrate that: 1) The proposed algorithm based on the PG likelihood model enhances reconstruction compared to that solely based on either Gaussian or Poisson likelihood. 2) The proposed AWFSD algorithm produces reconstructions with higher image quality both qualitatively and quantitatively, and is more robust to variations in noise levels when compared with state-of-the-art methods for phase retrieval.
Towards Surgical Context Inference and Translation to Gestures
Mar 15, 2023



Manual labeling of gestures in robot-assisted surgery is labor intensive, prone to errors, and requires expertise or training. We propose a method for automated and explainable generation of gesture transcripts that leverages the abundance of data for image segmentation. Surgical context is detected using segmentation masks by examining the distances and intersections between the tools and objects. Next, context labels are translated into gesture transcripts using knowledge-based Finite State Machine (FSM) and data-driven Long Short Term Memory (LSTM) models. We evaluate the performance of each stage of our method by comparing the results with the ground truth segmentation masks, the consensus context labels, and the gesture labels in the JIGSAWS dataset. Our results show that our segmentation models achieve state-of-the-art performance in recognizing needle and thread in Suturing and we can automatically detect important surgical states with high agreement with crowd-sourced labels (e.g., contact between graspers and objects in Suturing). We also find that the FSM models are more robust to poor segmentation and labeling performance than LSTMs. Our proposed method can significantly shorten the gesture labeling process (~2.8 times).
Training End-to-End Unrolled Iterative Neural Networks for SPECT Image Reconstruction
Jan 23, 2023



Training end-to-end unrolled iterative neural networks for SPECT image reconstruction requires a memory-efficient forward-backward projector for efficient backpropagation. This paper describes an open-source, high performance Julia implementation of a SPECT forward-backward projector that supports memory-efficient backpropagation with an exact adjoint. Our Julia projector uses only ~5% of the memory of an existing Matlab-based projector. We compare unrolling a CNN-regularized expectation-maximization (EM) algorithm with end-to-end training using our Julia projector with other training methods such as gradient truncation (ignoring gradients involving the projector) and sequential training, using XCAT phantoms and virtual patient (VP) phantoms generated from SIMIND Monte Carlo (MC) simulations. Simulation results with two different radionuclides (90Y and 177Lu) show that: 1) For 177Lu XCAT phantoms and 90Y VP phantoms, training unrolled EM algorithm in end-to-end fashion with our Julia projector yields the best reconstruction quality compared to other training methods and OSEM, both qualitatively and quantitatively. For VP phantoms with 177Lu radionuclide, the reconstructed images using end-to-end training are in higher quality than using sequential training and OSEM, but are comparable with using gradient truncation. We also find there exists a trade-off between computational cost and reconstruction accuracy for different training methods. End-to-end training has the highest accuracy because the correct gradient is used in backpropagation; sequential training yields worse reconstruction accuracy, but is significantly faster and uses much less memory.
In progress
Sep 21, 2022The concept of causality plays an important role in human cognition . In the past few decades, causal inference has been well developed in many fields, such as computer science, medicine, economics, and education. With the advancement of deep learning techniques, it has been increasingly used in causal inference against counterfactual data. Typically, deep causal models map the characteristics of covariates to a representation space and then design various objective optimization functions to estimate counterfactual data unbiasedly based on the different optimization methods. This paper focuses on the survey of the deep causal models, and its core contributions are as follows: 1) we provide relevant metrics under multiple treatments and continuous-dose treatment; 2) we incorporate a comprehensive overview of deep causal models from both temporal development and method classification perspectives; 3) we assist a detailed and comprehensive classification and analysis of relevant datasets and source code.
COMPASS: A Formal Framework and Aggregate Dataset for Generalized Surgical Procedure Modeling
Sep 14, 2022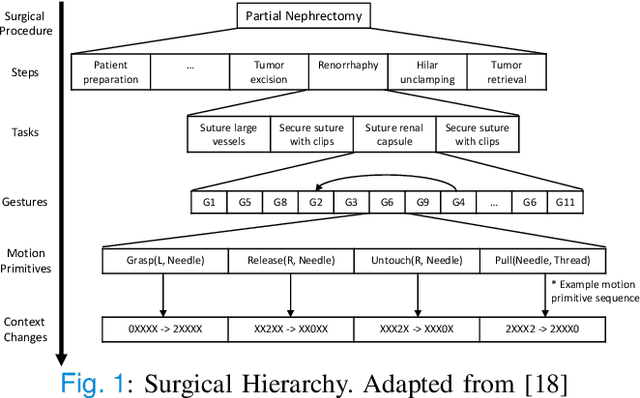
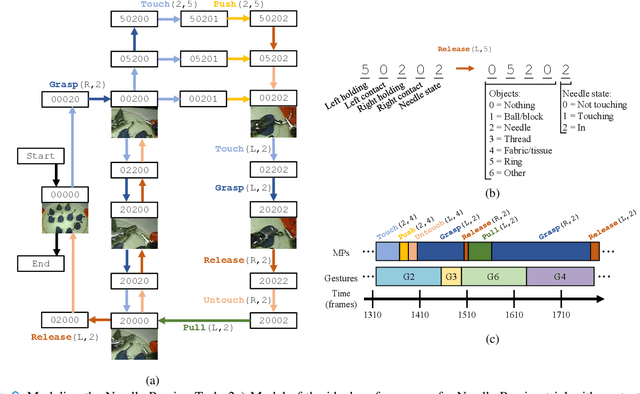


Objective: We propose a formal framework for modeling surgical tasks using a unified set of motion primitives (MPs) as the basic surgical actions to enable more objective labeling and aggregation of different datasets and training generalized models for surgical action recognition. Methods: We use our framework to create the COntext and Motion Primitive Aggregate Surgical Set (COMPASS), including six dry-lab surgical tasks from three publicly-available datasets (JIGSAWS, DESK, and ROSMA) with kinematic and video data and context and MP labels. Methods for labeling surgical context and automatic translation to MPs are presented. We propose the Leave-One-Task-Out (LOTO) cross validation method to evaluate a model's ability to generalize to an unseen task. Results: Our context labeling method achieves near-perfect agreement between consensus labels from crowd-sourcing and expert surgeons. Segmentation of tasks to MPs enables the generation of separate left and right transcripts and significantly improves LOTO performance. We find that MP segmentation models perform best if trained on tasks with the same context and/or tasks from the same dataset. Conclusion: The proposed framework enables high-quality labeling of surgical data based on context and fine-grained MPs. Modeling surgical tasks with MPs enables the aggregation of different datasets for training action recognition models that can generalize better to unseen tasks than models trained at the gesture level. Significance: Our formal framework and aggregate dataset can support the development of models and algorithms for surgical process analysis, skill assessment, error detection, and autonomy.