 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiDAS: A Multimodal Data Acquisition System and Dataset for Robot-Assisted Minimally Invasive Surgery
Feb 12, 2026Background: Robot-assisted minimally invasive surgery (RMIS) research increasingly relies on multimodal data, yet access to proprietary robot telemetry remains a major barrier. We introduce MiDAS, an open-source, platform-agnostic system enabling time-synchronized, non-invasive multimodal data acquisition across surgical robotic platforms. Methods: MiDAS integrates electromagnetic and RGB-D hand tracking, foot pedal sensing, and surgical video capturing without requiring proprietary robot interfaces. We validated MiDAS on the open-source Raven-II and the clinical da Vinci Xi by collecting multimodal datasets of peg transfer and hernia repair suturing tasks performed by surgical residents. Correlation analysis and downstream gesture recognition experiments were conducted. Results: External hand and foot sensing closely approximated internal robot kinematics and non-invasive motion signals achieved gesture recognition performance comparable to proprietary telemetry. Conclusion: MiDAS enables reproducible multimodal RMIS data collection and is released with annotated datasets, including the first multimodal dataset capturing hernia repair suturing on high-fidelity simulation models.
Expert-Guided Prompting and Retrieval-Augmented Generation for Emergency Medical Service Question Answering
Nov 18, 2025Large language models (LLMs) have shown promise in medical question answering, yet they often overlook the domain-specific expertise that professionals depend on, such as the clinical subject areas (e.g., trauma, airway) and the certification level (e.g., EMT, Paramedic). Existing approaches typically apply general-purpose prompting or retrieval strategies without leveraging this structured context, limiting performance in high-stakes settings. We address this gap with EMSQA, an 24.3K-question multiple-choice dataset spanning 10 clinical subject areas and 4 certification levels, accompanied by curated, subject area-aligned knowledge bases (40K documents and 2M tokens). Building on EMSQA, we introduce (i) Expert-CoT, a prompting strategy that conditions chain-of-thought (CoT) reasoning on specific clinical subject area and certification level, and (ii) ExpertRAG, a retrieval-augmented generation pipeline that grounds responses in subject area-aligned documents and real-world patient data. Experiments on 4 LLMs show that Expert-CoT improves up to 2.05% over vanilla CoT prompting. Additionally, combining Expert-CoT with ExpertRAG yields up to a 4.59% accuracy gain over standard RAG baselines. Notably, the 32B expertise-augmented LLMs pass all the computer-adaptive EMS certification simulation exams.
EgoEMS: A High-Fidelity Multimodal Egocentric Dataset for Cognitive Assistance in Emergency Medical Services
Nov 15, 2025Emergency Medical Services (EMS) are critical to patient survival in emergencies, but first responders often face intense cognitive demands in high-stakes situations. AI cognitive assistants, acting as virtual partners, have the potential to ease this burden by supporting real-time data collection and decision making. In pursuit of this vision, we introduce EgoEMS, the first end-to-end, high-fidelity, multimodal, multiperson dataset capturing over 20 hours of realistic, procedural EMS activities from an egocentric view in 233 simulated emergency scenarios performed by 62 participants, including 46 EMS professionals. Developed in collaboration with EMS experts and aligned with national standards, EgoEMS is captured using an open-source, low-cost, and replicable data collection system and is annotated with keysteps, timestamped audio transcripts with speaker diarization, action quality metrics, and bounding boxes with segmentation masks. Emphasizing realism, the dataset includes responder-patient interactions reflecting real-world emergency dynamics. We also present a suite of benchmarks for real-time multimodal keystep recognition and action quality estimation, essential for developing AI support tools for EMS. We hope EgoEMS inspires the research community to push the boundaries of intelligent EMS systems and ultimately contribute to improved patient outcomes.
Systems-Theoretic and Data-Driven Security Analysis in ML-enabled Medical Devices
Jun 18, 2025



The integration of AI/ML into medical devices is rapidly transforming healthcare by enhancing diagnostic and treatment facilities. However, this advancement also introduces serious cybersecurity risks due to the use of complex and often opaque models, extensive interconnectivity, interoperability with third-party peripheral devices, Internet connectivity, and vulnerabilities in the underlying technologies. These factors contribute to a broad attack surface and make threat prevention, detection, and mitigation challenging. Given the highly safety-critical nature of these devices, a cyberattack on these devices can cause the ML models to mispredict, thereby posing significant safety risks to patients. Therefore, ensuring the security of these devices from the time of design is essential. This paper underscores the urgency of addressing the cybersecurity challenges in ML-enabled medical devices at the pre-market phase. We begin by analyzing publicly available data on device recalls and adverse events, and known vulnerabilities, to understand the threat landscape of AI/ML-enabled medical devices and their repercussions on patient safety. Building on this analysis, we introduce a suite of tools and techniques designed by us to assist security analysts in conducting comprehensive premarket risk assessments. Our work aims to empower manufacturers to embed cybersecurity as a core design principle in AI/ML-enabled medical devices, thereby making them safe for patients.
Multimodal Transformers for Real-Time Surgical Activity Prediction
Mar 11, 2024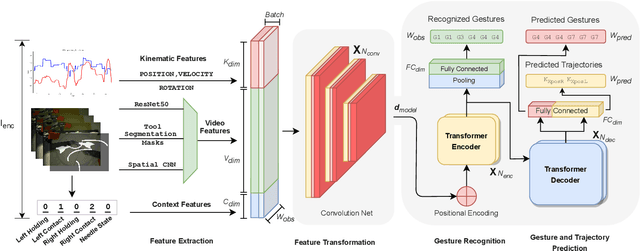

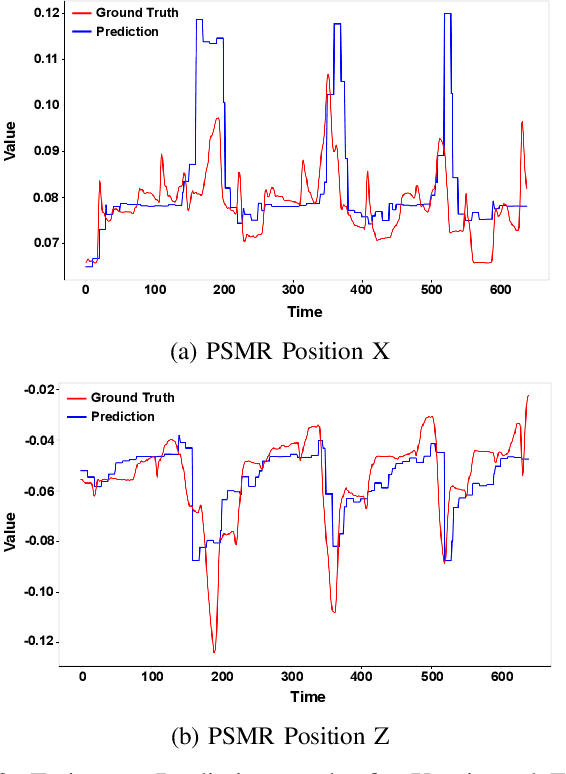
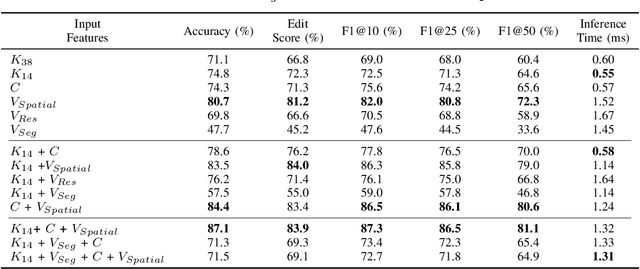
Real-time recognition and prediction of surgical activities are fundamental to advancing safety and autonomy in robot-assisted surgery. This paper presents a multimodal transformer architecture for real-time recognition and prediction of surgical gestures and trajectories based on short segments of kinematic and video data. We conduct an ablation study to evaluate the impact of fusing different input modalities and their representations on gesture recognition and prediction performance. We perform an end-to-end assessment of the proposed architecture using the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) dataset. Our model outperforms the state-of-the-art (SOTA) with 89.5\% accuracy for gesture prediction through effective fusion of kinematic features with spatial and contextual video features. It achieves the real-time performance of 1.1-1.3ms for processing a 1-second input window by relying on a computationally efficient model.
Real-Time Multimodal Cognitive Assistant for Emergency Medical Services
Mar 11, 2024Emergency Medical Services (EMS) responders often operate under time-sensitive conditions, facing cognitive overload and inherent risks, requiring essential skills in critical thinking and rapid decision-making. This paper presents CognitiveEMS, an end-to-end wearable cognitive assistant system that can act as a collaborative virtual partner engaging in the real-time acquisition and analysis of multimodal data from an emergency scene and interacting with EMS responders through Augmented Reality (AR) smart glasses. CognitiveEMS processes the continuous streams of data in real-time and leverages edge computing to provide assistance in EMS protocol selection and intervention recognition. We address key technical challenges in real-time cognitive assistance by introducing three novel components: (i) a Speech Recognition model that is fine-tuned for real-world medical emergency conversations using simulated EMS audio recordings, augmented with synthetic data generated by large language models (LLMs); (ii) an EMS Protocol Prediction model that combines state-of-the-art (SOTA) tiny language models with EMS domain knowledge using graph-based attention mechanisms; (iii) an EMS Action Recognition module which leverages multimodal audio and video data and protocol predictions to infer the intervention/treatment actions taken by the responders at the incident scene. Our results show that for speech recognition we achieve superior performance compared to SOTA (WER of 0.290 vs. 0.618) on conversational data. Our protocol prediction component also significantly outperforms SOTA (top-3 accuracy of 0.800 vs. 0.200) and the action recognition achieves an accuracy of 0.727, while maintaining an end-to-end latency of 3.78s for protocol prediction on the edge and 0.31s on the server.
Camera-Independent Single Image Depth Estimation from Defocus Blur
Nov 21, 2023Monocular depth estimation is an important step in many downstream tasks in machine vision. We address the topic of estimating monocular depth from defocus blur which can yield more accurate results than the semantic based depth estimation methods. The existing monocular depth from defocus techniques are sensitive to the particular camera that the images are taken from. We show how several camera-related parameters affect the defocus blur using optical physics equations and how they make the defocus blur depend on these parameters. The simple correction procedure we propose can alleviate this problem which does not require any retraining of the original model. We created a synthetic dataset which can be used to test the camera independent performance of depth from defocus blur models. We evaluate our model on both synthetic and real datasets (DDFF12 and NYU depth V2) obtained with different cameras and show that our methods are significantly more robust to the changes of cameras. Code: https://github.com/sleekEagle/defocus_camind.git
KnowSafe: Combined Knowledge and Data Driven Hazard Mitigation in Artificial Pancreas Systems
Nov 13, 2023



Significant progress has been made in anomaly detection and run-time monitoring to improve the safety and security of cyber-physical systems (CPS). However, less attention has been paid to hazard mitigation. This paper proposes a combined knowledge and data driven approach, KnowSafe, for the design of safety engines that can predict and mitigate safety hazards resulting from safety-critical malicious attacks or accidental faults targeting a CPS controller. We integrate domain-specific knowledge of safety constraints and context-specific mitigation actions with machine learning (ML) techniques to estimate system trajectories in the far and near future, infer potential hazards, and generate optimal corrective actions to keep the system safe. Experimental evaluation on two realistic closed-loop testbeds for artificial pancreas systems (APS) and a real-world clinical trial dataset for diabetes treatment demonstrates that KnowSafe outperforms the state-of-the-art by achieving higher accuracy in predicting system state trajectories and potential hazards, a low false positive rate, and no false negatives. It also maintains the safe operation of the simulated APS despite faults or attacks without introducing any new hazards, with a hazard mitigation success rate of 92.8%, which is at least 76% higher than solely rule-based (50.9%) and data-driven (52.7%) methods.
Towards Interpretable Motion-level Skill Assessment in Robotic Surgery
Nov 10, 2023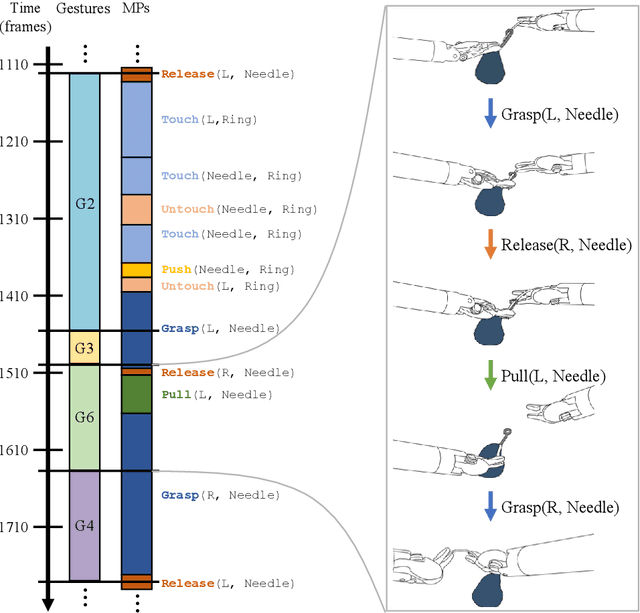
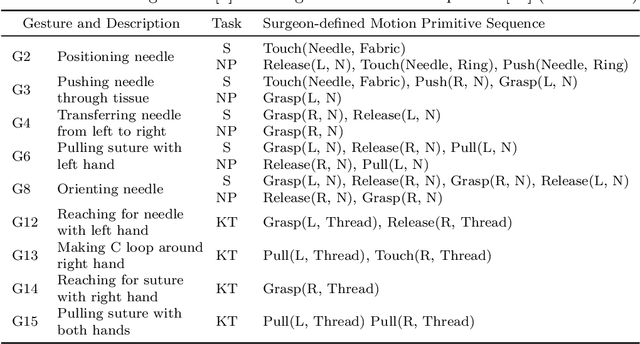
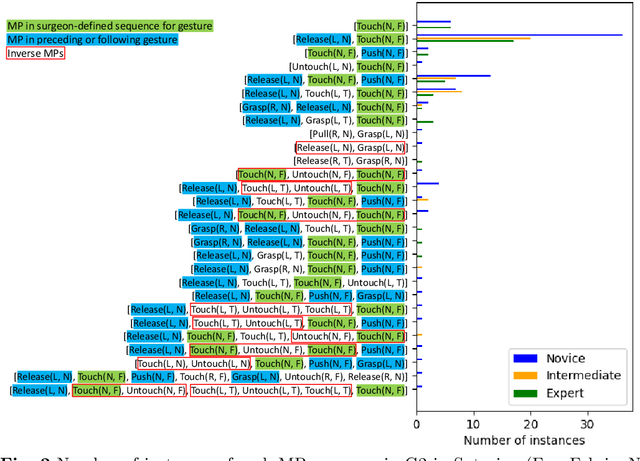

Purpose: We study the relationship between surgical gestures and motion primitives in dry-lab surgical exercises towards a deeper understanding of surgical activity at fine-grained levels and interpretable feedback in skill assessment. Methods: We analyze the motion primitive sequences of gestures in the JIGSAWS dataset and identify inverse motion primitives in those sequences. Inverse motion primitives are defined as sequential actions on the same object by the same tool that effectively negate each other. We also examine the correlation between surgical skills (measured by GRS scores) and the number and total durations of inverse motion primitives in the dry-lab trials of Suturing, Needle Passing, and Knot Tying tasks. Results: We find that the sequence of motion primitives used to perform gestures can help detect labeling errors in surgical gestures. Inverse motion primitives are often used as recovery actions to correct the position or orientation of objects or may be indicative of other issues such as with depth perception. The number and total durations of inverse motion primitives in trials are also strongly correlated with lower GRS scores in the Suturing and Knot Tying tasks. Conclusion: The sequence and pattern of motion primitives could be used to provide interpretable feedback in surgical skill assessment. Combined with an action recognition model, the explainability of automated skill assessment can be improved by showing video clips of the inverse motion primitives of inefficient or problematic movements.
DKEC: Domain Knowledge Enhanced Multi-Label Classification for Electronic Health Records
Oct 10, 2023Multi-label text classification (MLTC) tasks in the medical domain often face long-tail label distribution, where rare classes have fewer training samples than frequent classes. Although previous works have explored different model architectures and hierarchical label structures to find important features, most of them neglect to incorporate the domain knowledge from medical guidelines. In this paper, we present DKEC, Domain Knowledge Enhanced Classifier for medical diagnosis prediction with two innovations: (1) a label-wise attention mechanism that incorporates a heterogeneous graph and domain ontologies to capture the semantic relationships between medical entities, (2) a simple yet effective group-wise training method based on similarity of labels to increase samples of rare classes. We evaluate DKEC on two real-world medical datasets: the RAA dataset, a collection of 4,417 patient care reports from emergency medical services (EMS) incidents, and a subset of 53,898 reports from the MIMIC-III dataset. Experimental results show that our method outperforms the state-of-the-art, particularly for the few-shot (tail) classes. More importantly, we study the applicability of DKEC to different language models and show that DKEC can help the smaller language models achieve comparable performance to large language models.