 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Transformers for Real-Time Surgical Activity Prediction
Mar 11, 2024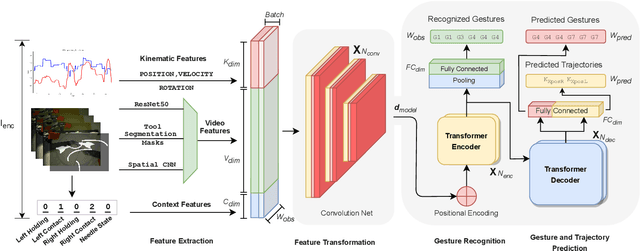

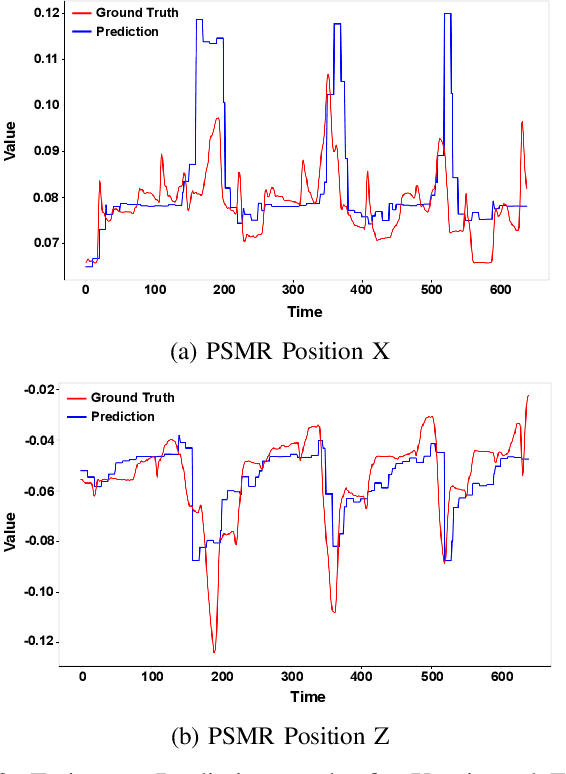
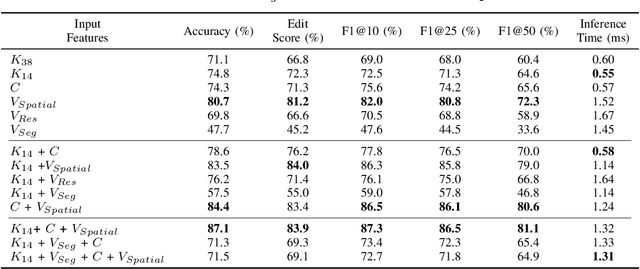
Real-time recognition and prediction of surgical activities are fundamental to advancing safety and autonomy in robot-assisted surgery. This paper presents a multimodal transformer architecture for real-time recognition and prediction of surgical gestures and trajectories based on short segments of kinematic and video data. We conduct an ablation study to evaluate the impact of fusing different input modalities and their representations on gesture recognition and prediction performance. We perform an end-to-end assessment of the proposed architecture using the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) dataset. Our model outperforms the state-of-the-art (SOTA) with 89.5\% accuracy for gesture prediction through effective fusion of kinematic features with spatial and contextual video features. It achieves the real-time performance of 1.1-1.3ms for processing a 1-second input window by relying on a computationally efficient model.
Towards Interpretable Motion-level Skill Assessment in Robotic Surgery
Nov 10, 2023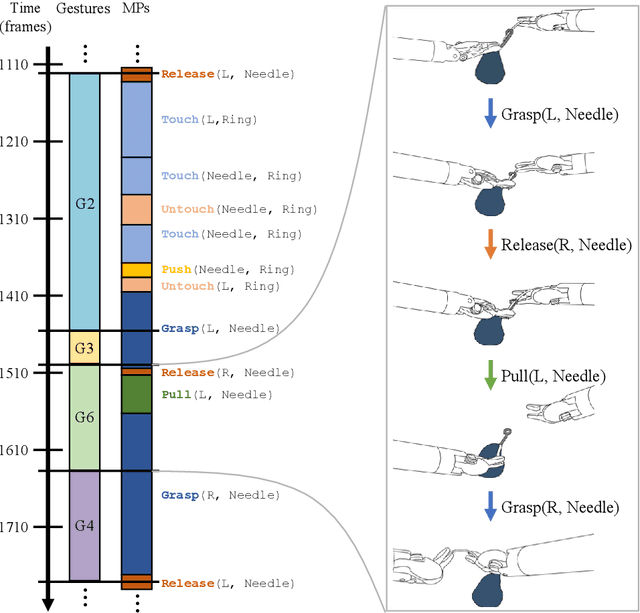
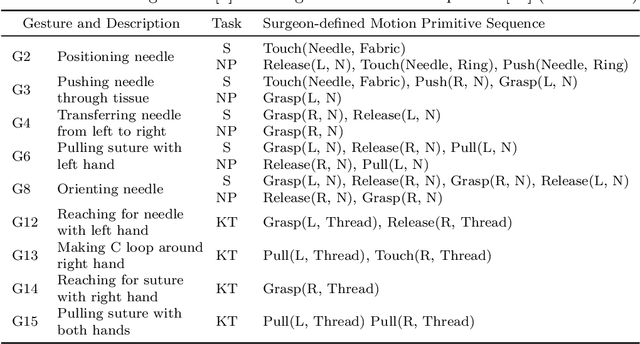
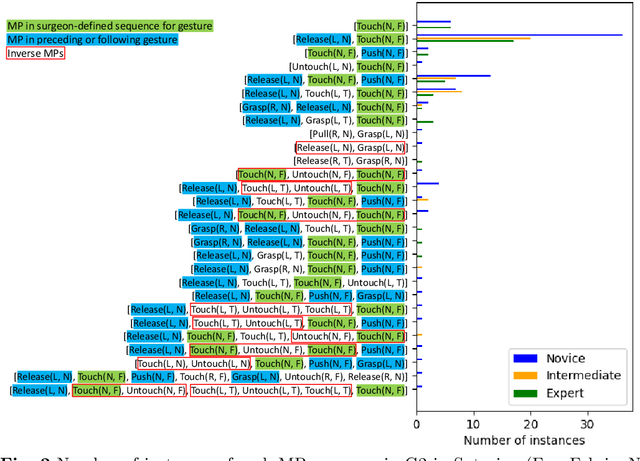

Purpose: We study the relationship between surgical gestures and motion primitives in dry-lab surgical exercises towards a deeper understanding of surgical activity at fine-grained levels and interpretable feedback in skill assessment. Methods: We analyze the motion primitive sequences of gestures in the JIGSAWS dataset and identify inverse motion primitives in those sequences. Inverse motion primitives are defined as sequential actions on the same object by the same tool that effectively negate each other. We also examine the correlation between surgical skills (measured by GRS scores) and the number and total durations of inverse motion primitives in the dry-lab trials of Suturing, Needle Passing, and Knot Tying tasks. Results: We find that the sequence of motion primitives used to perform gestures can help detect labeling errors in surgical gestures. Inverse motion primitives are often used as recovery actions to correct the position or orientation of objects or may be indicative of other issues such as with depth perception. The number and total durations of inverse motion primitives in trials are also strongly correlated with lower GRS scores in the Suturing and Knot Tying tasks. Conclusion: The sequence and pattern of motion primitives could be used to provide interpretable feedback in surgical skill assessment. Combined with an action recognition model, the explainability of automated skill assessment can be improved by showing video clips of the inverse motion primitives of inefficient or problematic movements.
Evaluating the Task Generalization of Temporal Convolutional Networks for Surgical Gesture and Motion Recognition using Kinematic Data
Jun 28, 2023



Fine-grained activity recognition enables explainable analysis of procedures for skill assessment, autonomy, and error detection in robot-assisted surgery. However, existing recognition models suffer from the limited availability of annotated datasets with both kinematic and video data and an inability to generalize to unseen subjects and tasks. Kinematic data from the surgical robot is particularly critical for safety monitoring and autonomy, as it is unaffected by common camera issues such as occlusions and lens contamination. We leverage an aggregated dataset of six dry-lab surgical tasks from a total of 28 subjects to train activity recognition models at the gesture and motion primitive (MP) levels and for separate robotic arms using only kinematic data. The models are evaluated using the LOUO (Leave-One-User-Out) and our proposed LOTO (Leave-One-Task-Out) cross validation methods to assess their ability to generalize to unseen users and tasks respectively. Gesture recognition models achieve higher accuracies and edit scores than MP recognition models. But, using MPs enables the training of models that can generalize better to unseen tasks. Also, higher MP recognition accuracy can be achieved by training separate models for the left and right robot arms. For task-generalization, MP recognition models perform best if trained on similar tasks and/or tasks from the same dataset.
Towards Surgical Context Inference and Translation to Gestures
Mar 15, 2023



Manual labeling of gestures in robot-assisted surgery is labor intensive, prone to errors, and requires expertise or training. We propose a method for automated and explainable generation of gesture transcripts that leverages the abundance of data for image segmentation. Surgical context is detected using segmentation masks by examining the distances and intersections between the tools and objects. Next, context labels are translated into gesture transcripts using knowledge-based Finite State Machine (FSM) and data-driven Long Short Term Memory (LSTM) models. We evaluate the performance of each stage of our method by comparing the results with the ground truth segmentation masks, the consensus context labels, and the gesture labels in the JIGSAWS dataset. Our results show that our segmentation models achieve state-of-the-art performance in recognizing needle and thread in Suturing and we can automatically detect important surgical states with high agreement with crowd-sourced labels (e.g., contact between graspers and objects in Suturing). We also find that the FSM models are more robust to poor segmentation and labeling performance than LSTMs. Our proposed method can significantly shorten the gesture labeling process (~2.8 times).
COMPASS: A Formal Framework and Aggregate Dataset for Generalized Surgical Procedure Modeling
Sep 14, 2022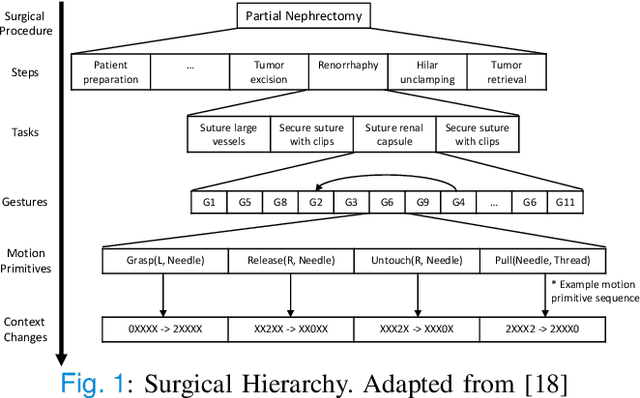
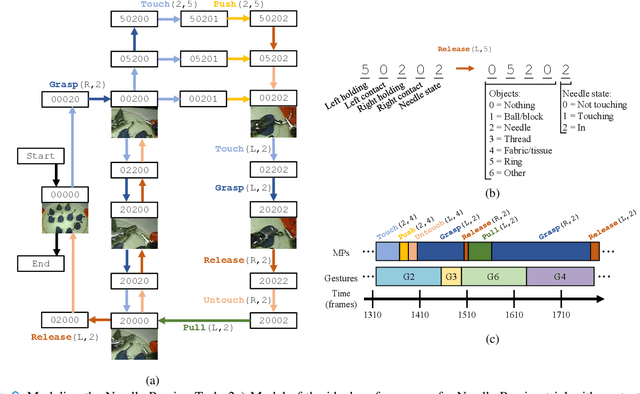


Objective: We propose a formal framework for modeling surgical tasks using a unified set of motion primitives (MPs) as the basic surgical actions to enable more objective labeling and aggregation of different datasets and training generalized models for surgical action recognition. Methods: We use our framework to create the COntext and Motion Primitive Aggregate Surgical Set (COMPASS), including six dry-lab surgical tasks from three publicly-available datasets (JIGSAWS, DESK, and ROSMA) with kinematic and video data and context and MP labels. Methods for labeling surgical context and automatic translation to MPs are presented. We propose the Leave-One-Task-Out (LOTO) cross validation method to evaluate a model's ability to generalize to an unseen task. Results: Our context labeling method achieves near-perfect agreement between consensus labels from crowd-sourcing and expert surgeons. Segmentation of tasks to MPs enables the generation of separate left and right transcripts and significantly improves LOTO performance. We find that MP segmentation models perform best if trained on tasks with the same context and/or tasks from the same dataset. Conclusion: The proposed framework enables high-quality labeling of surgical data based on context and fine-grained MPs. Modeling surgical tasks with MPs enables the aggregation of different datasets for training action recognition models that can generalize better to unseen tasks than models trained at the gesture level. Significance: Our formal framework and aggregate dataset can support the development of models and algorithms for surgical process analysis, skill assessment, error detection, and autonomy.
Runtime Detection of Executional Errors in Robot-Assisted Surgery
Mar 01, 2022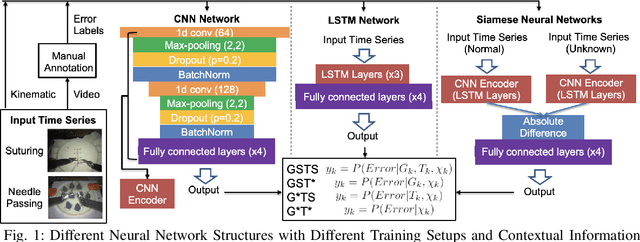
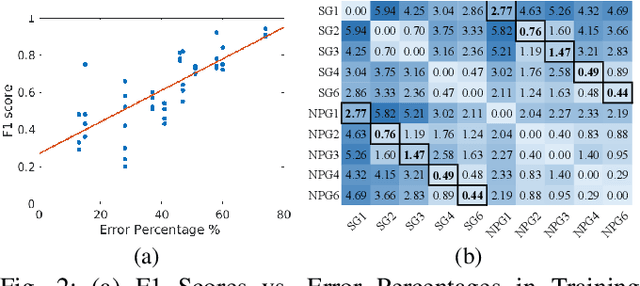
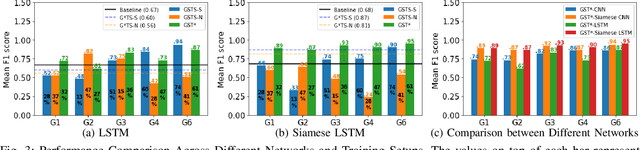
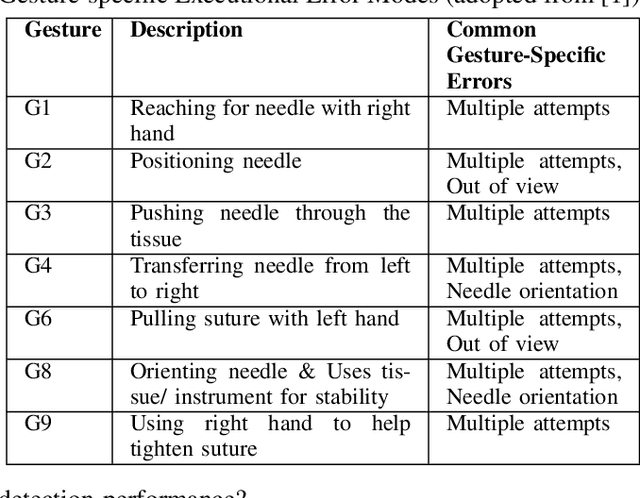
Despite significant developments in the design of surgical robots and automated techniques for objective evaluation of surgical skills, there are still challenges in ensuring safety in robot-assisted minimally-invasive surgery (RMIS). This paper presents a runtime monitoring system for the detection of executional errors during surgical tasks through the analysis of kinematic data. The proposed system incorporates dual Siamese neural networks and knowledge of surgical context, including surgical tasks and gestures, their distributional similarities, and common error modes, to learn the differences between normal and erroneous surgical trajectories from small training datasets. We evaluate the performance of the error detection using Siamese networks compared to single CNN and LSTM networks trained with different levels of contextual knowledge and training data, using the dry-lab demonstrations of the Suturing and Needle Passing tasks from the JIGSAWS dataset. Our results show that gesture specific task nonspecific Siamese networks obtain micro F1 scores of 0.94 (Siamese-CNN) and 0.95 (Siamese-LSTM), and perform better than single CNN (0.86) and LSTM (0.87) networks. These Siamese networks also outperform gesture nonspecific task specific Siamese-CNN and Siamese-LSTM models for Suturing and Needle Passing.
Analysis of Executional and Procedural Errors in Dry-lab Robotic Surgery Experiments
Jun 22, 2021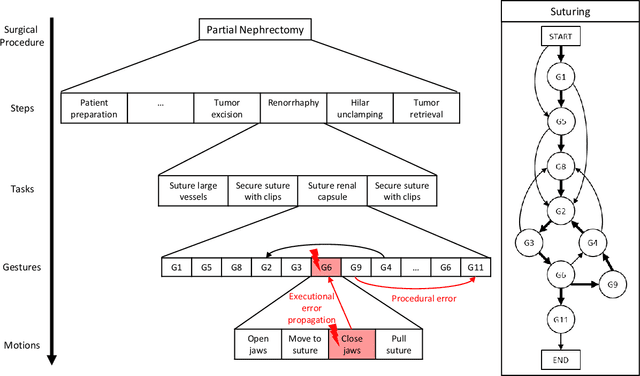
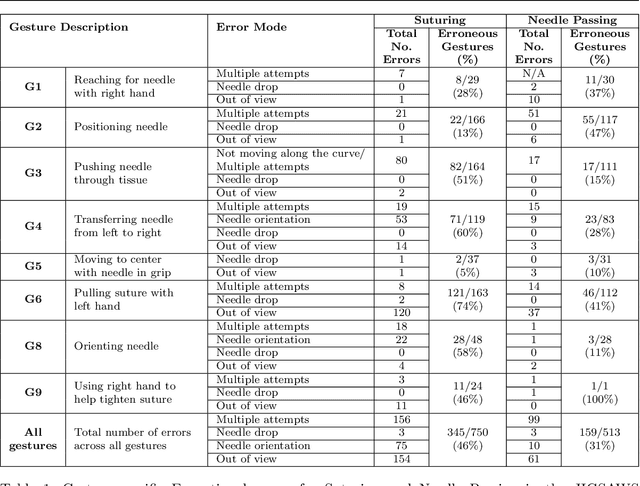
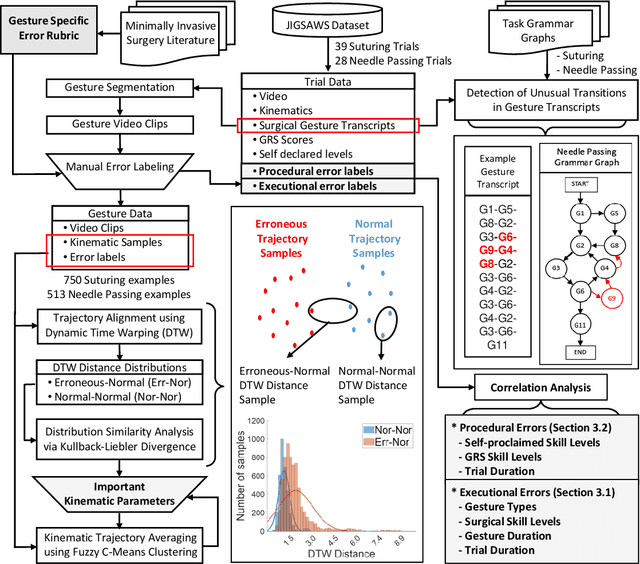
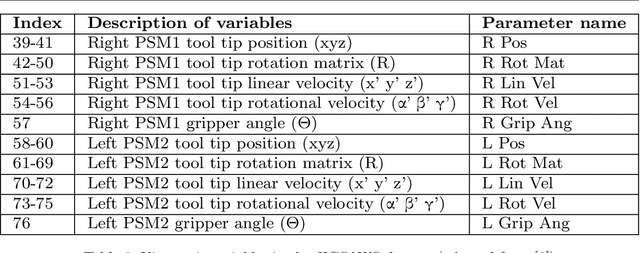
Background We aim to develop a method for automated detection of potentially erroneous motions that lead to sub-optimal surgeon performance and safety-critical events in robot-assisted surgery. Methods We develop a rubric for identifying task and gesture-specific Executional and Procedural errors and evaluate dry-lab demonstrations of Suturing and Needle Passing tasks from the JIGSAWS dataset. We characterize erroneous parts of demonstrations by labeling video data, and use distribution similarity analysis and trajectory averaging on kinematic data to identify parameters that distinguish erroneous gestures. Results Executional error frequency varies by task and gesture and correlates with skill level. Some predominant error modes in each gesture are distinguishable by analyzing error-specific kinematic parameters. Procedural errors could lead to lower performance scores and increased demonstration times but also depend on surgical style. Conclusions This study provides preliminary evidence that automated error detection can provide context-dependent and quantitative feedback to surgical trainees for performance improvement.
A Reactive Autonomous Camera System for the RAVEN II Surgical Robot
Oct 09, 2020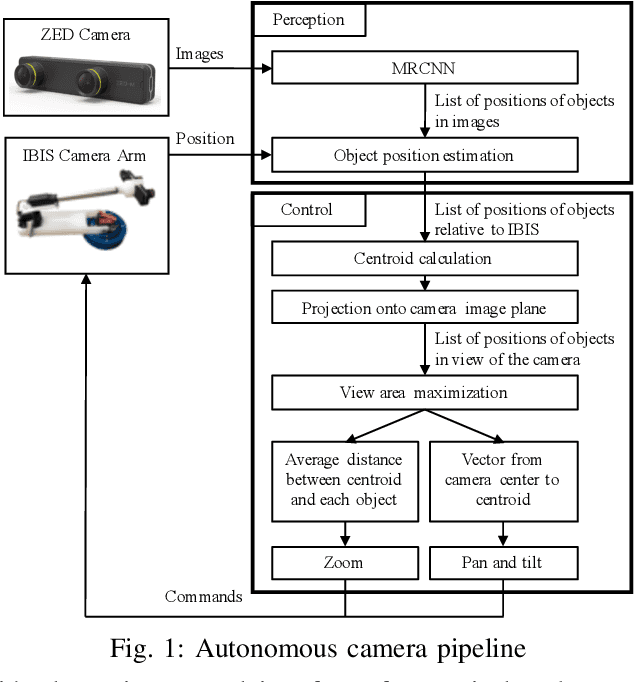

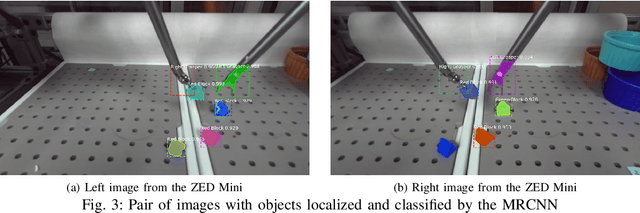
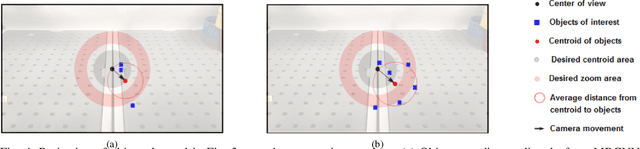
The endoscopic camera of a surgical robot provides surgeons with a magnified 3D view of the surgical field, but repositioning it increases mental workload and operation time. Poor camera placement contributes to safety-critical events when surgical tools move out of the view of the camera. This paper presents a proof of concept of an autonomous camera system for the Raven II surgical robot that aims to reduce surgeon workload and improve safety by providing an optimal view of the workspace showing all objects of interest. This system uses transfer learning to localize and classify objects of interest within the view of a stereoscopic camera. The positions and centroid of the objects are estimated and a set of control rules determines the movement of the camera towards a more desired view. Our perception module had an accuracy of 61.21% overall for identifying objects of interest and was able to localize both graspers and multiple blocks in the environment. Comparison of the commands proposed by our system with the desired commands from a survey of 13 participants indicates that the autonomous camera system proposes appropriate movements for the tilt and pan of the camera.