 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoHRT: A Collaboration System for Human-Robot Teamwork
Oct 11, 2024Collaborative robots are increasingly deployed alongside humans in factories, hospitals, schools, and other domains to enhance teamwork and efficiency. Systems that seamlessly integrate humans and robots into cohesive teams for coordinated and efficient task execution are needed, enabling studies on how robot collaboration policies affect team performance and teammates' perceived fairness, trust, and safety. Such a system can also be utilized to study the impact of a robot's normative behavior on team collaboration. Additionally, it allows for investigation into how the legibility and predictability of robot actions affect human-robot teamwork and perceived safety and trust. Existing systems are limited, typically involving one human and one robot, and thus require more insight into broader team dynamics. Many rely on games or virtual simulations, neglecting the impact of a robot's physical presence. Most tasks are turn-based, hindering simultaneous execution and affecting efficiency. This paper introduces CoHRT (Collaboration System for Human-Robot Teamwork), which facilitates multi-human-robot teamwork through seamless collaboration, coordination, and communication. CoHRT utilizes a server-client-based architecture, a vision-based system to track task environments, and a simple interface for team action coordination. It allows for the design of tasks considering the human teammates' physical and mental workload and varied skill labels across the team members. We used CoHRT to design a collaborative block manipulation and jigsaw puzzle-solving task in a team of one Franka Emika Panda robot and two humans. The system enables recording multi-modal collaboration data to develop adaptive collaboration policies for robots. To further utilize CoHRT, we outline potential research directions in diverse human-robot collaborative tasks.
Improving Human Motion Prediction Through Continual Learning
Jul 01, 2021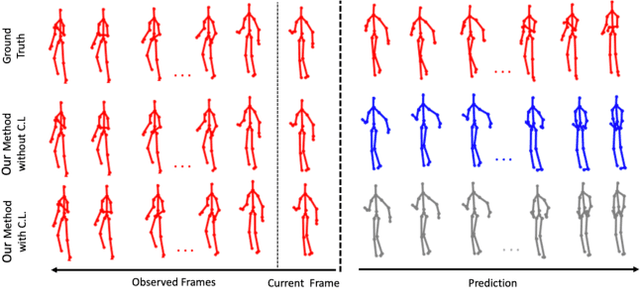

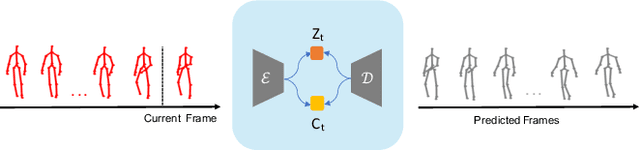
Human motion prediction is an essential component for enabling closer human-robot collaboration. The task of accurately predicting human motion is non-trivial. It is compounded by the variability of human motion, both at a skeletal level due to the varying size of humans and at a motion level due to individual movement's idiosyncrasies. These variables make it challenging for learning algorithms to obtain a general representation that is robust to the diverse spatio-temporal patterns of human motion. In this work, we propose a modular sequence learning approach that allows end-to-end training while also having the flexibility of being fine-tuned. Our approach relies on the diversity of training samples to first learn a robust representation, which can then be fine-tuned in a continual learning setup to predict the motion of new subjects. We evaluated the proposed approach by comparing its performance against state-of-the-art baselines. The results suggest that our approach outperforms other methods over all the evaluated temporal horizons, using a small amount of data for fine-tuning. The improved performance of our approach opens up the possibility of using continual learning for personalized and reliable motion prediction.
A Reactive Autonomous Camera System for the RAVEN II Surgical Robot
Oct 09, 2020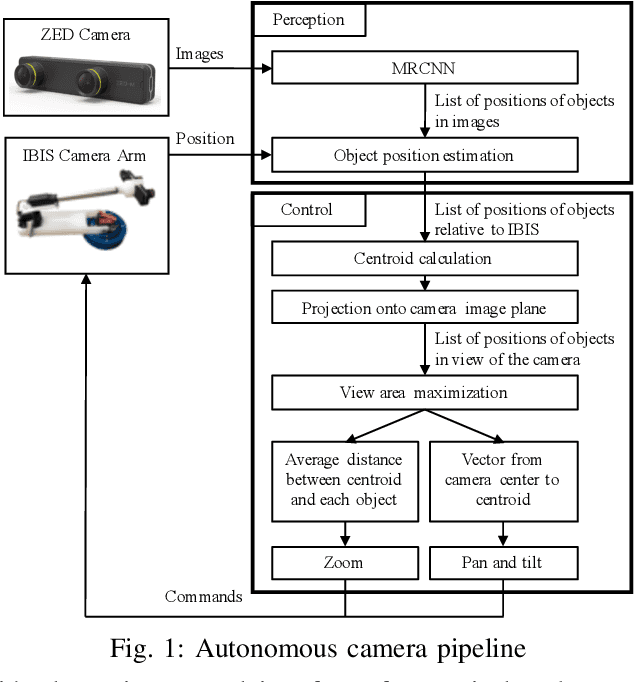

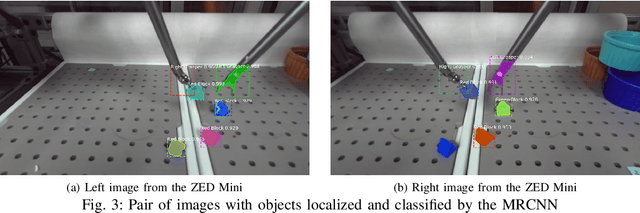
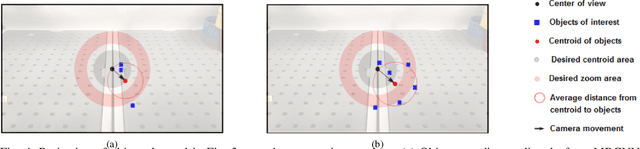
The endoscopic camera of a surgical robot provides surgeons with a magnified 3D view of the surgical field, but repositioning it increases mental workload and operation time. Poor camera placement contributes to safety-critical events when surgical tools move out of the view of the camera. This paper presents a proof of concept of an autonomous camera system for the Raven II surgical robot that aims to reduce surgeon workload and improve safety by providing an optimal view of the workspace showing all objects of interest. This system uses transfer learning to localize and classify objects of interest within the view of a stereoscopic camera. The positions and centroid of the objects are estimated and a set of control rules determines the movement of the camera towards a more desired view. Our perception module had an accuracy of 61.21% overall for identifying objects of interest and was able to localize both graspers and multiple blocks in the environment. Comparison of the commands proposed by our system with the desired commands from a survey of 13 participants indicates that the autonomous camera system proposes appropriate movements for the tilt and pan of the camera.
Real-Time Context-aware Detection of Unsafe Events in Robot-Assisted Surgery
May 07, 2020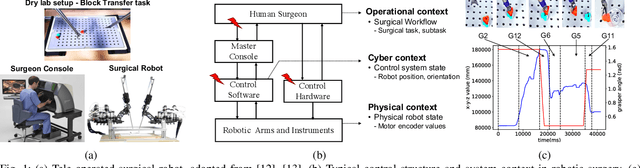
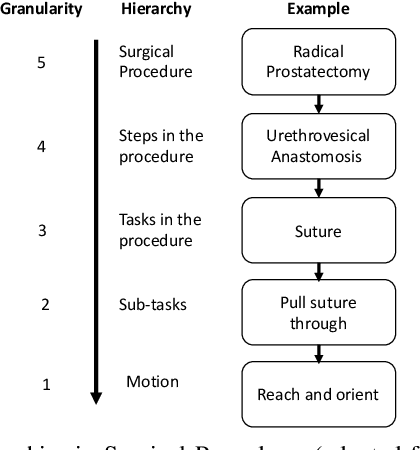
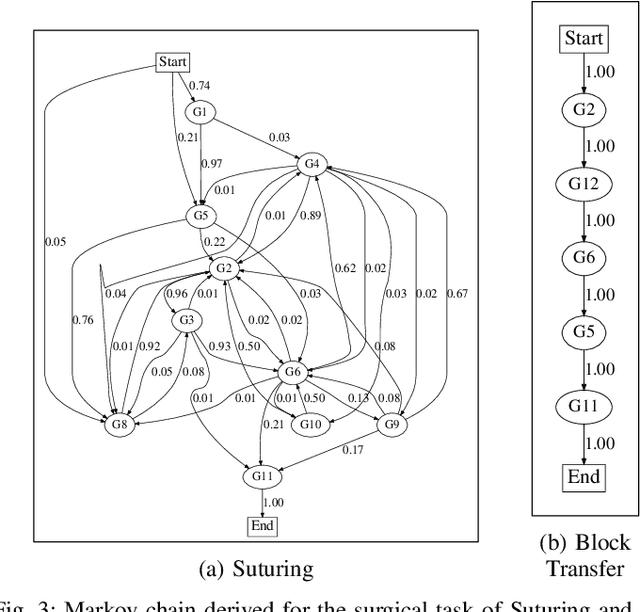
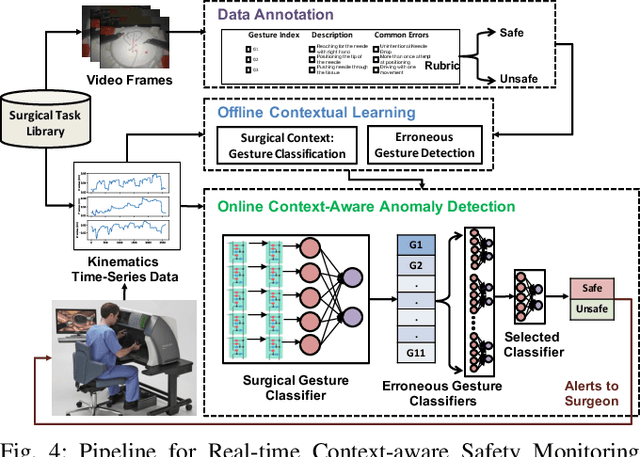
Cyber-physical systems for robotic surgery have enabled minimally invasive procedures with increased precision and shorter hospitalization. However, with increasing complexity and connectivity of software and major involvement of human operators in the supervision of surgical robots, there remain significant challenges in ensuring patient safety. This paper presents a safety monitoring system that, given the knowledge of the surgical task being performed by the surgeon, can detect safety-critical events in real-time. Our approach integrates a surgical gesture classifier that infers the operational context from the time-series kinematics data of the robot with a library of erroneous gesture classifiers that given a surgical gesture can detect unsafe events. Our experiments using data from two surgical platforms show that the proposed system can detect unsafe events caused by accidental or malicious faults within an average reaction time window of 1,693 milliseconds and F1 score of 0.88 and human errors within an average reaction time window of 57 milliseconds and F1 score of 0.76.
Context-aware Monitoring in Robotic Surgery
Jan 28, 2019
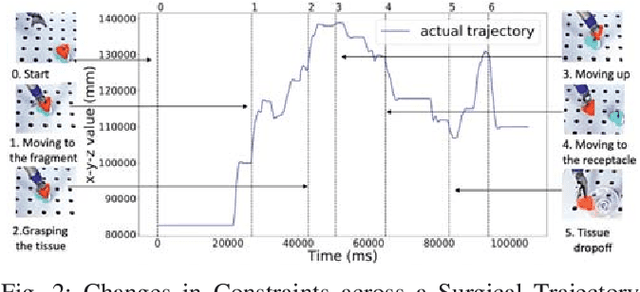
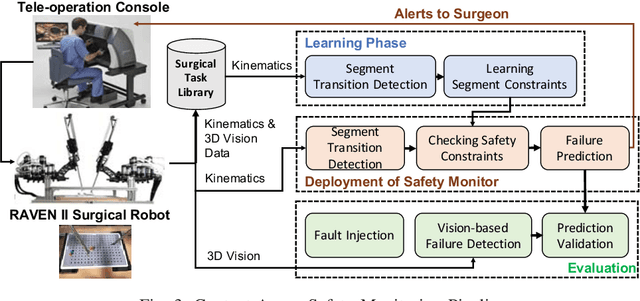
Robotic-assisted minimally invasive surgery (MIS) has enabled procedures with increased precision and dexterity, but surgical robots are still open loop and require surgeons to work with a tele-operation console providing only limited visual feedback. In this setting, mechanical failures, software faults, or human errors might lead to adverse events resulting in patient complications or fatalities. We argue that impending adverse events could be detected and mitigated by applying context-specific safety constraints on the motions of the robot. We present a context-aware safety monitoring system which segments a surgical task into subtasks using kinematics data and monitors safety constraints specific to each subtask. To test our hypothesis about context specificity of safety constraints, we analyze recorded demonstrations of dry-lab surgical tasks collected from the JIGSAWS database as well as from experiments we conducted on a Raven II surgical robot. Analysis of the trajectory data shows that each subtask of a given surgical procedure has consistent safety constraints across multiple demonstrations by different subjects. Our preliminary results show that violations of these safety constraints lead to unsafe events, and there is often sufficient time between the constraint violation and the safety-critical event to allow for a corrective action.