 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2HRI: An LLM-Driven Multimodal Multi-Agent Framework for Personalized Human-Robot Interaction
Apr 13, 2026Multi-robot systems hold significant promise for social environments such as homes and hospitals, yet existing multi-robot works treat robots as functionally identical, overlooking how robots individual identity shape user perception and how coordination shapes multi-robot behavior when such individuality is present. To address this, we introduce M2HRI, a multimodal multi-agent framework built on large language models that equips each robot with distinct personality and long-term memory, alongside a coordination mechanism conditioned on these differences. In a controlled user study (n = 105) in a multi-agent human-robot interaction (HRI) scenario, we find that LLM-driven personality traits are significantly distinguishable and enhance interaction quality, long-term memory improves personalization and preference awareness, and centralized coordination significantly reduces overlap while improving overall interaction quality. Together, these results demonstrate that both agent individuality and structured coordination are essential for coherent and socially appropriate multi-agent HRI. Project website and code are available at https://project-m2hri.github.io/.
A Multimodal Framework for Human-Multi-Agent Interaction
Mar 24, 2026Human-robot interaction is increasingly moving toward multi-robot, socially grounded environments. Existing systems struggle to integrate multimodal perception, embodied expression, and coordinated decision-making in a unified framework. This limits natural and scalable interaction in shared physical spaces. We address this gap by introducing a multimodal framework for human-multi-agent interaction in which each robot operates as an autonomous cognitive agent with integrated multimodal perception and Large Language Model (LLM)-driven planning grounded in embodiment. At the team level, a centralized coordination mechanism regulates turn-taking and agent participation to prevent overlapping speech and conflicting actions. Implemented on two humanoid robots, our framework enables coherent multi-agent interaction through interaction policies that combine speech, gesture, gaze, and locomotion. Representative interaction runs demonstrate coordinated multimodal reasoning across agents and grounded embodied responses. Future work will focus on larger-scale user studies and deeper exploration of socially grounded multi-agent interaction dynamics.
Energy-Based Transformers are Scalable Learners and Thinkers
Jul 02, 2025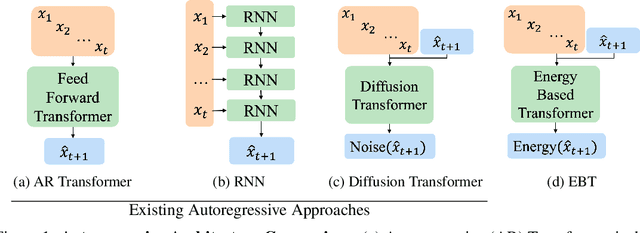


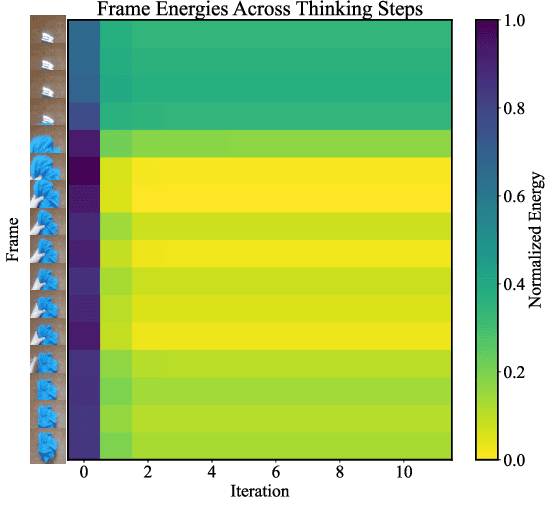
Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
Using Physiological Measures, Gaze, and Facial Expressions to Model Human Trust in a Robot Partner
Apr 07, 2025



With robots becoming increasingly prevalent in various domains, it has become crucial to equip them with tools to achieve greater fluency in interactions with humans. One of the promising areas for further exploration lies in human trust. A real-time, objective model of human trust could be used to maximize productivity, preserve safety, and mitigate failure. In this work, we attempt to use physiological measures, gaze, and facial expressions to model human trust in a robot partner. We are the first to design an in-person, human-robot supervisory interaction study to create a dedicated trust dataset. Using this dataset, we train machine learning algorithms to identify the objective measures that are most indicative of trust in a robot partner, advancing trust prediction in human-robot interactions. Our findings indicate that a combination of sensor modalities (blood volume pulse, electrodermal activity, skin temperature, and gaze) can enhance the accuracy of detecting human trust in a robot partner. Furthermore, the Extra Trees, Random Forest, and Decision Trees classifiers exhibit consistently better performance in measuring the person's trust in the robot partner. These results lay the groundwork for constructing a real-time trust model for human-robot interaction, which could foster more efficient interactions between humans and robots.
* Accepted at the IEEE International Conference on Robotics and Automation (ICRA), 2025
DM-Codec: Distilling Multimodal Representations for Speech Tokenization
Oct 19, 2024



Recent advancements in speech-language models have yielded significant improvements in speech tokenization and synthesis. However, effectively mapping the complex, multidimensional attributes of speech into discrete tokens remains challenging. This process demands acoustic, semantic, and contextual information for precise speech representations. Existing speech representations generally fall into two categories: acoustic tokens from audio codecs and semantic tokens from speech self-supervised learning models. Although recent efforts have unified acoustic and semantic tokens for improved performance, they overlook the crucial role of contextual representation in comprehensive speech modeling. Our empirical investigations reveal that the absence of contextual representations results in elevated Word Error Rate (WER) and Word Information Lost (WIL) scores in speech transcriptions. To address these limitations, we propose two novel distillation approaches: (1) a language model (LM)-guided distillation method that incorporates contextual information, and (2) a combined LM and self-supervised speech model (SM)-guided distillation technique that effectively distills multimodal representations (acoustic, semantic, and contextual) into a comprehensive speech tokenizer, termed DM-Codec. The DM-Codec architecture adopts a streamlined encoder-decoder framework with a Residual Vector Quantizer (RVQ) and incorporates the LM and SM during the training process. Experiments show DM-Codec significantly outperforms state-of-the-art speech tokenization models, reducing WER by up to 13.46%, WIL by 9.82%, and improving speech quality by 5.84% and intelligibility by 1.85% on the LibriSpeech benchmark dataset. The code, samples, and model checkpoints are available at https://github.com/mubtasimahasan/DM-Codec.
What Am I? Evaluating the Effect of Language Fluency and Task Competency on the Perception of a Social Robot
Oct 14, 2024Recent advancements in robot capabilities have enabled them to interact with people in various human-social environments (HSEs). In many of these environments, the perception of the robot often depends on its capabilities, e.g., task competency, language fluency, etc. To enable fluent human-robot interaction (HRI) in HSEs, it is crucial to understand the impact of these capabilities on the perception of the robot. Although many works have investigated the effects of various robot capabilities on the robot's perception separately, in this paper, we present a large-scale HRI study (n = 60) to investigate the combined impact of both language fluency and task competency on the perception of a robot. The results suggest that while language fluency may play a more significant role than task competency in the perception of the verbal competency of a robot, both language fluency and task competency contribute to the perception of the intelligence and reliability of the robot. The results also indicate that task competency may play a more significant role than language fluency in the perception of meeting expectations and being a good teammate. The findings of this study highlight the relationship between language fluency and task competency in the context of social HRI and will enable the development of more intelligent robots in the future.
* Accepted at the IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2024
CoHRT: A Collaboration System for Human-Robot Teamwork
Oct 11, 2024Collaborative robots are increasingly deployed alongside humans in factories, hospitals, schools, and other domains to enhance teamwork and efficiency. Systems that seamlessly integrate humans and robots into cohesive teams for coordinated and efficient task execution are needed, enabling studies on how robot collaboration policies affect team performance and teammates' perceived fairness, trust, and safety. Such a system can also be utilized to study the impact of a robot's normative behavior on team collaboration. Additionally, it allows for investigation into how the legibility and predictability of robot actions affect human-robot teamwork and perceived safety and trust. Existing systems are limited, typically involving one human and one robot, and thus require more insight into broader team dynamics. Many rely on games or virtual simulations, neglecting the impact of a robot's physical presence. Most tasks are turn-based, hindering simultaneous execution and affecting efficiency. This paper introduces CoHRT (Collaboration System for Human-Robot Teamwork), which facilitates multi-human-robot teamwork through seamless collaboration, coordination, and communication. CoHRT utilizes a server-client-based architecture, a vision-based system to track task environments, and a simple interface for team action coordination. It allows for the design of tasks considering the human teammates' physical and mental workload and varied skill labels across the team members. We used CoHRT to design a collaborative block manipulation and jigsaw puzzle-solving task in a team of one Franka Emika Panda robot and two humans. The system enables recording multi-modal collaboration data to develop adaptive collaboration policies for robots. To further utilize CoHRT, we outline potential research directions in diverse human-robot collaborative tasks.
Cognitively Inspired Energy-Based World Models
Jun 13, 2024One of the predominant methods for training world models is autoregressive prediction in the output space of the next element of a sequence. In Natural Language Processing (NLP), this takes the form of Large Language Models (LLMs) predicting the next token; in Computer Vision (CV), this takes the form of autoregressive models predicting the next frame/token/pixel. However, this approach differs from human cognition in several respects. First, human predictions about the future actively influence internal cognitive processes. Second, humans naturally evaluate the plausibility of predictions regarding future states. Based on this capability, and third, by assessing when predictions are sufficient, humans allocate a dynamic amount of time to make a prediction. This adaptive process is analogous to System 2 thinking in psychology. All these capabilities are fundamental to the success of humans at high-level reasoning and planning. Therefore, to address the limitations of traditional autoregressive models lacking these human-like capabilities, we introduce Energy-Based World Models (EBWM). EBWM involves training an Energy-Based Model (EBM) to predict the compatibility of a given context and a predicted future state. In doing so, EBWM enables models to achieve all three facets of human cognition described. Moreover, we developed a variant of the traditional autoregressive transformer tailored for Energy-Based models, termed the Energy-Based Transformer (EBT). Our results demonstrate that EBWM scales better with data and GPU Hours than traditional autoregressive transformers in CV, and that EBWM offers promising early scaling in NLP. Consequently, this approach offers an exciting path toward training future models capable of System 2 thinking and intelligently searching across state spaces.
Representation Learning in Deep RL via Discrete Information Bottleneck
Dec 28, 2022


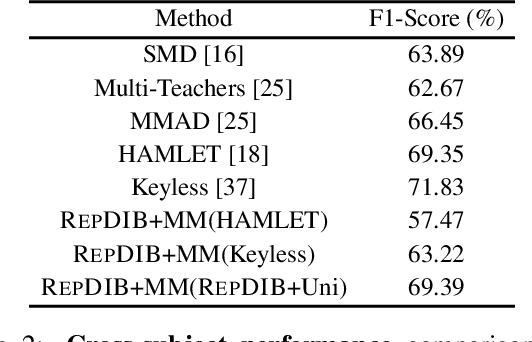
Several self-supervised representation learning methods have been proposed for reinforcement learning (RL) with rich observations. For real-world applications of RL, recovering underlying latent states is crucial, particularly when sensory inputs contain irrelevant and exogenous information. In this work, we study how information bottlenecks can be used to construct latent states efficiently in the presence of task-irrelevant information. We propose architectures that utilize variational and discrete information bottlenecks, coined as RepDIB, to learn structured factorized representations. Exploiting the expressiveness bought by factorized representations, we introduce a simple, yet effective, bottleneck that can be integrated with any existing self-supervised objective for RL. We demonstrate this across several online and offline RL benchmarks, along with a real robot arm task, where we find that compressed representations with RepDIB can lead to strong performance improvements, as the learned bottlenecks help predict only the relevant state while ignoring irrelevant information.
Improving Human Motion Prediction Through Continual Learning
Jul 01, 2021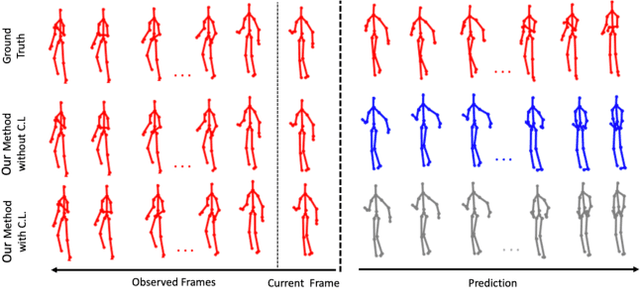

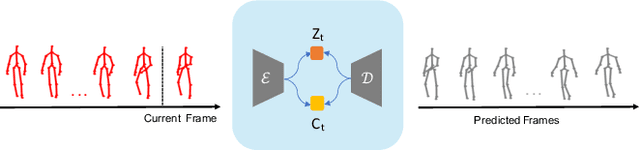
Human motion prediction is an essential component for enabling closer human-robot collaboration. The task of accurately predicting human motion is non-trivial. It is compounded by the variability of human motion, both at a skeletal level due to the varying size of humans and at a motion level due to individual movement's idiosyncrasies. These variables make it challenging for learning algorithms to obtain a general representation that is robust to the diverse spatio-temporal patterns of human motion. In this work, we propose a modular sequence learning approach that allows end-to-end training while also having the flexibility of being fine-tuned. Our approach relies on the diversity of training samples to first learn a robust representation, which can then be fine-tuned in a continual learning setup to predict the motion of new subjects. We evaluated the proposed approach by comparing its performance against state-of-the-art baselines. The results suggest that our approach outperforms other methods over all the evaluated temporal horizons, using a small amount of data for fine-tuning. The improved performance of our approach opens up the possibility of using continual learning for personalized and reliable motion prediction.