 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Stop Taking Tokenizers for Granted: They Are Core Design Decisions in Large Language Models
Jan 19, 2026Tokenization underlies every large language model, yet it remains an under-theorized and inconsistently designed component. Common subword approaches such as Byte Pair Encoding (BPE) offer scalability but often misalign with linguistic structure, amplify bias, and waste capacity across languages and domains. This paper reframes tokenization as a core modeling decision rather than a preprocessing step. We argue for a context-aware framework that integrates tokenizer and model co-design, guided by linguistic, domain, and deployment considerations. Standardized evaluation and transparent reporting are essential to make tokenization choices accountable and comparable. Treating tokenization as a core design problem, not a technical afterthought, can yield language technologies that are fairer, more efficient, and more adaptable.
MathMist: A Parallel Multilingual Benchmark Dataset for Mathematical Problem Solving and Reasoning
Oct 16, 2025Mathematical reasoning remains one of the most challenging domains for large language models (LLMs), requiring not only linguistic understanding but also structured logical deduction and numerical precision. While recent LLMs demonstrate strong general-purpose reasoning abilities, their mathematical competence across diverse languages remains underexplored. Existing benchmarks primarily focus on English or a narrow subset of high-resource languages, leaving significant gaps in assessing multilingual and cross-lingual mathematical reasoning. To address this, we introduce MathMist, a parallel multilingual benchmark for mathematical problem solving and reasoning. MathMist encompasses over 21K aligned question-answer pairs across seven languages, representing a balanced coverage of high-, medium-, and low-resource linguistic settings. The dataset captures linguistic variety, multiple types of problem settings, and solution synthesizing capabilities. We systematically evaluate a diverse suite of models, including open-source small and medium LLMs, proprietary systems, and multilingual-reasoning-focused models, under zero-shot, chain-of-thought (CoT), and code-switched reasoning paradigms. Our results reveal persistent deficiencies in LLMs' ability to perform consistent and interpretable mathematical reasoning across languages, with pronounced degradation in low-resource settings. All the codes and data are available at GitHub: https://github.com/mahbubhimel/MathMist
Ready to Translate, Not to Represent? Bias and Performance Gaps in Multilingual LLMs Across Language Families and Domains
Oct 09, 2025The rise of Large Language Models (LLMs) has redefined Machine Translation (MT), enabling context-aware and fluent translations across hundreds of languages and textual domains. Despite their remarkable capabilities, LLMs often exhibit uneven performance across language families and specialized domains. Moreover, recent evidence reveals that these models can encode and amplify different biases present in their training data, posing serious concerns for fairness, especially in low-resource languages. To address these gaps, we introduce Translation Tangles, a unified framework and dataset for evaluating the translation quality and fairness of open-source LLMs. Our approach benchmarks 24 bidirectional language pairs across multiple domains using different metrics. We further propose a hybrid bias detection pipeline that integrates rule-based heuristics, semantic similarity filtering, and LLM-based validation. We also introduce a high-quality, bias-annotated dataset based on human evaluations of 1,439 translation-reference pairs. The code and dataset are accessible on GitHub: https://github.com/faiyazabdullah/TranslationTangles
GenAI Content Detection Task 2: AI vs. Human -- Academic Essay Authenticity Challenge
Dec 24, 2024



This paper presents a comprehensive overview of the first edition of the Academic Essay Authenticity Challenge, organized as part of the GenAI Content Detection shared tasks collocated with COLING 2025. This challenge focuses on detecting machine-generated vs. human-authored essays for academic purposes. The task is defined as follows: "Given an essay, identify whether it is generated by a machine or authored by a human.'' The challenge involves two languages: English and Arabic. During the evaluation phase, 25 teams submitted systems for English and 21 teams for Arabic, reflecting substantial interest in the task. Finally, seven teams submitted system description papers. The majority of submissions utilized fine-tuned transformer-based models, with one team employing Large Language Models (LLMs) such as Llama 2 and Llama 3. This paper outlines the task formulation, details the dataset construction process, and explains the evaluation framework. Additionally, we present a summary of the approaches adopted by participating teams. Nearly all submitted systems outperformed the n-gram-based baseline, with the top-performing systems achieving F1 scores exceeding 0.98 for both languages, indicating significant progress in the detection of machine-generated text.
DM-Codec: Distilling Multimodal Representations for Speech Tokenization
Oct 19, 2024



Recent advancements in speech-language models have yielded significant improvements in speech tokenization and synthesis. However, effectively mapping the complex, multidimensional attributes of speech into discrete tokens remains challenging. This process demands acoustic, semantic, and contextual information for precise speech representations. Existing speech representations generally fall into two categories: acoustic tokens from audio codecs and semantic tokens from speech self-supervised learning models. Although recent efforts have unified acoustic and semantic tokens for improved performance, they overlook the crucial role of contextual representation in comprehensive speech modeling. Our empirical investigations reveal that the absence of contextual representations results in elevated Word Error Rate (WER) and Word Information Lost (WIL) scores in speech transcriptions. To address these limitations, we propose two novel distillation approaches: (1) a language model (LM)-guided distillation method that incorporates contextual information, and (2) a combined LM and self-supervised speech model (SM)-guided distillation technique that effectively distills multimodal representations (acoustic, semantic, and contextual) into a comprehensive speech tokenizer, termed DM-Codec. The DM-Codec architecture adopts a streamlined encoder-decoder framework with a Residual Vector Quantizer (RVQ) and incorporates the LM and SM during the training process. Experiments show DM-Codec significantly outperforms state-of-the-art speech tokenization models, reducing WER by up to 13.46%, WIL by 9.82%, and improving speech quality by 5.84% and intelligibility by 1.85% on the LibriSpeech benchmark dataset. The code, samples, and model checkpoints are available at https://github.com/mubtasimahasan/DM-Codec.
Data Selection Curriculum for Neural Machine Translation
Mar 25, 2022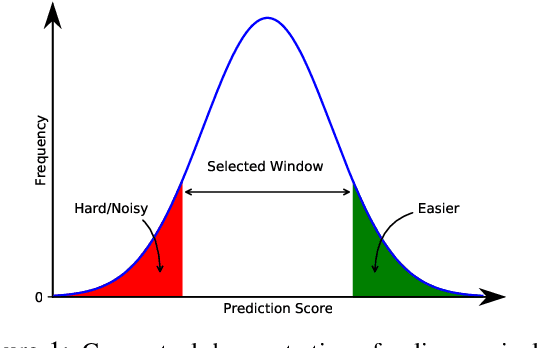
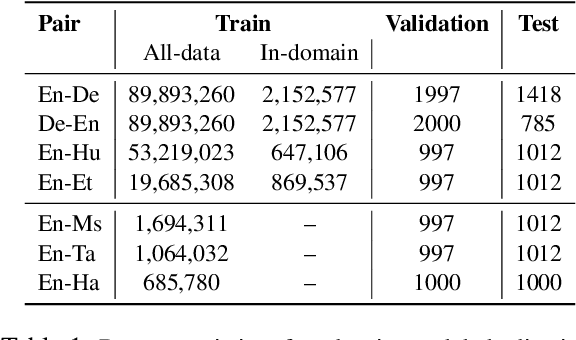
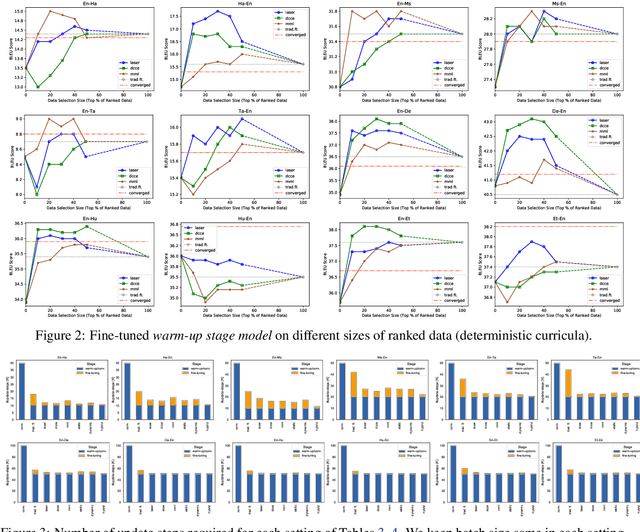
Neural Machine Translation (NMT) models are typically trained on heterogeneous data that are concatenated and randomly shuffled. However, not all of the training data are equally useful to the model. Curriculum training aims to present the data to the NMT models in a meaningful order. In this work, we introduce a two-stage curriculum training framework for NMT where we fine-tune a base NMT model on subsets of data, selected by both deterministic scoring using pre-trained methods and online scoring that considers prediction scores of the emerging NMT model. Through comprehensive experiments on six language pairs comprising low- and high-resource languages from WMT'21, we have shown that our curriculum strategies consistently demonstrate better quality (up to +2.2 BLEU improvement) and faster convergence (approximately 50% fewer updates).
AUGVIC: Exploiting BiText Vicinity for Low-Resource NMT
Jun 09, 2021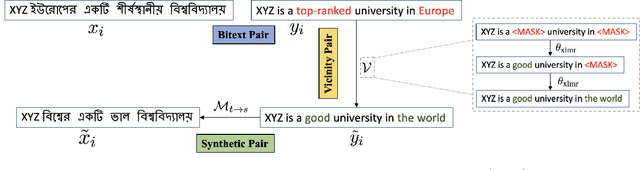

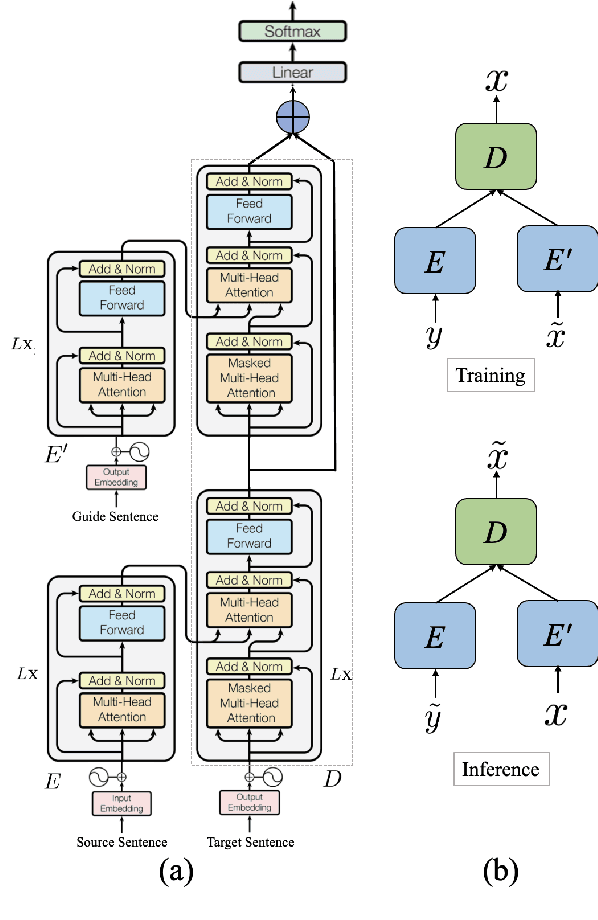
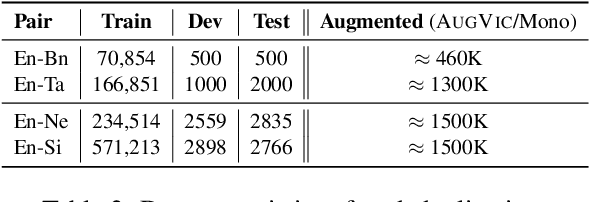
The success of Neural Machine Translation (NMT) largely depends on the availability of large bitext training corpora. Due to the lack of such large corpora in low-resource language pairs, NMT systems often exhibit poor performance. Extra relevant monolingual data often helps, but acquiring it could be quite expensive, especially for low-resource languages. Moreover, domain mismatch between bitext (train/test) and monolingual data might degrade the performance. To alleviate such issues, we propose AUGVIC, a novel data augmentation framework for low-resource NMT which exploits the vicinal samples of the given bitext without using any extra monolingual data explicitly. It can diversify the in-domain bitext data with finer level control. Through extensive experiments on four low-resource language pairs comprising data from different domains, we have shown that our method is comparable to the traditional back-translation that uses extra in-domain monolingual data. When we combine the synthetic parallel data generated from AUGVIC with the ones from the extra monolingual data, we achieve further improvements. We show that AUGVIC helps to attenuate the discrepancies between relevant and distant-domain monolingual data in traditional back-translation. To understand the contributions of different components of AUGVIC, we perform an in-depth framework analysis.
CohEval: Benchmarking Coherence Models
Apr 30, 2020
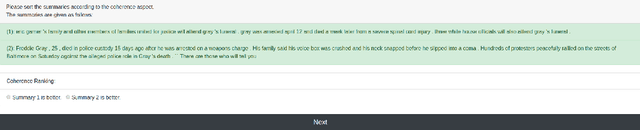
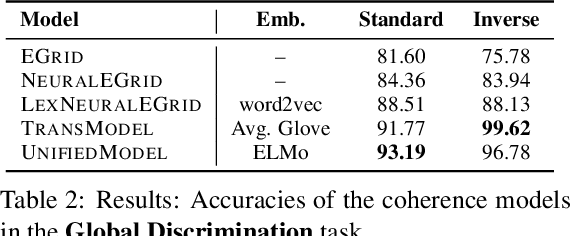
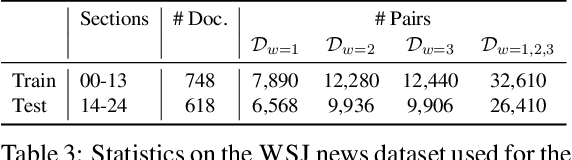
Although coherence modeling has come a long way in developing novel models, their evaluation on downstream applications has largely been neglected. With the advancements made by neural approaches in applications such as machine translation, text summarization and dialogue systems, the need for standard coherence evaluation is now more crucial than ever. In this paper, we propose to benchmark coherence models on a number of synthetic and downstream tasks. In particular, we evaluate well-known traditional and neural coherence models on sentence ordering tasks, and also on three downstream applications including coherence evaluation for machine translation, summarization and next utterance prediction. We also show model produced rankings for pre-trained language model outputs as another use-case. Our results demonstrate a weak correlation between the model performances in the synthetic tasks and the downstream applications, motivating alternate evaluation methods for coherence models. This work has led us to create a leaderboard to foster further research in coherence modeling.
LNMap: Departures from Isomorphic Assumption in Bilingual Lexicon Induction Through Non-Linear Mapping in Latent Space
Apr 28, 2020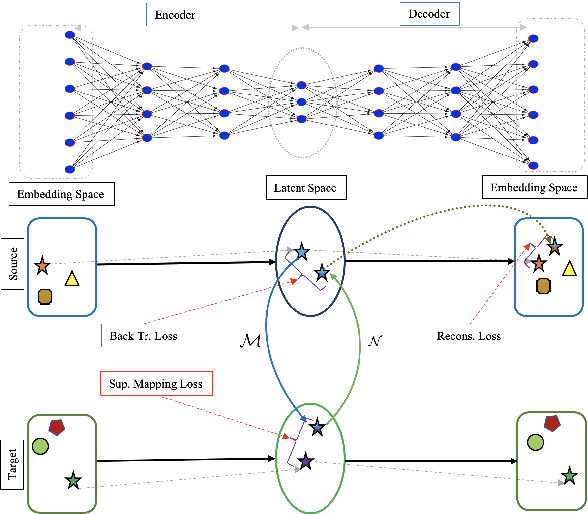
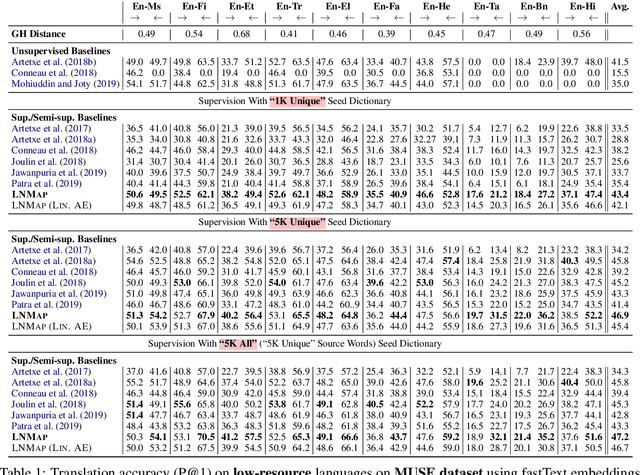
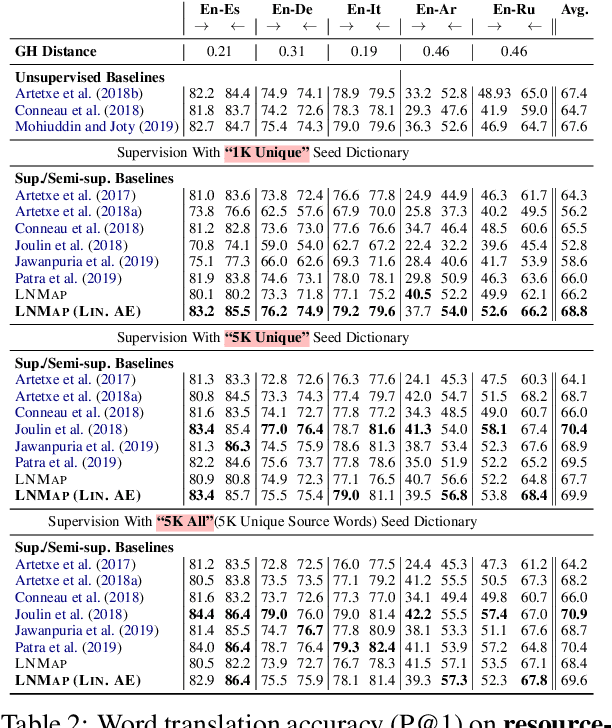
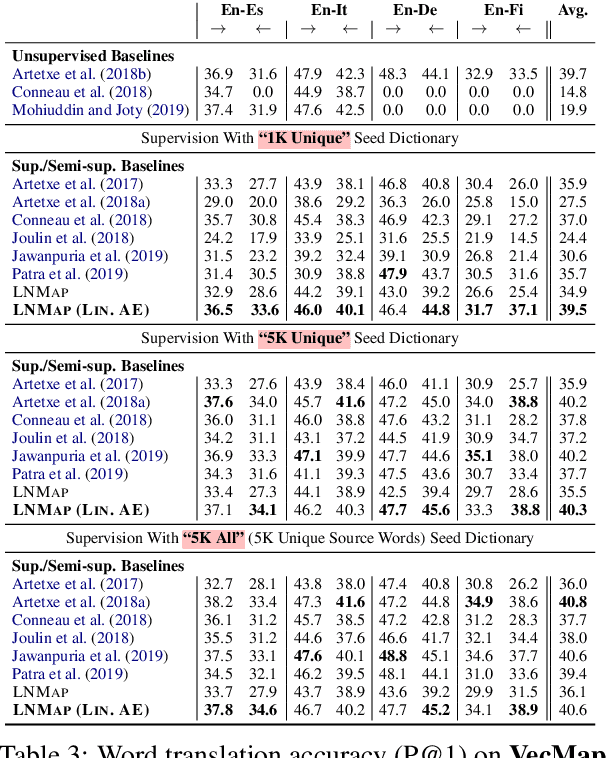
Most of the successful and predominant methods for bilingual lexicon induction (BLI) are mapping-based, where a linear mapping function is learned with the assumption that the word embedding spaces of different languages exhibit similar geometric structures (i.e., approximately isomorphic). However, several recent studies have criticized this simplified assumption showing that it does not hold in general even for closely related languages. In this work, we propose a novel semi-supervised method to learn cross-lingual word embeddings for BLI. Our model is independent of the isomorphic assumption and uses nonlinear mapping in the latent space of two independently trained auto-encoders. Through extensive experiments on fifteen (15) different language pairs (in both directions) comprising resource-rich and low-resource languages from two different datasets, we demonstrate that our method outperforms existing models by a good margin. Ablation studies show the importance of different model components and the necessity of non-linear mapping.