 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRAND: Sequence-Conditioned Transport for Single-Cell Perturbations
Feb 10, 2026Predicting how genetic perturbations change cellular state is a core problem for building controllable models of gene regulation. Perturbations targeting the same gene can produce different transcriptional responses depending on their genomic locus, including different transcription start sites and regulatory elements. Gene-level perturbation models collapse these distinct interventions into the same representation. We introduce STRAND, a generative model that predicts single-cell transcriptional responses by conditioning on regulatory DNA sequence. STRAND represents a perturbation by encoding the sequence at its genomic locus and uses this representation to parameterize a conditional transport process from control to perturbed cell states. Representing perturbations by sequence, rather than by a fixed set of gene identifiers, supports zero-shot inference at loci not seen during training and expands inference-time genomic coverage from ~1.5% for gene-level single-cell foundation models to ~95% of the genome. We evaluate STRAND on CRISPR perturbation datasets in K562, Jurkat, and RPE1 cells. STRAND improves discrimination scores by up to 33% in low-sample regimes, achieves the best average rank on unseen gene perturbation benchmarks, and improves transfer to novel cell lines by up to 0.14 in Pearson correlation. Ablations isolate the gains to sequence conditioning and transport, and case studies show that STRAND resolves functionally alternative transcription start sites missed by gene-level models.
On the Role of Discreteness in Diffusion LLMs
Dec 27, 2025Diffusion models offer appealing properties for language generation, such as parallel decoding and iterative refinement, but the discrete and highly structured nature of text challenges the direct application of diffusion principles. In this paper, we revisit diffusion language modeling from the view of diffusion process and language modeling, and outline five properties that separate diffusion mechanics from language-specific requirements. We first categorize existing approaches into continuous diffusion in embedding space and discrete diffusion over tokens. We then show that each satisfies only part of the five essential properties and therefore reflects a structural trade-off. Through analyses of recent large diffusion language models, we identify two central issues: (i) uniform corruption does not respect how information is distributed across positions, and (ii) token-wise marginal training cannot capture multi-token dependencies during parallel decoding. These observations motivate diffusion processes that align more closely with the structure of text, and encourage future work toward more coherent diffusion language models.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
May 01, 2025The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.
Dynamic Scheduled Sampling with Imitation Loss for Neural Text Generation
Jan 31, 2023State-of-the-art neural text generation models are typically trained to maximize the likelihood of each token in the ground-truth sequence conditioned on the previous target tokens. However, during inference, the model needs to make a prediction conditioned on the tokens generated by itself. This train-test discrepancy is referred to as exposure bias. Scheduled sampling is a curriculum learning strategy that gradually exposes the model to its own predictions during training to mitigate this bias. Most of the proposed approaches design a scheduler based on training steps, which generally requires careful tuning depending on the training setup. In this work, we introduce Dynamic Scheduled Sampling with Imitation Loss (DySI), which maintains the schedule based solely on the training time accuracy, while enhancing the curriculum learning by introducing an imitation loss, which attempts to make the behavior of the decoder indistinguishable from the behavior of a teacher-forced decoder. DySI is universally applicable across training setups with minimal tuning. Extensive experiments and analysis show that DySI not only achieves notable improvements on standard machine translation benchmarks, but also significantly improves the robustness of other text generation models.
Chart-to-Text: A Large-Scale Benchmark for Chart Summarization
Mar 21, 2022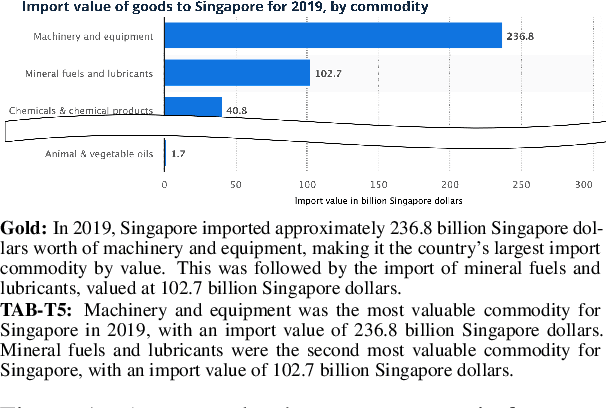
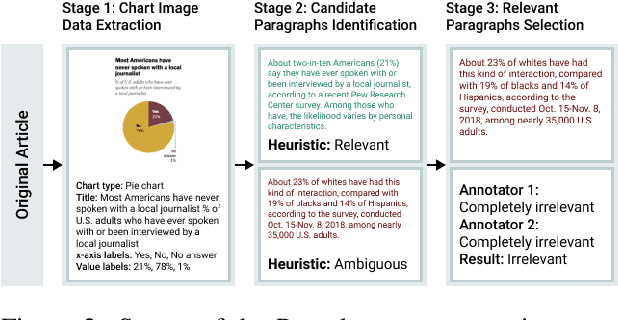
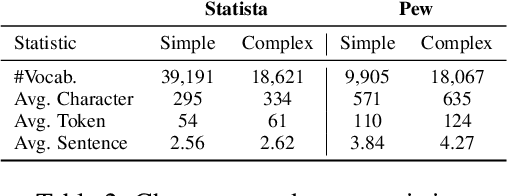

Charts are commonly used for exploring data and communicating insights. Generating natural language summaries from charts can be very helpful for people in inferring key insights that would otherwise require a lot of cognitive and perceptual efforts. We present Chart-to-text, a large-scale benchmark with two datasets and a total of 44,096 charts covering a wide range of topics and chart types. We explain the dataset construction process and analyze the datasets. We also introduce a number of state-of-the-art neural models as baselines that utilize image captioning and data-to-text generation techniques to tackle two problem variations: one assumes the underlying data table of the chart is available while the other needs to extract data from chart images. Our analysis with automatic and human evaluation shows that while our best models usually generate fluent summaries and yield reasonable BLEU scores, they also suffer from hallucinations and factual errors as well as difficulties in correctly explaining complex patterns and trends in charts.
Rethinking Self-Supervision Objectives for Generalizable Coherence Modeling
Oct 14, 2021
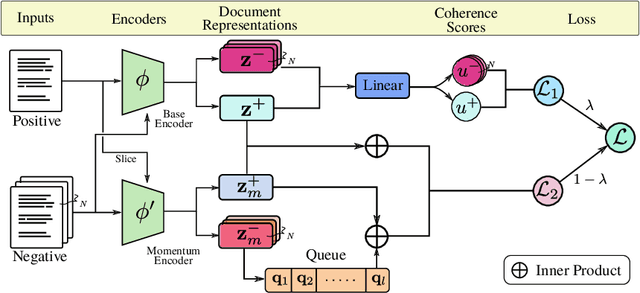
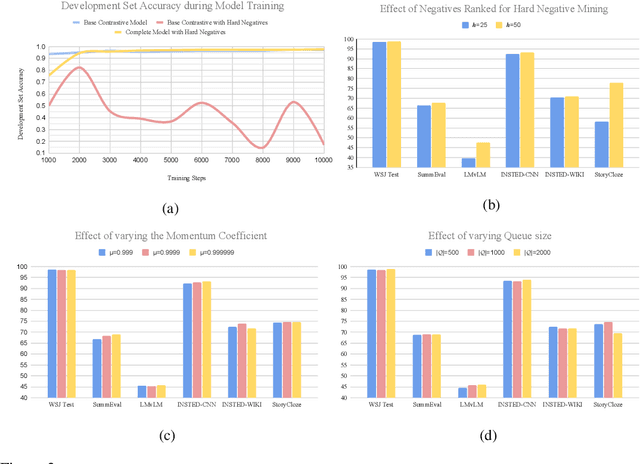

Although large-scale pre-trained neural models have shown impressive performances in a variety of tasks, their ability to generate coherent text that appropriately models discourse phenomena is harder to evaluate and less understood. Given the claims of improved text generation quality across various systems, we consider the coherence evaluation of machine generated text to be one of the principal applications of coherence models that needs to be investigated. We explore training data and self-supervision objectives that result in a model that generalizes well across tasks and can be used off-the-shelf to perform such evaluations. Prior work in neural coherence modeling has primarily focused on devising new architectures, and trained the model to distinguish coherent and incoherent text through pairwise self-supervision on the permuted documents task. We instead use a basic model architecture and show significant improvements over state of the art within the same training regime. We then design a harder self-supervision objective by increasing the ratio of negative samples within a contrastive learning setup, and enhance the model further through automatic hard negative mining coupled with a large global negative queue encoded by a momentum encoder. We show empirically that increasing the density of negative samples improves the basic model, and using a global negative queue further improves and stabilizes the model while training with hard negative samples. We evaluate the coherence model on task-independent test sets that resemble real-world use cases and show significant improvements in coherence evaluations of downstream applications.
Perturbation Theory-Aided Learned Digital Back-Propagation Scheme for Optical Fiber Nonlinearity Compensation
Oct 11, 2021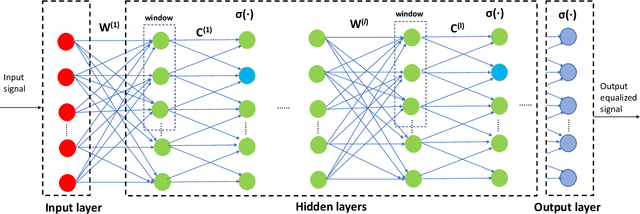

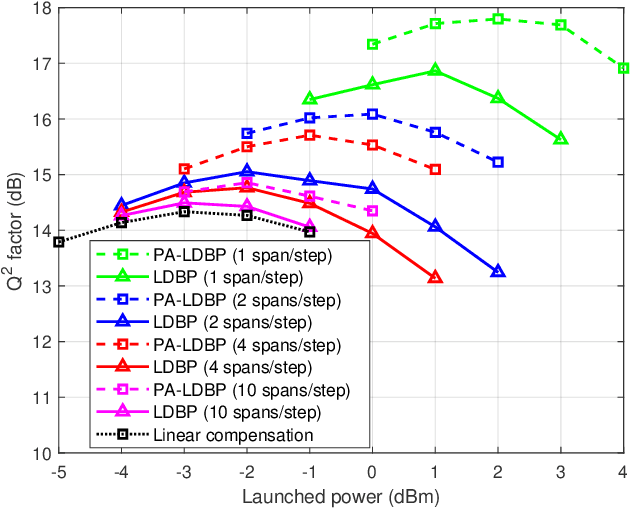
Derived from the regular perturbation treatment of the nonlinear Schrodinger equation, a machine learning-based scheme to mitigate the intra-channel optical fiber nonlinearity is proposed. Referred to as the perturbation theory-aided (PA) learned digital back-propagation (LDBP), the proposed scheme constructs a deep neural network (DNN) in a way similar to the split-step Fourier method: linear and nonlinear operations alternate. Inspired by the perturbation analysis, the intra-channel cross-phase modulation term is conveniently represented by matrix operations in the DNN. The introduction of this term in each nonlinear operation considerably improves the performance, as well as enables the flexibility of PA-LDBP by adjusting the numbers of spans per step. The proposed scheme is evaluated by numerical simulations of a single carrier optical fiber communication system operating at 32 Gbaud with 64-quadrature amplitude modulation and 20*80 km transmission distance. The results show that the proposed scheme achieves approximately 3.5 dB, 1.8 dB, 1.4 dB, and 0.5 dB performance gain in terms of Q2 factor over the linear compensation, when the numbers of spans per step are 1, 2, 4, and 10, respectively. Two methods are proposed to reduce the complexity of PALDBP, i.e., pruning the number of perturbation coefficients and chromatic dispersion compensation in the frequency domain for multi-span per step cases. Investigation of the performance and complexity suggests that PA-LDBP attains improved performance gains with reduced complexity when compared to LDBP in the cases of 4 and 10 spans per step.
Straight to the Gradient: Learning to Use Novel Tokens for Neural Text Generation
Jun 14, 2021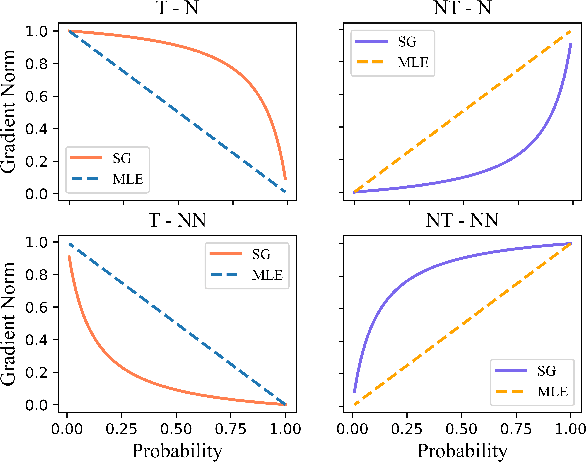

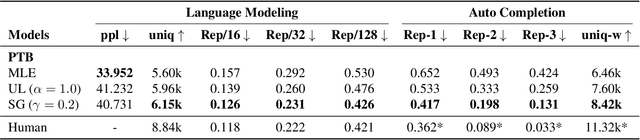
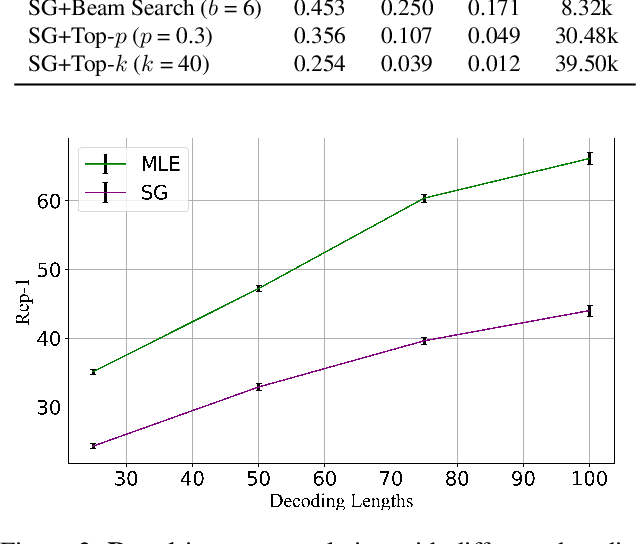
Advanced large-scale neural language models have led to significant success in many language generation tasks. However, the most commonly used training objective, Maximum Likelihood Estimation (MLE), has been shown problematic, where the trained model prefers using dull and repetitive phrases. In this work, we introduce ScaleGrad, a modification straight to the gradient of the loss function, to remedy the degeneration issue of the standard MLE objective. By directly maneuvering the gradient information, ScaleGrad makes the model learn to use novel tokens. Empirical results show the effectiveness of our method not only in open-ended generation, but also in directed generation tasks. With the simplicity in architecture, our method can serve as a general training objective that is applicable to most of the neural text generation tasks.
Graphfool: Targeted Label Adversarial Attack on Graph Embedding
Feb 24, 2021
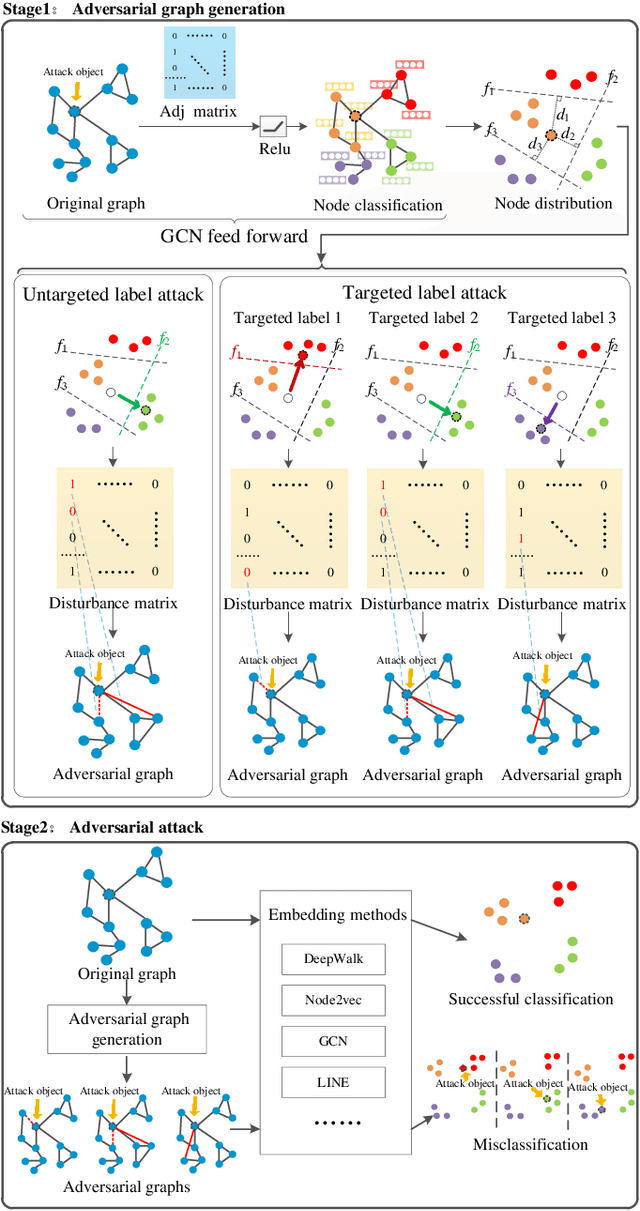
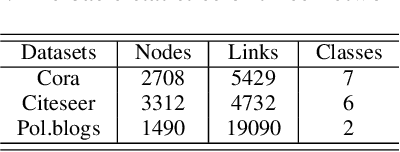
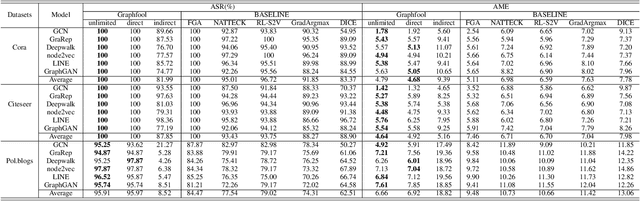
Deep learning is effective in graph analysis. It is widely applied in many related areas, such as link prediction, node classification, community detection, and graph classification etc. Graph embedding, which learns low-dimensional representations for vertices or edges in the graph, usually employs deep models to derive the embedding vector. However, these models are vulnerable. We envision that graph embedding methods based on deep models can be easily attacked using adversarial examples. Thus, in this paper, we propose Graphfool, a novel targeted label adversarial attack on graph embedding. It can generate adversarial graph to attack graph embedding methods via classifying boundary and gradient information in graph convolutional network (GCN). Specifically, we perform the following steps: 1),We first estimate the classification boundaries of different classes. 2), We calculate the minimal perturbation matrix to misclassify the attacked vertex according to the target classification boundary. 3), We modify the adjacency matrix according to the maximal absolute value of the disturbance matrix. This process is implemented iteratively. To the best of our knowledge, this is the first targeted label attack technique. The experiments on real-world graph networks demonstrate that Graphfool can derive better performance than state-of-art techniques. Compared with the second best algorithm, Graphfool can achieve an average improvement of 11.44% in attack success rate.