 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
Jan 14, 2026Deep research systems are widely used for multi-step web research, analysis, and cross-source synthesis, yet their evaluation remains challenging. Existing benchmarks often require annotation-intensive task construction, rely on static evaluation dimensions, or fail to reliably verify facts when citations are missing. To bridge these gaps, we introduce DeepResearchEval, an automated framework for deep research task construction and agentic evaluation. For task construction, we propose a persona-driven pipeline generating realistic, complex research tasks anchored in diverse user profiles, applying a two-stage filter Task Qualification and Search Necessity to retain only tasks requiring multi-source evidence integration and external retrieval. For evaluation, we propose an agentic pipeline with two components: an Adaptive Point-wise Quality Evaluation that dynamically derives task-specific evaluation dimensions, criteria, and weights conditioned on each generated task, and an Active Fact-Checking that autonomously extracts and verifies report statements via web search, even when citations are missing.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models
May 01, 2025The recent development of reasoning language models (RLMs) represents a novel evolution in large language models. In particular, the recent release of DeepSeek-R1 has generated widespread social impact and sparked enthusiasm in the research community for exploring the explicit reasoning paradigm of language models. However, the implementation details of the released models have not been fully open-sourced by DeepSeek, including DeepSeek-R1-Zero, DeepSeek-R1, and the distilled small models. As a result, many replication studies have emerged aiming to reproduce the strong performance achieved by DeepSeek-R1, reaching comparable performance through similar training procedures and fully open-source data resources. These works have investigated feasible strategies for supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR), focusing on data preparation and method design, yielding various valuable insights. In this report, we provide a summary of recent replication studies to inspire future research. We primarily focus on SFT and RLVR as two main directions, introducing the details for data construction, method design and training procedure of current replication studies. Moreover, we conclude key findings from the implementation details and experimental results reported by these studies, anticipating to inspire future research. We also discuss additional techniques of enhancing RLMs, highlighting the potential of expanding the application scope of these models, and discussing the challenges in development. By this survey, we aim to help researchers and developers of RLMs stay updated with the latest advancements, and seek to inspire new ideas to further enhance RLMs.
Finding the Sweet Spot: Preference Data Construction for Scaling Preference Optimization
Feb 24, 2025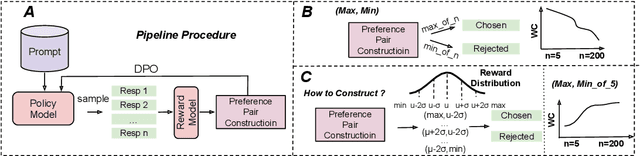
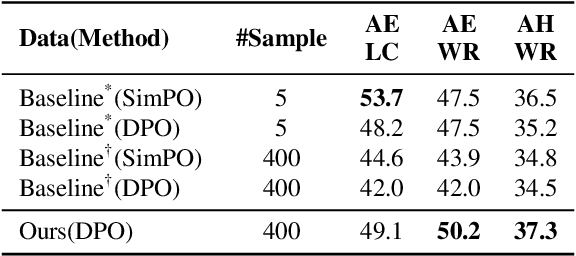
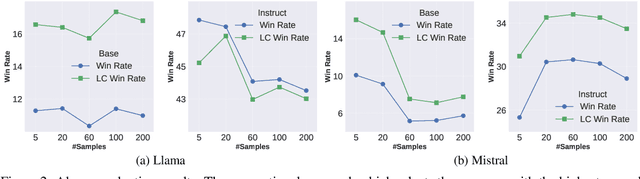
Iterative data generation and model retraining are widely used to align large language models (LLMs). It typically involves a policy model to generate on-policy responses and a reward model to guide training data selection. Direct Preference Optimization (DPO) further enhances this process by constructing preference pairs of chosen and rejected responses. In this work, we aim to \emph{scale up} the number of on-policy samples via repeated random sampling to improve alignment performance. Conventional practice selects the sample with the highest reward as chosen and the lowest as rejected for DPO. However, our experiments reveal that this strategy leads to a \emph{decline} in performance as the sample size increases. To address this, we investigate preference data construction through the lens of underlying normal distribution of sample rewards. We categorize the reward space into seven representative points and systematically explore all 21 ($C_7^2$) pairwise combinations. Through evaluations on four models using AlpacaEval 2, we find that selecting the rejected response at reward position $\mu - 2\sigma$ rather than the minimum reward, is crucial for optimal performance. We finally introduce a scalable preference data construction strategy that consistently enhances model performance as the sample scale increases.
Test-time Computing: from System-1 Thinking to System-2 Thinking
Jan 05, 2025



The remarkable performance of the o1 model in complex reasoning demonstrates that test-time computing scaling can further unlock the model's potential, enabling powerful System-2 thinking. However, there is still a lack of comprehensive surveys for test-time computing scaling. We trace the concept of test-time computing back to System-1 models. In System-1 models, test-time computing addresses distribution shifts and improves robustness and generalization through parameter updating, input modification, representation editing, and output calibration. In System-2 models, it enhances the model's reasoning ability to solve complex problems through repeated sampling, self-correction, and tree search. We organize this survey according to the trend of System-1 to System-2 thinking, highlighting the key role of test-time computing in the transition from System-1 models to weak System-2 models, and then to strong System-2 models. We also point out a few possible future directions.
Multi-Agent Sampling: Scaling Inference Compute for Data Synthesis with Tree Search-Based Agentic Collaboration
Dec 22, 2024



Scaling laws for inference compute in multi-agent systems remain under-explored compared to single-agent scenarios. This work aims to bridge this gap by investigating the problem of data synthesis through multi-agent sampling, where synthetic responses are generated by sampling from multiple distinct language models. Effective model coordination is crucial for successful multi-agent collaboration. Unlike previous approaches that rely on fixed workflows, we treat model coordination as a multi-step decision-making process, optimizing generation structures dynamically for each input question. We introduce Tree Search-based Orchestrated Agents~(TOA), where the workflow evolves iteratively during the sequential sampling process. To achieve this, we leverage Monte Carlo Tree Search (MCTS), integrating a reward model to provide real-time feedback and accelerate exploration. Our experiments on alignment, machine translation, and mathematical reasoning demonstrate that multi-agent sampling significantly outperforms single-agent sampling as inference compute scales. TOA is the most compute-efficient approach, achieving SOTA performance on WMT and a 71.8\% LC win rate on AlpacaEval. Moreover, fine-tuning with our synthesized alignment data surpasses strong preference learning methods on challenging benchmarks such as Arena-Hard and AlpacaEval.
Self-Judge: Selective Instruction Following with Alignment Self-Evaluation
Sep 02, 2024Pre-trained large language models (LLMs) can be tailored to adhere to human instructions through instruction tuning. However, due to shifts in the distribution of test-time data, they may not always execute instructions accurately, potentially generating factual errors or misaligned content when acting as chat assistants. To enhance the reliability of LLMs in following instructions, we propose the study of selective instruction following, whereby the system declines to execute instructions if the anticipated response quality is low. We train judge models that can predict numerical quality scores for model responses. To address data scarcity, we introduce Self-J, a novel self-training framework for developing judge models without needing human-annotated quality scores. Our method leverages the model's inherent self-evaluation capability to extract information about response quality from labeled instruction-tuning data. It incorporates a gold reference answer to facilitate self-evaluation and recalibrates by assessing the semantic similarity between the response sample and the gold reference. During the training phase, we implement self-distillation as a regularization technique to enhance the capability of reference-free estimation. To validate alignment evaluation on general instruction-following tasks, we collect large-scale high-quality instructions from Hugging Face for model training and evaluation. Extensive experiments on five open-source models show that our method correlates much more with GPT-4 than strong baselines, e.g., supervised models distilled from GPT-4 and GPT-3.5-turbo. Our analysis shows our model's strong generalization across domains. Additionally, our judge models serve as good reward models, e.g., boosting WizardLM-13B-V1.2 from 89.17 to 92.48 and from 12.03 to 15.90 in version v1 and v2 of AlpacaEval respectively using best-of-32 sampling with our judge models.
Preference-Guided Reflective Sampling for Aligning Language Models
Aug 22, 2024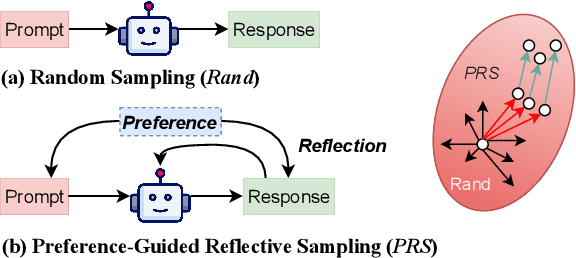


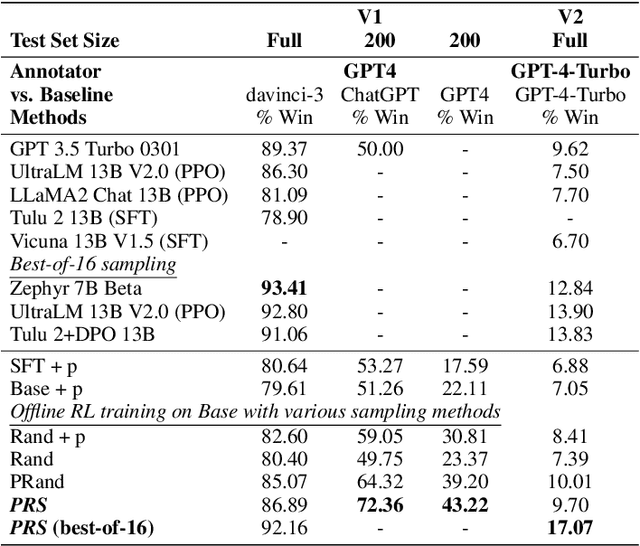
Large language models (LLMs) are aligned with human preferences by reinforcement learning from human feedback (RLHF). Effective data sampling is crucial for RLHF, as it determines the efficiency of model training, ensuring that models learn from the informative samples. To achieve better data generation, we propose a new sampling method called Preference-Guided Reflective Sampling (PRS). PRS frames the response generation as an optimization process to the explicitly specified user preference described in natural language. It employs a tree-based generation framework to enable an efficient sampling process, which guides the direction of generation through preference and better explores the sampling space with adaptive self-refinement. Notably, PRS can align LLMs to diverse preferences. We study preference-controlled text generation for instruction following and keyword-focused document summarization. Our findings indicate that PRS, across different LLM policies, generates training data with much higher rewards than strong baselines. PRS also excels in post-RL training.
On the Robustness of Question Rewriting Systems to Questions of Varying Hardness
Nov 12, 2023



In conversational question answering (CQA), the task of question rewriting~(QR) in context aims to rewrite a context-dependent question into an equivalent self-contained question that gives the same answer. In this paper, we are interested in the robustness of a QR system to questions varying in rewriting hardness or difficulty. Since there is a lack of questions classified based on their rewriting hardness, we first propose a heuristic method to automatically classify questions into subsets of varying hardness, by measuring the discrepancy between a question and its rewrite. To find out what makes questions hard or easy for rewriting, we then conduct a human evaluation to annotate the rewriting hardness of questions. Finally, to enhance the robustness of QR systems to questions of varying hardness, we propose a novel learning framework for QR that first trains a QR model independently on each subset of questions of a certain level of hardness, then combines these QR models as one joint model for inference. Experimental results on two datasets show that our framework improves the overall performance compared to the baselines.
Multi-Source Test-Time Adaptation as Dueling Bandits for Extractive Question Answering
Jun 11, 2023In this work, we study multi-source test-time model adaptation from user feedback, where K distinct models are established for adaptation. To allow efficient adaptation, we cast the problem as a stochastic decision-making process, aiming to determine the best adapted model after adaptation. We discuss two frameworks: multi-armed bandit learning and multi-armed dueling bandits. Compared to multi-armed bandit learning, the dueling framework allows pairwise collaboration among K models, which is solved by a novel method named Co-UCB proposed in this work. Experiments on six datasets of extractive question answering (QA) show that the dueling framework using Co-UCB is more effective than other strong baselines for our studied problem.